Bei Niederdeutsch handelt es sich nicht um eine bestimmte Sprache, sondern um die Bezeichnung eines Dialektgebietes, in dem sich die norddeutschen Mundarten untereinander und gegen die angrenzenden mitteldeutschen, süddeutschen sowie niederländischen Varietäten abgrenzen. Niederdeutsche Mundarten entstammen dem Sächsischen und sind dementsprechend den westgermanischen Sprachen zuzuordnen (vgl. Möller 1997). Sie werden vornehmlich in 9 Bundesländern gesprochen: flächendeckend in Bremen, Hamburg, Mecklenburg-Vorpommern, Niedersachsen und Schleswig-Holstein sowie jeweils in den nördlichen Regionen von Brandenburg, Nordrhein-Westfalen und Sachsen-Anhalt und in einem kleinen Gebiet Hessens. Niederdeutsch wird in kleineren Wohnorten häufiger gesprochen als in solchen mit hoher Einwohnerzahl. Darüber hinaus ist Niederdeutsch vor allem ein Kommunikationsmittel älterer Menschen. Beides, die Konzentration des Niederdeutschen auf ländliche Regionen und die geringe Zahl aktiver Sprecher in den jüngeren Generationen, lassen den Fortbestand des Niederdeutschen auf längere Sicht fraglich erscheinen. Bereits jetzt ist die Gefährdung der niederdeutschen Mundarten deutlich an der Entwicklung der geschätzten Sprecherzahlen abzulesen. Während Möller (1997: 37) noch von "gut und gerne 10 Millionen Menschen" mit guten bis sehr guten Niederdeutschkenntnissen spricht, gaben in einer repräsentativen Umfrage aus dem Jahr 2007 nur noch etwa 2.6 Millionen Menschen im niederdeutschen Sprachraum an, gut oder sehr gut Niederdeutsch zu sprechen. Dies entspricht einem Bevölkerungsanteil von 14% in den genannten Gebieten (vgl. Goltz 2009). Demzufolge ist Niederdeutsch inzwischen von der EU in die Gruppe der Regional- und Minderheitensprachen aufgenommen worden1.
Was die Binneneinteilung des niederdeutschen Sprachraumes anlangt, so orientieren sich Arbeiten wie etwa die von Stellmacher (2005), Schröder (2004) und Braak (1956) an der frühen Strukturierung von Foerste (1957). Hiernach sind mindestens drei sich nach unten auffächernde Ebenen zu unterscheiden, die als Dialekträume, Dialektverbände und schließlich als Landschaftsdialekte bezeichnet werden. Einteilungsversuche innerhalb dieser Ebenen fußen in den genannten Arbeiten auf Vergleichen zwischen einem oder mehreren Einzelmerkmalen der niederdeutschen Mundarten, zum Beispiel auf der Entwicklung der mittelniederdeutschen mittleren Langvokale, der Form von Affixen oder der Aussprache von Konsonanten wie dem /g/, das im schleswigschen Raum abweichend zu seinen Nachbarräumen als Frikativ realisiert wird. Der niederdeutsche Sprachraum lässt sich in zwei große Dialekträume untergliedern: Westniederdeutsch und Ostniederdeutsch. Nach Speyer (2010: 114) folgt die Grenze zwischen diesen Dialekträumen "der Elbe von Merseburg bis Bardowiek (nördlich von Lüneburg), biegt dann nach Norden und verläuft gradlinig bis nach Kiel." Als differenzierendes Merkmal wird die Pluralbildung der Verbformen genannt, die im Westen auf <-et> und im Osten auf <-en> erfolgt (vgl. 'n/t-Linie'). Das Westniederdeutsche ist weitergehend in drei Dialektverbände unterteilt: das Nordniedersächsische, das Westfälische und das Ostfälische. Zum Ostniederdeutschen gehören die Dialektverbände Mecklenburgisch-Vorpommersch, Brandenburgisch, Mittelpommersch, Ostpommersch und Niederpreußisch.
Auf der Ebene der Landschaftsdialekte weichen die heutigen Binneneinteilungen an verschiedenen Stellen voneinander ab. Beispielsweise betonte Horn (1984: 98) mit Blick auf Dithmarschen noch "dass der Holsteinische Niederelberaum keine einheitliche Sprachlandschaft ist [und] dass man sich fragt, ob sich alles durch den Oberbegriff 'Holsteinisch' zusammenfassen lässt." Bereits Foerste (1957) wies auf die Sonderstellung des Dithmarscher Niederdeutsch hin. Dennoch wird Dithmarscher Niederdeutsch in jüngeren Arbeiten wie der von Stellmacher (2005) zum holsteinischen Landschaftsdialekt gerechnet. Folglich beschränkt sich die Differenzierung im westniederdeutschen Dialektverand des Nordniedersächsischen auf die 6 Landschaftsdialekte Ostfriesisch, Emsländisch, Oldenburgisch, Nordhannoversch, Holsteinisch und Schleswigsch. Im ostniederdeutschen Raum finden sich abweichende Einteilungen für die Landschaftsdialekte des Mecklenburgisch-Vorpommerschen.
Das Wissen um Abweichungen benachbarter Dialekte ist in jedem Dialektgebiet vorhanden. Unterschiedlich ist indes, auf welchen klanglichen und/oder strukturellen Aspekten sich dieses Wissen gründet. Was das Niederdeutsche Dialektgebiet anlangt, so stellt Bargstedt (2008: 185) heraus: "Wenn sich meine Großmutter und die Großmutter meiner Frau treffen, dann sprechen sie eher Hochdeutsch miteinander. [...] ihre Muttersprache ist Elbmarschen-Platt. Nur eben nicht dasselbe. Wie oft muss ich mir anhören: "Ach da im Alten Land, da 'hürt' und 'führt' se ja." Bei uns heißt das nämlich 'hört' und 'föhrt'. Und nur das ist 'richtig'". In Bargstedts kurzer Anekdote sind zwei wichtige Implikationen enthalten. Erstens zeichnen sich die Mundarten des Niederdeutschen durch spezifische vokalische Eigenschaften aus, und zweitens sind diese vokalischen Charakteristika so salient, dass sie im metalinguistischen Bewusstsein der Mundartsprecherinnen und -sprecher einen hohen Stellenwert einnehmen und zur Identifikation mit der jeweiligen Mundart beitragen. Hierzu passt auch die Ansicht von Panzer und Thümmel (1971: 46), wonach "Unterschiede im Konsonantismus innerhalb des Nd. [= Niederdeutschen], wie das Material zeigt, seltener und geringfügiger als im Vokalismus" sind.
Trotz der zahlreichen, seit langem bekannten Hinweise auf die Relevanz der Vokale ist unser Wissen über deren genaue phonetische Ausprägung in den einzelnen niederdeutschen Mundarten immer noch sehr lückenhaft. Vokalische Beschreibungen sind – sofern vorhanden – zum Teil recht alt oder aber oberflächlich impressionistisch, exemplarisch bzw. nur indirekt aus orthographischen Transliterationen gesprochener Sprache abgeleitet. Dies ist auch dem in erster Linie phonematischen Blickwinkel der Beschreibungen geschuldet, in dem tiefergehende phonetische Details und allophonische Variationen allenfalls am Rande als Mittel zum Zweck Beachtung finden. Panzer und Thümmel (1971: 55), die anhand von etwa 250 Einzelstudien den Versuch unternahmen, die niederdeutschen Mundarten bezüglich ihres Vokalismus zu vergleichen und zu gruppieren, bringen das Problem solcher kontrastiver Analysen auf den Punkt: "Leider stehen uns nur in ganz wenigen Fällen Arbeiten zur Verfügung, in denen außer der historischen Beschreibung gleichzeitig eine systematische synchrone Beschreibung des Phonemsystems gegeben wird. Deshalb sind wir in den meisten Fällen gezwungen, aus der Schreibweise und den oft beigefügten Vokaldreiecken oder sonstigen Angaben [bestimme Laute] […] zu erschließen." Des Weiteren bemerken Panzer und Thümmel, dass zwar häufig der Versuch unternommen wurde, mittels speziell auf den Vokalismus zugeschnittener Transkriptionssysteme die Präzision der impressionistischen Beschreibungen zu erhöhen (z. B. über Varianten von "Teuthonista", Lenz 1900; Wiesinger 1964, 1970). Allerdings ist die dabei entstehende "verwirrende Vielfalt" an unterschiedlichen Indizierungen "für einen Vergleich denkbar unpraktisch" (Panzer/Thümmel 1971: 47; vgl. auch Heike/Schindler 1970).
Abgesehen vom Zwirner-Korpus und der daran vorgenommenen Prosodie- und Quantitätsforschung (vgl. Zwirner u. a. 1956), gibt es erst seit den 1970er Jahren ein paar genauere Beschreibungen der niederdeutschen Vokalrealisierungen auf der Basis von Tonbandaufnahmen. Die Möglichkeit, mittels Tonbändern vergleichsweise einfach auswertbare Aufnahmen im Feld zu machen, war zudem der Ausgangspunkt erster experimental-phonetischer Arbeiten anhand akustischer Messungen. Obwohl nicht zum Niederdeutschen, sondern zum Schlesischen durchgeführt, zeigt die dialektvergleichende Studie von Heike und Schindler (1970), wie wichtig prinzipiell die Ergänzung der ohrenphonetischen durch akustische Analysen ist. Bei ohrenphonetischen Transkriptionen unterliegt das Lautmaterial bereits bei der Datenerhebung einer Interpretation durch den Bearbeiter und einer Kategorialisierung durch das Transkriptionssystem. Es entstehen Fehler. Heike und Schindler stellen im Rahmen systematischer Transkriptionstests fest, dass die häufigsten Fehler für Vokale entlang des Öffnungsgrades und des Grades der Diphthongierung passieren. Wenn nun, wie im Falle ihrer schlesischen Studie, die Unterschiede zwischen den Mundarten genau in diesen Vokalparametern liegen, dann können Mundartbeschreibungen und -differenzierungen unzureichend ausfallen oder Mundartgrenzen falsch gezogen werden. Eine rein akustische Analyse hat ebenfalls aufgrund der stark begrenzten "Mess- und Wiederholungsgenauigkeit der verwendeten Messapparatur" per se keine verlässliche Aussagekraft (Heike/Schindler 1970: 28). Erst durch die Kombination akustischer und ohrenphonetischer Analysen können Fehler wechselseitig minimiert und die phonetische Beschreibung präzisiert werden. Im vorliegenden Beitrag wird diese methodische Auffassung ebenfalls vertreten. Dementsprechend wird der niederdeutsche Vokalhintergrund zuerst akustischen und dann ohrenphonetisch analysiert. Im Anschluss werden beide Analysen zusammengeführt.
Zum Niederdeutschen wurden unter anderem für die Orte Wewelsfleth, Haßmoor, Fintel, Brarupholz und Windbergen des nordniedersächsischen Dialektverbandes akustische Analysen der Vokalproduktionen angefertigt (vgl. Hildebrandt 1963; Tödter 1982; Kohler u. a. 1986a, b). Wie für Studien dieser Zeit nicht unüblich (vgl. auch Zwirner u. a. 1956; Heike/Schindler 1970), basieren diese Analysen jedoch zum Teil nur auf den Daten einer einzelnen Gewährsperson, weswegen sich ideolektale Merkmale nur schwer von den allgemeinen Eigenschaften der Vokale des jeweiligen Landschaftsdialektes abgrenzen lassen. Darüber hinaus sind derartige akustische Analysen bis heute nicht flächendeckend durchgeführt worden. Dennoch untermauern die vorhandenen akustischen Analysen, dass niederdeutsche Wörter mit deutlich unterschiedlichen Vokalrealisierungen in den einzelnen Mundarten vorkommen können. Kohler (1986) spezifiziert diese Vokalunterschiede in seiner Metaanalyse unter anderem dahingehend, dass er sie mit drei Eigenschaften verbindet. Hierzu zählen (1) der Öffnungsgrad des Vokals sowie (2) der Grad der Diphthongierung. Der erste Aspekt zeichnet sich in den Gegensatzpaaren "hürt" und "hört" sowie "führt" und "föhrt" der eingangs zitierten Anekdote ab. Das heißt, die Vokale in "hört" und "föhrt" werden vermutlich offener produziert als in "hürt" und "führt". Was den zweiten Aspekt anlangt, so weist auch Reershemius (2004: 35) auf "ein erstaunlich großes Inventar an Diphthongen" im Niederdeutschen hin. Zudem resümiert Kohler (1986), dass es (3) vor allem die Langvokale mit mittlerem Öffnungsgrad sind, die sich zwischen den Mundarten qualitativ unterschiedlich ausprägen. Solche "Einheit der Vielfalt" zeige Stellmacher (2005: 128) zufolge, dass das Thema der niederdeutschen Sprachformen noch lange nicht erschöpft sei und daran weitergearbeitet werden müsse (vgl. bereits Stellmacher 1981).
Inwieweit wird das niederdeutsche Wort durch mundartspezifische Vokale regional koloriert? Diese Frage steht im Zentrum unserer Pilotstudie. Das primäre Ziel ist es, eingehender zu überprüfen, in welchem Umfang sich die niederdeutsche Dialektlandschaft tatsächlich in vokalischen Unterschieden widerspiegelt, und welche vokalischen Eigenschaften hierbei eine tragende Rolle spielen. Somit ist unser Interesse am niederdeutschen Vokalismus anders als in früheren Studien nicht in erster Linie phonologisch, sondern phonetisch geprägt. Vor dem in 1.2.1 skizzierten Hintergrund ist anzunehmen, dass eine Differenzierung der einzelnen Mundarten allein aufgrund vokalischer Eigenschaften in einem gewissen Ausmaß möglich ist und dass in diesem Zusammenhang das Augenmerk vor allem auf die Klasse der Langvokale und hierin auf die Parameter Öffnungsgrad und Grad der Diphthongierung gerichtet werden muss. Darüber hinaus ist es ein sekundäres Ziel der kontrastiven Analysen, einen kleinen, aber präziseren Einblick in das Qualitätsspektrum und die phonetischen Details der Vokale in einer Reihe von Landschaftsdialekten zu geben. Auf diese Weise soll ein Ansatzpunkt für umfassendere, phonetisch reichere Beschreibungen der Landschaftsdialekte des Niederdeutschen geschaffen werden.
Beide Zielsetzungen zusammen genommen verdeutlichen, dass es uns in dieser Pilotstudie nicht um Messungen von Dialektähnlichkeiten geht, wie sie in zahlreichen früheren Studien mit unterschiedlichen Methoden – und unter Einbeziehung ohrenphonetischer Transkriptionen – durchgeführt wurden (vgl. Herrgen u. a. 2001; Lameli 2004; Nerbonne/Siedle 2005). Unsere Herangehensweise, die nicht nur ohrenphonetische, sondern auch akustische Analysen umfasst und mit dem prüfstatistischen Verfahren der Diskriminanzanalyse verbindet, könnte jedoch zur Weiterentwicklung quantifizierender, dialektvergleichender Methoden beitragen.
Eine Gemeinsamkeit zwischen Studien zur Messung von Dialektähnlichkeiten und unserer Bestandsaufnahme und Beschreibung von vokalischen Eigenschaften und Unterschieden liegt allerdings darin, dass die Auswahl der Sprachdaten anhand der existierenden Binneneinteilungen der Landschaftsdialekte vorgenommen wurde, wodurch die Ergebnisse auf diese Binneneinteilungen zurückwirken können. So würden etwa vokalische Unterschiede, die innerhalb eines postulierten Landschaftsdialektes gefunden werden, auf die Notwendigkeit einer weiteren Ausdifferenzierung der Binneneinteilung hindeuten. In diesem Zusammenhang ist zum Beispiel die Frage der Zugehörigkeit der Dithmarscher Region zum Holsteiner Dialekt interessant (vgl. 1.1). In den Analysen von Kohler u. a. (1986b: 149) zeigte sich eine "für Dithmarschen typische Diphthongierung zum höheren Vokal hin", was, sofern aufgrund der kleinen Datenbasis nicht aus ideolektalen Merkmalen resultierend, bereits eine weitere Unterteilung des Holsteiner Dialektes nahe legt. Darüber hinaus können nicht nur auf linguistischer, sondern auch auf phonetischer Ebene Aspekte der Korrespondenz von geographischen und sprachlichen Merkmalen diskutiert werden. Unterscheiden sich zum Beispiel Dialekte innerhalb der west- und ostniederdeutschen Räume grundsätzlich in Bezug auf vokalische Charakteristika? Weisen Gebiete wie Schleswig-Holstein, in denen sich viele Mundarten auf vergleichsweise kleiner Fläche ballen, auch mehr Gemeinsamkeiten im Vokalismus auf? Führt die Besonderheit des friesischen Substrats in der ostfriesischen Mundart (vgl. Reershemius 2004; Bohn 2004) dazu, dass sich die ostfriesischen Vokale von denen anderer niederdeutscher Mundarten abheben? Die mit dieser Pilotstudie begonnene Forschung soll auch auf Beantwortung solcher Fragen hinarbeiten, die schon die von Zwirner und Zwriner (1936) begründete Phonometrie prägten.
Als Untersuchungsgegenstand wurde diejenige Lautklasse herangezogen, für die aufgrund des Forschungshintergrundes besonders klare dialektübergreifende Variationen zu erwarten waren: Langvokale. Als gemeinsamer Ausgangspunkt für die vergleichende Analyse der Langvokalproduktionen diente ein Set von 6 standarddeutschen Vokalkategorien, die in die 'Wenkersätze' (vgl. Wenker 1881) eingebettet waren. Die Wenkersätze wurden in Form von Spontanübersetzungen in den Mundarten der Gewährpersonen produziert. Phonetisch untersucht wurde von uns demzufolge, welche mundartspezifischen Qualitäten die 6 standarddeutschen Ausgangskategorien im Rahmen der Spontanübersetzungen annahmen. Gemäß den Zielsetzungen unserer Studie wurden Gewährspersonen beider großer Dialekträume, des West- und des Ostniederdeutschen, berücksichtigt. Darüber hinaus deckt die vergleichende Analyse mit Gewährspersonen aus den vier Bundesländern Niedersachsen, Brandenburg, Mecklenburg-Vorpommern und Schleswig-Holstein einen großen Bereich der wichtigen norddeutschen Dialektlandschaft ab. Im Bereich Schleswig-Holstein zählen sowohl Dithmarscher als auch Holsteiner zu den Gewährspersonen. Aus Niedersachsen wurden ostfriesische Gewährpersonen berücksichtigt. Weitere Einzelheiten sind in der nachfolgenden Methode ausgeführt.
Die genutzten Daten wurden im Rahmen des DFG-Projektes 'Sprachvariation in Norddeutschland' aufgenommen (vgl. http://sin.sign-lang.uni-hamburg.de/drupal/). Das Projekt wurde von Sprachwissenschaftlern 6 deutscher Universitäten durchgeführt. Ziel war die Erhebung und die Analyse der unterschiedlichen Sprachlagen zwischen hochdeutscher Standardsprache und niederdeutschen Dialekten als Ergebnis eines kontaktbedingten Sprachwandels. In diesem Zusammenhang wurden Interviews in insgesamt 18 Regionen durchgeführt, die jeweils durch Gewährspersonen aus zwei unterschiedlichen Kleinstädten mit ca. 2.000–8.000 Einwohnern repräsentiert waren. Bei den Kleinstädten handelte es sich weder um Touristenzentren noch um Pendlergemeinden oder Vorstädte von Ballungszentren. Über alle Regionen hinweg wurde eine Gesamtzahl von 144 Gewährspersonen im Alter zwischen 40–55 Jahren interviewt. Alle Gewährspersonen waren in den ausgewählten Kleinstädten geboren und dort aufgewachsen. Dennoch streute die Dialektkompetenz der Gewährspersonen von "schwach" über "mittel" (Verkehrskompetenz) bis hin zu "stark".
Die Gewährpersonen wurden in der Regel von Kontaktpersonen vor Ort (Ortsvorsteher, Vorsitzende des Landfrauenvereins, Sprecher der örtlichen Gemeinde) vorgeschlagen und telefonisch oder schriftliche kontaktiert. Wenn die Gewährspersonen die zuvor genannten Alters- und Herkunftskriterien erfüllten und bereit waren, an der Erhebung mitzuwirken, wurde ein individueller Termin vereinbart. Um eine möglichst zwanglose Atmosphäre zu schaffen, fanden die Aufnahmen bei den Gewährspersonen zu Hause mit einem subtilen, digitalen Aufnahmegerät (Zoom H2) statt, das auf dem Tisch zwischen Gewährsperson und Interviewer platziert wurde. Die Interviews wurden von verschiedenen Mitarbeitern des SiN-Projekts durchgeführt, die unterschiedliche Niederdeutschkompetenzen mitbrachten. Die Klassifikation der Dialektkompetenz der Gewährspersonen basierte daher zum einen auf Selbsteinschätzungen anhand der Kategorien 'schwach', 'mittel' und 'stark', die auf Nachfragen erläutert wurden. Um die Selbsteinschätzungen zu untermauern oder sie ggf. in Absprache mit der Gewährsperson zu korrigieren, wurden zusätzlich mittels eines Fragebogens Situationen und Häufigkeiten des Mundartengebrauchs erhoben. Hinzu kamen konkrete Sprachtests, die unter anderem auf Übersetzungsfähigkeit, Salienz, Normativität und Arealität abzielten und die nach subjektiven Gehörseindrücken sowie objektiven linguistischen und phonetischen Aspekten ausgewertet wurden.
Die durchgeführten Interviews beinhalteten neben Textlesungen, freien Erzählungen und Mitschnitten von Familiengesprächen auch spontane Übersetzungen der 40 Wenkersätze in den jeweiligen Ortsdialekt der Gewährspersonen. Diese spontanen Übersetzungen wurden als Basis für die vorliegende Studie herangezogen, da sie über die Interviews hinweg das lautlich und prosodisch einheitlichste Sprachmaterial darstellten und somit den besten Ausgangspunkt für eine kontrastive phonetische Analyse boten.
Für die Analyse wurde ein Set von 6 Wenkersätzen ausgewählt. Bei der Auswahl der Sätze standen zwei Kriterien im Vordergrund. Erstens sollten die lautlichen und prosodischen Kontexte, in denen die Zielvokale in den Sätzen standen, so vergleichbar wie möglich ausfallen. Zweitens sollten die Zielvokale selbst sowohl innerhalb einer Mundart als auch über Mundarten hinweg ein möglichst großes phonetisches Qualitätsspektrum abdecken. Letzteres zu erreichen, war keine triviale Aufgabe, denn schließlich konnte sich die Auswahl der Sätze nicht auf das wenige Wissen über die Vokalrealisierungen in den niederdeutschen Mundarten stützen. Es war ja gerade eines der Ziele unserer explorativen Studie, dieses begrenzte Wissen durch detaillierte phonetische Analysen zu ergänzen. Gewissermaßen hätte eine solide, empirische Auswahl der Sätze also erfordert, dass wir die Ergebnisse unserer Untersuchung bereits kennen würden. Um uns dieser Zirkularität zu entziehen, haben wir daher beschlossen, 6 sehr unterschiedliche standarddeutsche Vokalqualitäten auszuwählen, in der Erwartung, dass ihre Pendants in den jeweiligen Mundarten ein ähnlich großes Qualitätsspektrum abdecken würden. Auf Grundlage beider Kriterien wurden die folgenden 6 Wenkersätze selektiert (Zielwörter unterstrichen, Satznummer in Klammern).
Von standarddeutschen Phonemsymbolen ausgehend, waren die Zielvokale also /e:/, /a:/, /o:/, /u:/, /aɪ/ und /aʊ/. Somit umfasste unser Untersuchungsgegenstand der 'Langvokale' nicht nur die phonologische Klasse der langen Monophthonge, sondern auch die phonologische Klasse der Diphthonge. Dieser Umstand ist jedoch nur bei oberflächlicher Betrachtung vermeintlich inkonsistent. Zum einen verhalten sich Langvokale und Diphthonge phonologisch vergleichbar, und auch phonetisch sind sie einander in vielen Aspekten ähnlich; zum Beispiel hinsichtlich ihrer Dauer und der Tatsache, dass aufgrund der Koartikulation der Vokale mit den umliegenden Konsonanten kommt selbst bei Monphthongen immer Formanttransitionen zustande kommen, die auditiv als Qualitätsveränderungen wahrnehmbar sein können (vgl. Strange/Bohn 1998). Im Rahmen unserer Untersuchung kam als entscheidender Punkt hinzu, dass frühere Studien gezeigt haben, dass auch phonologische Monophthonge mit mehr oder weniger starken Diphthongierungen in den niederdeutschen Mundarten auftreten (vgl. 1.1). Das heißt, es ist davon auszugehen, dass die phonologische Differenzierung zwischen Monophthongen und Diphthongen mindestens auf allophonischer Ebene mehr oder weniger verschwimmt, insbesondere im Vergleich verschiedener Mundarten. Es ist zudem aus unserer Sicht nur unzureichend bekannt und begründet, welche standarddeutschen Monophthonge in den einzelnen Mundarten phonologisch als Diphthonge repräsentiert sind und umgekehrt. Aus den genannten Gründen, und weil es für unsere rein phonetischen Zielsetzungen ohnehin zunächst zweitrangig war, haben wir in unserer Studie gar nicht erst den Versuch unternommen, eine phonologische Trennung von Monophthongen und Diphthongen vorzunehmen. Dementsprechend verwenden wir nachfolgend ausschließlich den Begriff der Langvokale, die wir hinsichtlich ihres Grades der Diphthongierung vergleichen und daran orientiert als eher monophthongisch oder diphthongisch beschreiben.
Was die vergleichbaren lautlichen und prosodischen Rahmenbedingungen anlangt, so geht aus den dargestellten Sätzen hervor, dass alle 6 Zielvokale in Silben vorkamen, bei denen man davon ausgehen konnte, dass sie akzentuiert und folglich mit vergleichbarem artikulatorischen (Mehr-)Aufwand produziert werden würden (vgl. Kohler 1982; de Jong 1995). In puncto phrasenfinaler Längung haben zahlreiche Produktionsstudien sprachübergreifend gezeigt, dass sich ein solcher Effekt primär auf die letzte Silbe vor dem Phrasenende konzentriert und innerhalb dieser Silbe sogar von Segment zu Segment zunehmen kann (Kohler 1983; Berkovits 1993; Cambier-Langeveld u. a. 1997; Peters u. a. 2005; Turk/Shattuck-Hufnagel 2007). Die relevanten Silben in "kamen" und "verkaufen" waren zwar Bestandteil phrasenfinaler Wörter, standen jedoch – wie alle anderen vier relevanten Silben auch – selbst nicht am Phrasenende. Es darf daher davon ausgegangen werden, dass die Zielvokale in allen Silben nicht von finaler Längung betroffen waren und dahingehend gleich behandelt werden konnten. Selbst wenn sich die finale Längung im Falle von "kamen" und "verkaufen" geringfügig in die präfinale Silbe hinein erstrecken sollte, so wird sich dieser Effekt in der Stichprobe zu jeder Mundart in ähnlicher Weise manifestieren und daher nicht zu verzerrten Vergleichen führen. Auch Dehnungen phraseninitialer Silben, die für deutsche Dialekte beschrieben wurden (vgl. Leemann/Siebenhaar 2006, 2007), können durch die gewählten 6 Wenkersätze umgangen werden. Im Falle von "Kohlen", "gute" und "gehen" steht jeweils noch eine (potentiell gedehnte) Silbe als Puffer zwischen dem Phrasenanfang und der relevanten Silbe mit dem Zielvokal.
Des Weiteren wurde vor dem Hintergrund vergleichbarer Rahmenbedingungen berücksichtigt, dass die Position der Silbe im Wort einen Einfluss auf deren phonetische Reduktion haben könnte (vgl. Sproat/Fujimura 1993). Daher befanden sich alle Zielvokale in wortinitialen Silben. Bezüglich koartikulatorischer Einflüsse wurde Wert darauf gelegt, dass jedem der 6 Zielvokale ein velarer Plosiv voranging. Gefolgt wurden die Vokale allerdings entweder von einem alveolaren oder einem labialen Laut2. Diese notwendige Konzession an das zur Verfügung stehende Datenmaterial wird jedoch dadurch abgemildert, dass Studien nahelegen, dass Koartikulation im Deutschen eher mit dem vorausgehenden als mit dem nachfolgenden Laut stattfindet (vgl. z. B. Hoole u. a. 1993).
Eine letzte Homogenisierung betraf das Sprechergeschlecht. Für die kontrastive Analyse wurden ausschließlich die Daten weiblicher Gewährspersonen herangezogen. Es ist bekannt, dass Frauen mit anderer Sprechgeschwindigkeit, anderer Artikulationsdynamik und anderer Stimmqualität sprechen als Männer und dass die geschlechtsspezifische Anatomie der Stimmlippen und des Vokaltraktes darüber hinaus zu unterschiedlichen Grundfrequenz- und Formantlagen führt (vgl. Simpson 2009). Dahingehende phonetische Variationen in den Messungen wurden durch die Beschränkung auf ein Geschlecht vermieden. Dabei fiel die Wahl auf Sprecherinnen, da sie die Mehrheit im Wenkerkorpus stellten.
Insgesamt gingen in die Analyse der Zielvokale die Produktionen von 18 Sprecherinnen ein. Sie verteilten sich gleichmäßig über die 6 Dialektregionen
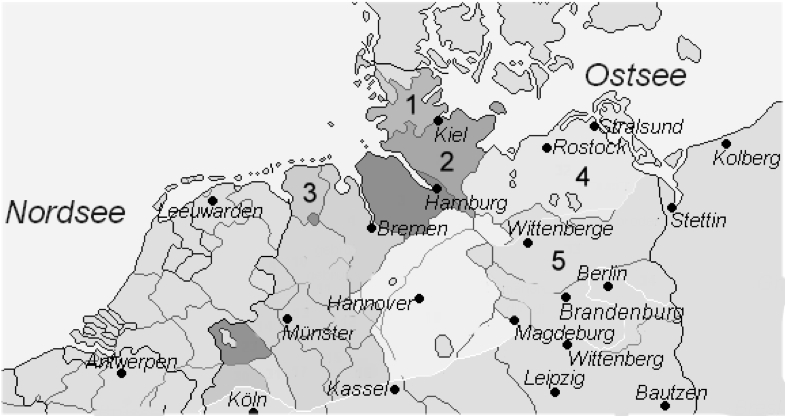
Abbildung 1: Übersicht über die Binneneinteilung des niederdeutschen Sprachraumes3. Ein globalerer Überblick findet sich bei Sanders (1982, Karte 3).
Die ersten vier Regionen gehören zum westniederdeutschen Dialektraum und hierin zum nordniedersächsischen Dialektverband. Holstein, Ostfriesland und Schleswig sollen gemäß den Angaben aus der Literatur (vgl. 1.1) jeweils einen eigenen Landschaftsdialekt darstellen (Schleswigsch, Holsteinisch und Ostfriesisch; vgl. Bereiche 1–3 in Abb.1). Die Dithmarscher Region soll, der aktuellen Binneneinteilung und Abbildung 1 folgend, zunächst als mit zum holsteinischen Landschaftsdialekt gehörig betrachtet werden (vgl. 1.1). Die Regionen Mecklenburg-Vorpommern und Nordbrandenburg sind dem ostniederdeutschen Dialektraum zuzurechnen und repräsentieren hierin laut aktueller Binneneinteilung die beiden Landschaftsdialekte Mecklenburgisch und Nordmärkisch (vgl. Bereiche 4–5 in Abb.1) in den Dialektverbänden des Mecklenburgisch-Vorpommerschen bzw. des Märkisch-Brandenburgischen. Da im Gegensatz zur regional-geographischen Einteilung die dialektale Einteilung, das heißt die Anzahl und Lage von Mundartgrenzen, durch Sprachkontakt prinzipiell dynamischer Natur und obendrein eine empirische Frage ist, die auch in dieser Studie behandelt wird, werden die Ergebnisse der Analysen zunächst auf die Regionsnamen und nicht auf deren Mundarten bezogen. Zuordnungen von Regionen und Mundarten werden erst im Anschluss an die Ergebnispräsentation in 4.2 vorgenommen und diskutiert.
Die Anzahl der pro Region auswertbaren Sprecherinnen wurde erheblich dadurch eingeschränkt, dass in den Sätzen nicht immer das vorgegebene Zielwort und damit der zu analysierenden Zielvokal produziert wurden. In einer Reihe von Satzproduktionen kam es beispielsweise zum Gebrauch von Synonymen wie "Briketts" statt "Kohlen". In anderen Fällen wurde das Zielwort von Versprechern oder Lachen überlagert. Dies betraf zum Beispiel "kein" in Satz (32), das von einigen Gewährspersonen als "ein" produziert wurde. Darüber hinaus wurden nur Sprecherinnen mit vergleichbar guter Mundartkompetenz (d.h., mindestens mittlerer Verkehrskompetenz) für die Analyse herangezogen. Nicht zuletzt hat sich einschränkend ausgewirkt, dass die Aufnahmequalität bei einigen Sprecherinnen so schlecht war, dass deren Satzproduktionen für eine phonetische Analyse nicht geeignet waren. Am Ende blieben für einige Regionen nur drei Sprecherinnen übrig. Diese Sprecherzahl wurde dann auch für alle anderen Regionen übernommen, um gleich große Stichproben zu erhalten.
Da die 6 ausgewählten Wenkersätze von 18 Sprecherinnen produziert wurden, umfasste die akustische Analyse 108 Zielvokale aus ebenso vielen Zielwortproduktionen. Für jeden Vokal wurden 12 unterschiedliche Messwerte erhoben, sodass insgesamt 1296 Einzelmessungen durchgeführt wurden. Dies geschah manuell durch die erste Autorin. Sie ist deutsche Muttersprachlerin und verfügt zudem selbst über eine gute niederdeutsche Mundartenkompetenz. Auf diese Weise konnte – zusätzlich zur Vorauswahl von Gewährpersonen mit mindestens mittlerer Mundartkompetenz – im Rahmen der Analyse auch auf der Ebene der einzelnen Sätze nochmals kontrolliert werden, dass die Spontanübersetzungen tatsächlich alle homogen mit vergleichbar deutlich ausgeprägter Mundart geäußert wurden.
Mit dem Analyseprogramm XASSP des Instituts für Phonetik und Digitiale Sprachverarbeitung der Universität Kiel (vgl. Scheffers/Thon 1991) wurden mittels einer spektralen LPC-Analyse (vgl. Markel/Gray 1976) die Hertz-Werte der Grundfrequenz (F0) und der ersten drei Formanten (F1-F3) bestimmt. Abbildung 2 zeigt ein Beispiel für eine Analysefensterkonfiguration unter XASSP.
F0 ist das primäre akustische Korrelat der wahrgenommenen Tonhöhe und kann somit als Repräsentant der Intonation angesehen werden (vgl. Lehiste 1970). Dennoch dienten die F0-Messungen nicht in erster Linie der Bestimmung intonatorischer Eigenschaften. Die Messungen sollten primär die obige Annahme unterstützen, dass alle Zielvokale in gleichermaßen akzentuierten Silben produziert wurden. Da eine Akzentuierung mit einem Tonhöhenakzent in Form einer deutlichen F0-Auslenkung einhergeht und sich zudem der Grad der Akzentuierung im Ausmaß dieser F0-Auslenkung widerspiegelt, werden die relevanten Silben der 6 Zielwörter im Falle einer vergleichbaren Akzentuierung alle vergleichbar große F0-Veränderungen aufweisen. Dass diese F0-Veränderungen aus unterschiedlichen Typen von Tonhöhenakzenten stammen und somit auf unterschiedlich zur Akzentsilbe synchronisierte steigende und fallende F0-Bewegungen zurückgehen können, war für das Ziel der Messungen zunächst einmal sekundär.
Bei den Formanten F1, F2 und F3 handelt es sich um die maßgeblichen Resonanzen des Ansatzrohres bei der Wahrnehmung der Vokalqualität (vgl. Syrdal/Gopal 1986). F1 korreliert mit dem Öffnungsgrad des Vokals. Der F1-Wert steigt mit zunehmender Öffnung an. In F2 drücken sich in unterschiedlichen Anteilen die horizontale Zungenlage und die Lippenrundung aus. Für weiter hinten im Mundraum gebildete und gerundete Vokale sinkt F2 ab. Die Lage des dritten Formanten, F3, wird durch unterschiedliche artikulatorische Faktoren bestimmt. Im Bereich der Konsonanten etwa verringern sich die F3-Werte stark für retroflexe Laute. Im Bereich der Vokale, wo retroflexe Artikulationen oder Artikulationen mit ähnlich starker Engebildung im Ansatzrohr keine Rolle spielen, lassen sich F3-Veränderungen mit Lippenrundung in Beziehung setzen. Obwohl für vordere Vokale stärker ausgeprägt als für hintere, haben gerundete Lippen immer eine absenkende Wirkung auf F3. Insofern erlaubt F3 selbst über ein großes Vokalspektrum hinweg präzisere Aussagen bezüglich der Lippenrundung als F2, in dem die Lippenrundung immer mit der horizontalen Zungenlage konfundiert ist (vgl. Ladefoged 1996; Harrington/Cassidy 1999). Daher haben wir in unsere Analyse beide höheren Formanten einbezogen, wobei wir es als zulässige Vereinfachung betrachten, F3 als Korrelat der Lippenrundung zu interpretieren.
Die F0–F3 Messwerte wurden jeweils aus der Vokalmitte entnommen. In einigen Fällen musste um einige Millisekunden (ms) vom Mittelpunkt abgewichen werden, um ein eindeutiges Messergebnis zu erzielen. Zusätzlich wurden für F0 sowie für F1-F3 die Minima und Maxima im Vokal bestimmt und hieraus die F0-Veränderung bzw. der Transitionsumfang jedes Formanten im Vokal berechnet. Des Weiteren wurde die Gesamtdauer des Vokals in Millisekunden ermittelt. Dies geschah zum einen optisch durch Analysieren des Spektrogramms und Oszillogramms und wurde zum anderen durch das Gehör unterstützt. Basierend auf den Dauerwerten und den zuvor berechneten Transitionsumfängen der Formanten wurde letztlich die Dynamik der Formanttransitionen (Umfang/Zeit) hergeleitet. Dynamik und Umfang der Formanttransitionen spiegeln den Grad der Diphthongierung der Langvokale wider (vgl. Sawusch 1996). In diesem Zusammenhang ist es wichtig zu erwähnen, dass die Formantwerte aus der Vokalmitte unabhängig vom Grad der Diphthongierung sinnvolle und durchaus vergleichbare Informationen zur Klangcharakteristik liefern. Im Falle rein monophtongischer Vokale ist die Vokalmitte die akustisch stabilste Region, die auch die wahrgenommene Vokalqualität entscheidend mitbestimmt. Eine zunehmende Diphthongierung prägt sich bei den hier zu erwartenden, großen Vokaldauern praktisch ausschließlich auf der zweiten Vokalhälfte aus (das gilt auch für phonologische, fallende Diphthonge, vgl. Simpson 1998). Dementsprechend geben selbst bei stärkerer Diphthongierung die Formantwerte um die Vokalmitte herum immer diejenige Klangqualität wieder, auf der das akustische wie auditive Hauptgewicht liegt (vgl. in Verbindung mit dem auditiven Hauptgewicht auch die Studien zu 'perceptual centres', z. B. Scott 1998).
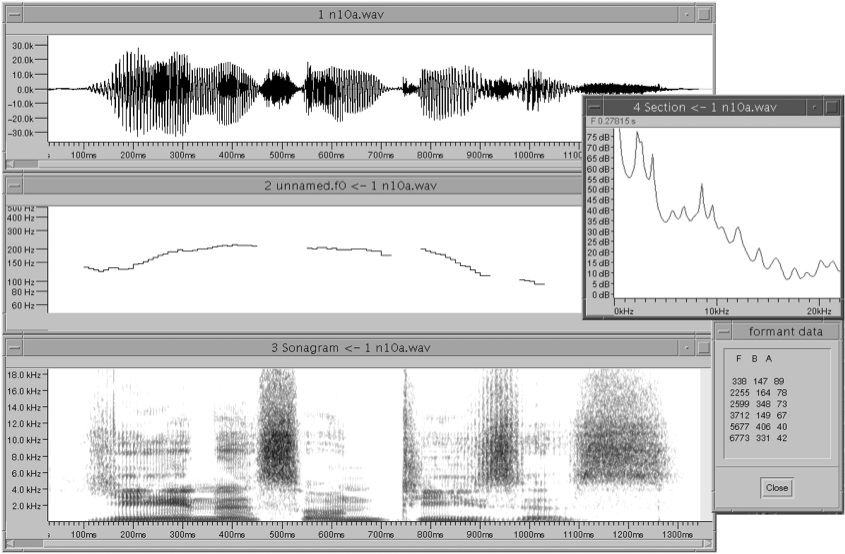
Abbildung 2: Analysefensterkonfiguration in XASSP. Links: Oszillogramm (oben), F0-Verlauf (10 ms-Schritte, Mitte) und DFT-Spektrogramm (0–18 kHz, unten). Rechts: LPC-Analyse des Frequenzspektrums in der Vokalmitte (oben) sowie die hieraus extrahierten Werte (F) für F0 und die ersten 5 Formanten mit deren Bandbreiten (B) und Amplituden (A).
Während die F0-Messungen in der Einheit Hertz (Hz) belassen wurden (da ausschließlich weibliche Gewährspersonen analysiert wurden, erschien eine Umrechnung in Halbtonschritte unnötig), wurden alle Formantwerte von Hz in Bark transformiert. Dieses Maß war für die Zielsetzung der Studie angemessener, da ihm eine nicht-lineare Skala zugrunde liegt. Diese bildet die Verarbeitung des Sprachschalls auf der Basilarmembran im menschlichen Ohr besser ab als die lineare Hz-Skala. Dementsprechend besteht eine engere Korrelation zwischen Bark-Werten und wahrgenommenen Vokalqualitäten als zwischen Hz-Werten und wahrgenommenen Vokalqualitäten (vgl. z. B. Syrdal/Gopal 1986). Nichtsdestoweniger wurde als Ergänzung der akustischen Messungen auch eine qualitative ohrenphonetische Analyse der Zielvokale und – damit einhergehend – eine enge phonetische Transkription jedes Vokals nach dem System der IPA (vgl. IPA 1999) vorgenommen.
Für die Präsentation der Ergebnisse der akustischen Analyse wird der prüfstatistischen Auswertung der Messdaten eine separate, deskriptive Auswertung von zentralen Aspekten der regionalen Vokaleigenschaften vorangestellt. Diese Ausgliederung geschieht zum einen vor dem Hintergrund der beiden Forschungsziele, bei denen es nicht allein um die Unterscheidbarkeit der niederdeutschen Regionen bzw. Mundarten anhand ausgesuchter Langvokale geht (3.2), sondern auch darum, die Qualitäten dieser Langvokale in einigen ersten Details phonetisch zu beschreiben (3.1). Hierbei werden die mit modernen messphonetischen Methoden ermittelten Details mit Details, die auf eine traditionell ohrenphonetische Weise gewonnen wurden, verglichen. Zum anderen werden durch die vorherige deskriptive Auswertung die statistischen Befunde leichter nachvollziehbar. Es ergibt sich ein insgesamt klareres Bild der Ergebnisse.
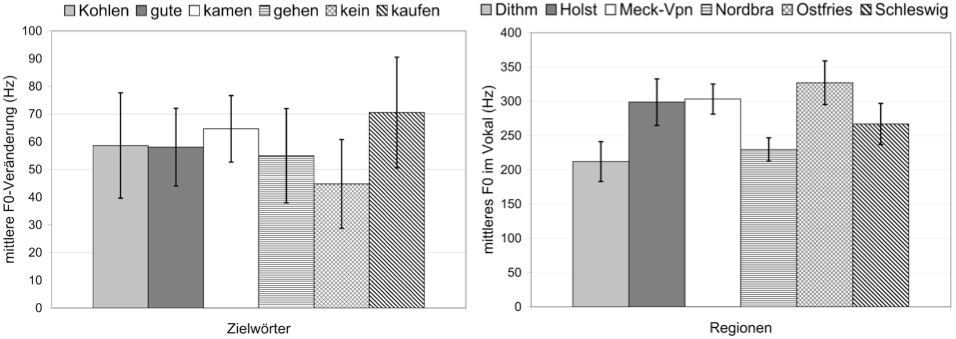
Zentrale Aspekte der Ergebnisse der akustischen Analyse der Langvokale unserer Pilotstudie sind in den Abbildungen 3–7 wiedergegeben. Einleitend zeigen Abbildungen 3(a)–(b) charakteristische Merkmale des F0 – und somit des Intonationsverlaufs in den Langvokalen. Aus Abbildung 3(a) wird ersichtlich, dass in allen Zielwörtern eine deutliche Intonationsbewegung über den Langvokal hinweg stattfand. Im Mittel umfassten diese Bewegungen etwa 50–70 Hz. Wie die Standardabweichungen zeigen, erstreckten sich einige Intonationsbewegungen auch über mehr als 90 Hz. Das Zielwort "kein" wies über die Regionen hinweg insgesamt geringfügig kleinere Intonationsbewegungen auf als die anderen Zielwörter, insbesondere "kaufen". Wie jedoch in 3.2.1 ausgeführt wird, sind die Umfänge der Intonationsbewegungen über alle Zielwörter betrachtet nicht signifikant unterschiedlich. Da die Langvokale alle in wortinitialen, lexikalisch akzentuierten Silben vorkamen, lassen die vergleichbar großen Intonationsbewegungen darauf schließen, dass die 18 Sprecherinnen der 6 Regionen sämtliche analysierten Zielwörter mit klaren und vergleichbar starken Satzakzenten produziert haben. Folglich sind die kontrastiv analysierten Dauer- und Formanteigenschaften der Langvokale frei von Artefakten inkonsistenter Akzentuierungen.
| a) | b) |
Abbildung 3: (a) Umfang der F0-Veränderung über den Langvokalen der einzelnen Zielwörter (in Hz), aufgeschlüsselt in die Zielwortproduktionen aller 6 Regionen; (b) F0 (in Hz) in der Mitte der Langvokale der Zielwörter jeder Region. Jeder Balken in (a) und (b) repräsentiert den Mittelwert aus 18 Messungen; vertikale Linien sind Standardabweichungen.
Bevor jedoch die Dauer- und Formanteigenschaften der Langvokale präsentiert werden, soll noch auf einen interessanten Aspekt der F0-Bewegungen, die über den Langvokalen liegen, eingegangen werden. Abbildung 3(b) zeigt das durchschnittliche F0-Niveau, das über alle 6 Zielwörter hinweg in der Mitte des Langvokals für die einzelnen Regionen gemessen wurde. Anders als im Falle des Umfangs der Intonationsbewegungen sind für das Intonationsniveau in der Vokalmitte bei vergleichsweise geringen Standardabweichungen klare Unterschiede festzustellen, die in 3.2.1 als statistisch hoch signifikant erweisen werden. Solche unterschiedlichen F0-Niveaus können verschiedene Ursachen haben. Da es sich bei unseren Daten durchweg um von weiblichen Gewährspersonen sachlich gelesene Einzelsätze handelte, fällt ein geschlechtsspezifischer Effekt als Ursache ebenso weg wie emotional, sozial oder durch Funktionen der Gesprächssteuerung bedingte Verschiebungen des F0-Registers (vgl. Cruttenden 1997). Als weitere mögliche Ursachen für die unterschiedlichen F0-Niveaus sind dialektspezifische oder - aufgrund der geringen Anzahl der Sprecherinnen pro Dialekt - schlichtweg idiolektale Effekte denkbar. Wenn aber der Bezugsrahmen der F0-Messung dahingehend erweitert wird, dass das mittlere F0 über die gesamten Interviews der 18 Sprecherinnen berechnet wird, dann kommen keine F0-Unterschiede zustande. Damit scheiden idiolektale Effekte als Erklärung für die unterschiedlichen F0-Niveaus in der Vokalmitte aus.
Eine daraufhin vorgenommene, eingehendere Betrachtung der Produktionsdaten hat vielmehr ergeben, dass die in Abbildung 3(b) dargestellten unterschiedlichen F0-Niveaus in der Vokalmitte auf dialektspezifisch geformte und synchronisierte Tonhöhenakzente zurückgeführt werden können (die ggf. auch phonologisch unterschiedlich analysiert werden können). Die vergleichsweise kleinen Standardabweichungen in Abbildung 3(b) zeigen zudem, dass die Produktion der dialektspezifischen Tonhöhenakzente über die Sprecherinnen und Zielwörter hinweg sehr konsistent ausfiel. Sowohl die Existenz als auch die Konsistenz regionaler Unterschiede in deutschen Tonhöhenakzenten geht konform mit Befunden früherer Forschungsarbeiten, in denen das nördliche Standarddeutsch mit Dialektvarietäten aus Hamburg, Freiburg, Bayern, Österreich und der Schweiz verglichen wurde (vgl. Atterer/Ladd 2004; Peters 2006; Kohler 2007a; Leemann/Siebenhaar 2008). Unsere F0-Messungen geben Anlass dazu, diese Forschung auf die niederdeutsche Dialektlandschaft auszuweiten. Zu diesem Zweck werden einige Details der von uns beobachteten Tonhöhenakzente in Abschnitt 4.3 vorgestellt.
Was nun die Vokalsegmente selbst anlangt, so haben die Dauermessungen weder zwischen den Zielwörtern noch zwischen den Regionen signifikante Unterschiede ergeben (vgl. 3.2.1). Verglichen mit Werten, die bei Gruppen norddeutscher und süddeutscher Sprecherinnen mit intendierter Standardaussprache gemessen wurden (vgl. Simpson 1998; Möbius/van Santen 1996), fielen unsere niederdeutschen Langvokaldauern mit durchschnittlich 120-170 ms allerdings bemerkenswert groß aus. Andererseits liegen unsere Dauerwerte genau in dem Bereich, der auch in anderen auf Lesesprache basierenden akustischen Analysen für Langvokale niederdeutscher Mundarten kennzeichnend war (vgl. Hildebrandt 1963; Tödter 1982; Kohler u. a. 1986b). Diese Übereinstimmungen mit früheren Studien unterstützen zum einen, dass es sich bei den von uns analysierten Lauten tatsächlich um Langvokale handelte. Zum anderen zeichnet sich im Vergleich aller genannten Studien ein grundsätzlicher Dauerunterschied zwischen den Langvokalen des Standarddeutschen und des Niederdeutschen ab. Ursächlich hierfür ist möglicherweise, dass im Vokalsystem des Standarddeutschen Qualität und Quantität redundante Merkmale sind, während in den niederdeutschen Vokalsystemen sowohl Qualitäts- als auch Quantitätsoppositionen vorkommen (vgl. Kohler 1986). Folglich spielt für die Wortidentifikation im Niederdeutschen ein möglichst großer Dauerabstand zwischen Lang- und Kurzvokalen eine gewichtigere Rolle als im Standarddeutschen. Darüber hinaus ist denkbar, dass die Dauerunterschiede zwischen niederdeutschen und standarddeutschen Langvokalen (auch) auf unterschiedliche Sprechgeschwindigkeiten zurückgehen, wie sie auch zwischen germanischen und romanischen Sprachen bestehen (vgl. Dellwo u. a. 2006). Hiergegen spricht allerdings, dass die niederdeutschen und standarddeutschen Kurzvokale anders als die Langvokale in vergleichbare Wertebereiche fallen.
Bezüglich der Klangqualitäten der Vokalsegmente zeigt Abbildung 4 zunächst die Verteilung der F1- und F2-Formantwerte, die in der Mitte der Langvokale der 6 Zielwörter über alle Regionen hinweg gemessen wurden. Jeder Datenpunkt repräsentiert ein Zielwort. Die Skalierung der Achsen wurde in Anlehnung an das Vokalviereck der IPA vorgenommen (vgl. IPA 1999). Da die Messwerte zudem in Bark angegeben werden (vgl. 2.2), lässt sich die Lage der Messpunkte im Werteraum in Relation zur Lage der Kardinalvokale im Vokalviereck interpretieren. So weisen zum Beispiel die F1-F2-Messpunkte im oberen linken Bereich auf vordere, geschlossene Vokalqualitäten wie [i] hin, der untere Bereich des dargestellten Werteraums repräsentiert offene Vokale wie [ɐ̞] (was hier die Qualität des norddeutscher Standardsprecherinnen und -sprecher indiziert), und der obere rechte Bereich deckt hintere, gerundete Vokale ab, zu denen etwa das [u] gehört.
Zunächst einmal ist aus Abbildung 4 klar erkennbar, dass sich die F1-F2-Werte recht gleichmäßig entlang der Ränder über den gesamten dargestellten Vokalraum verteilen. Dies passt zu unserer Absicht, über die Auswahl der Zielwörter ein möglichst breites Spektrum an Vokalqualitäten in der Analyse abzudecken. Darüber hinaus besteht die entscheidende Eigenschaft der Punkteverteilung darin, dass die F1-F2-Werte der einzelnen Langvokale keine klar umrissenen und gegeneinander abgrenzbaren Bereiche im Werteraum ausbilden. Da wir im Vorfeld der Analyse wichtige koartikulatorische und prosodische Störfaktoren für die Ausprägung der Vokalqualität kontrolliert haben (vgl. 2.1 und Abb. 3a), wären jedoch solche, sich gegeneinander abhebende Wertebereiche entstanden, wenn die Qualität jedes Langvokals über die 6 Regionen hinweg konstant gewesen wäre. Stattdessen fließen die Wertebereiche der Langvokale der einzelnen Zielwörter - vor allem entlang der vertikalen Achse des ersten Formanten - stark ineinander und sind aus der Gesamtverteilung kaum herauszulösen. Damit ist Abbildung 4 ein erster Indikator dafür, dass das niederdeutsche Wort überregional mit deutlich unterschiedlichen Langvokalqualitäten einhergeht. Einen genaueren Einblick, wie die einzelnen Regionen den Vokalraum über alle Zielwörter hinweg ausnutzen, vermitteln die nachfolgenden Abbildungen 5–7.
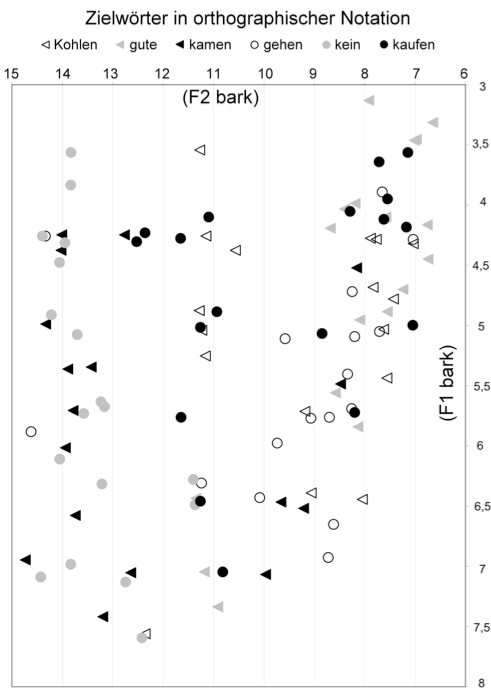
Abbildung 4: Am Vokalraum der IPA orientierte Darstellung der F1- und F2-Formantlagen (in Bark), gemessen in der Mitte der Langvokale aller Zielwörter und Regionen; n=108.
Anhand von Abbildung 5 lassen sich grob zwei Typen von Punktwolken unterscheiden. In den Regionen Dithmarschen, Nordbrandenburg und Schleswig verteilen sich die aus der Vokalmitte entnommenen Formantkonstellationen über weite Bereiche des Vokalraums. Die F1-F2-Konstellationen weisen zum Beispiel auf offene Qualitäten ebenso hin, wie auf geschlossene vordere und hintere Qualitäten. Im Gegensatz dazu fällt das Werte- und Qualitätsspektrum von Mecklenburg-Vorpommern und Ostfriesland sehr viel begrenzter aus. F1-Werte von über 7 Bark, die sowohl hinsichtlich der Illustrationen als auch gemäß weiblichen Referenzwerten aus der Literatur (vgl. Pätzold/Simpson 1997; Hillenbrand u. a. 1995) auf offene Vokale hindeuten, wurden nicht gefunden. Im Falle von Mecklenburg-Vorpommern fehlen zusätzlich Punkte mit niedrigen F1-Werten von unter 4 Bark, die für geschlossene Vokalqualitäten charakteristisch sind. Das Qualitätsspektrum in der Vokalmitte scheint auf halboffene bzw. halbgeschlossene Qualitäten beschränkt zu sein. Die holsteinische Punktwolke lässt zwar auf das Vorhandensein von sowohl offenen als auch geschlossenen Vokalen schließen, letztere konzentrieren sich jedoch auf hintere, gerundete Qualitäten; deutlich [i]-artige Qualitäten spiegelt die Punktwolke nicht wider. Insofern gehört Holstein in die gleiche Gruppe wie Mecklenburg-Vorpommern und Ostfriesland.
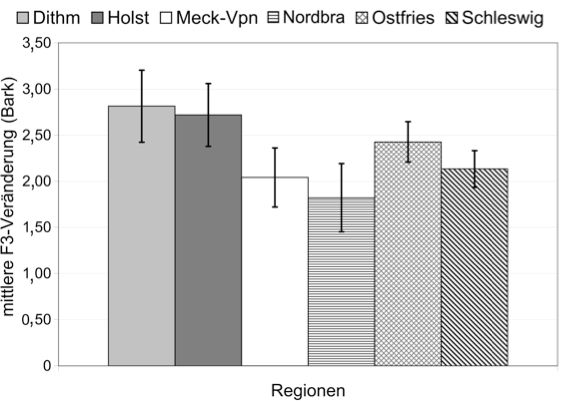
Ein begrenztes Formant- bzw. Qualitätsspektrum in der Vokalmitte muss jedoch nicht zwangsläufig bedeuten, dass die phonetische Vielfalt über die Gesamtdauer der Langvokale in den Regionen Holstein, Mecklenburg-Vorpommern und Ostfriesland geringer ausfällt als in den Regionen Dithmarschen, Nordbrandenburg und Schleswig. Abbildungen 6–7 zeigen für die 6 Regionen die durchschnittlichen Transitionsumfänge der ersten drei Formanten, die als Indikator für eine mehr oder weniger ausgeprägte Diphthongierung herangezogen werden können. Wie in den beiden Abbildungen illustriert ist, fallen die Regionen mit den begrenzteren Formant- und Qualitätsspektren in der Vokalmitte durch vergleichsweise umfangreiche Formanttransitionen auf. So wurden für die holsteinischen Langvokale die größten F1- und F2-Transitionen gefunden (vgl. Abb. 6). Die Transitionen in den Langvokalen der Dithmarscher Zielwörter fielen annähernd genauso groß aus. Demgegenüber waren die Transitionen der ersten beiden Formanten in den Regionen Nordbrandenburg und Schleswig nur etwa halb so klein. Auch die Transitionen des dritten Formanten waren für diese beiden Regionen mit am kleinsten und unterschieden sich damit deutlich von den umfangreicheren F3-Transitionen der Langvokale aus Holstein und Ostfriesland (vgl. Abb.7). Die F3-Transitionen in Mecklenburg-Vorpommern waren im Gesamtvergleich von mittlerem Umfang.
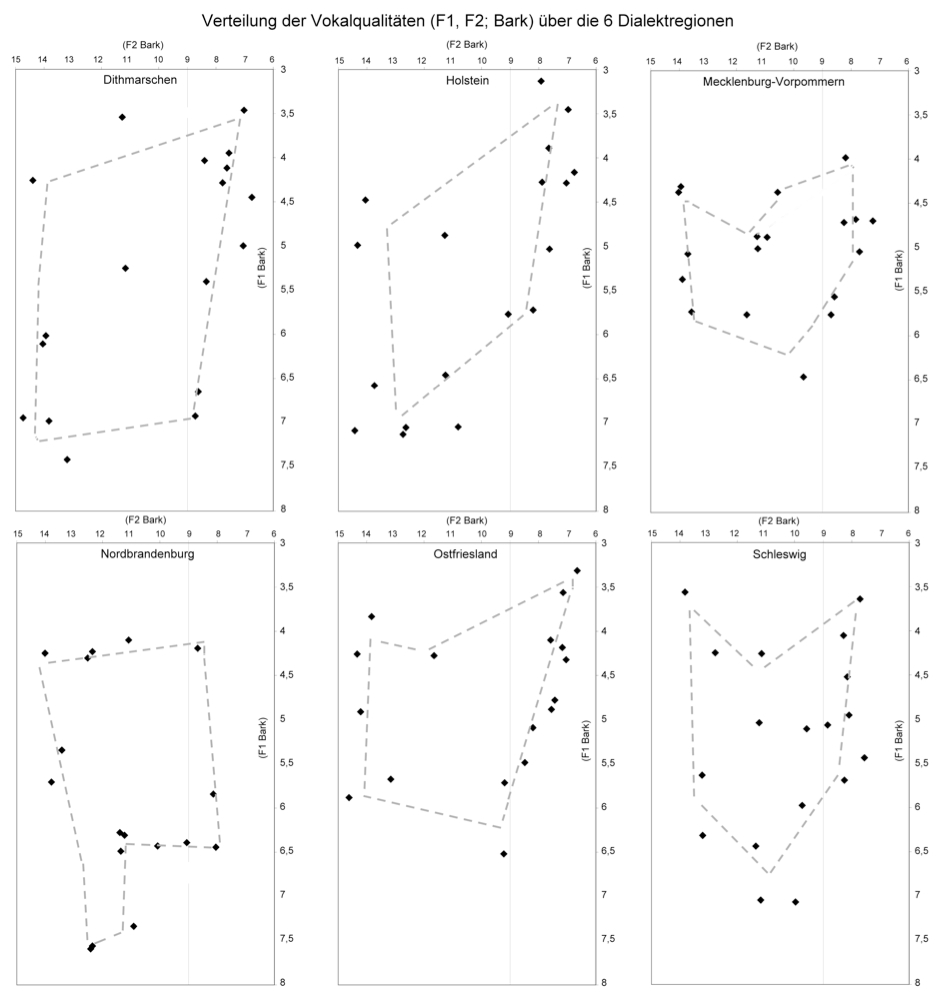
Abbildung 5: F1- und F2-Formantlagen (in Bark) in der Mitte der Langvokale, separat dargestellt für die Zielwortproduktionen zu jeder der 6 Regionen; n=18 pro Diagramm.
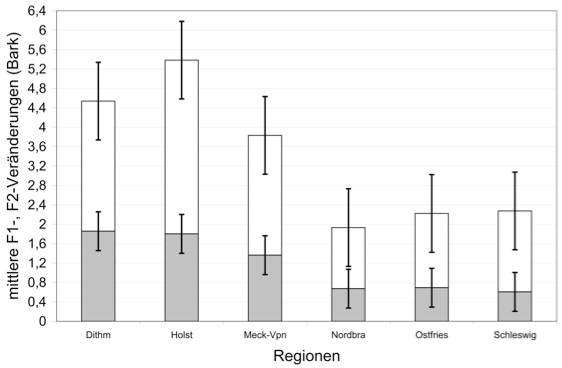
Abbildung 6: Mittelwerte (Balken) und Standardabweichungen (vertikale Linien) der Transitionsumfänge (in Bark) der Formanten F1 (grau) und F2 (weiß) für die Zielwörter der 6 Regionen. Jeder Balken repräsentiert 18 Messungen.
Abbldung 7: Mittelwerte (Balken) und Standardabweichungen (vertikale Linien) der Transitionsumfänge (in Bark) des dritten Formanten F3, separat angegeben für die Zielwörter der 6 Regionen. Jeder Balken repräsentiert 18 Messungen.
Zusammengefasst zeichnet sich auf Basis der Formantlagen und -transitionen ein dreigliedriges Bild ab, in dem Nordbrandenburg und Schleswig sich durch ein großes Qualitätsspektrum eher monophthongischer Langvokale auszeichnen, während in Holstein, Mecklenburg-Vorpommern und Ostfriesland die auditiv besonders saliente Qualität in der Vokalmitte weniger stark variiert, darüber hinaus jedoch eher diphthongisch beschaffen ist. Die Langvokale aus den Dithmarscher Zielwörtern scheinen beide Eigenschaften zu vereinen: große Qualitätsunterschiede im Zentrum des Vokals bei einer insgesamt eher diphthongischen Vokalqualität.
Diese, sich aus der akustischen Analyse herauskristallisierende Einschätzung, wird durch eine ohrenphonetische Analyse der Erstautorin unterstützt, die in Tabelle 1 zusammengestellt ist. Tabelle 1 zeigt auch, dass die als diphthongisch transkribierten Langvokale keineswegs nur in den Zielwörtern "kein" und "kaufen" vorkamen, in denen die Langvokale aus standarddeutscher Sicht phonologisch zur Klasse der Diphthonge gehören. Vor diesem Hintergrund wurde ein Chi-Quadrat-Test durchgeführt, in dem die absoluten Häufigkeiten der diphthongischen und monophthongischen Transkriptionen über alle Regionen hinweg für die einzelnen Zielwörter verglichen wurden. Dieser Test hat keine signifikanten Unterschiede erbracht. Das heißt, die diphthongischen und monophthongischen Transkriptionen der Langvokale können als gleichverteilt über die 6 Zielwörter angesehen werden. Entsprechend wird in den nachfolgenden prüfstatistischen Auswertungen nicht zwischen "kein" und "kaufen" auf der einen Seite und "Kohlen", "gute", "kamen" und "gehen" auf der anderen Seite unterschieden. Darüber hinaus bleibt anzumerken, dass alle ohrenphonetisch gefundenen Diphthongierungen als schließend transkribiert wurden. Dies deckt sich mit den phonetischen Analysen von Kohler u. a. (1986a,b), insbesondere bezüglich der Dithmarscher Mundart (vgl. 1.2.1).

Tabelle 1: Ohrenphonetische Charakterisierung der monophthongischen und diphthongischen Langvokalqualitäten in den Zielwörtern der Regionen. Varianten der phonetischen Transkriptionen sind durch Komma getrennt.
Die prüfstatistische Auswertung der Ergebnisse bestand aus zwei Komponenten, einer multivariaten Varianzanalyse (MANOVA) mit den beiden sechsstufigen Zwischensubjektfaktoren Zielwort und Region (unabhängige Variablen) sowie drei Diskriminanzanalysen, die sich separat mit der Zuordnung der Langvokale zu den Zielwörtern, den Regionen und auch zu den Transkriptionen in Tabelle 1 befassten. Letzteres, das heißt die Suche nach konsistenten Beziehungen zwischen messphonetischen (Formant-)Werten und ohrenphonetischen Klassifikationen, dient primär einer empirischen Fundierung der ohrenphonetischen Analyse, stützt letztlich aber auch die Aussagekraft der Analysen insgesamt. Für beide Komponenten, MANOVA und Diskriminanzanalysen, wurden alle 12 analysierten akustischen Parameter als abhängige Variablen herangezogen.
Die MANOVA ergab klare Haupteffekte für beide Zwischensubjektfaktoren. Das heißt, die 12 Messparameter wurden in hoch signifikanter Weise sowohl durch den Faktor Zielwort als auch durch den Faktor Region beeinflusst (F(75.282)=148.449; p<0.001; ƞp2=0.973; F(75.282)=5.065; p<0.001; ƞp2=0.551). Hinsichtlich der Stärke des Einflusses (partielles Eta-Quadrat, ƞp2) spielte die Region jedoch eine deutlich geringere Rolle als das Zielwort. In zusätzlichen univariaten Tests wurde ermittelt, welche der 12 Messparameter für die Haupteffekte jedes Faktors relevant waren. Im Falle des Faktors Zielwort führten die univariaten Tests zu signifikanten Befunden für die folgenden Messparameter: F2 in der Vokalmitte (F(5.72)=35.319; p<0.001; ƞp2=0.710), Umfang der F1-Transition (F(5.72)=18.393; p<0.001; ƞp2=0.902), Dynamik der F1-Transition (F(5.72)=121.392; p<0.001; ƞp2=0.781), Umfang der F2-Transition (F(5.72)=7.957; p<0.001; ƞp2=0.356) und Dynamik der F2-Transition (F(5.72)=5.773; p<0.001; ƞp2=0.286). Art und Umfang der F0-Bewegungen unterschieden sich nicht zwischen den Zielwörtern. Im Falle des Faktors Region fielen die F0-Werte in der Vokalmitte jedoch, wie in Abbildung 3 illustriert, hoch signifikant unterschiedlich aus (F(5.72)=8.768; p<0.001; ƞp2=0.378). Daneben ergaben sich signifikante, regionale Unterschiede für F1 in der Vokalmitte (F(5.72)=2.418; p=0.044; ƞp2=0.144), F3 in der Vokalmitte (F(5.72)=3.491; p=0.007; ƞp2=0.195) und Umfang der F3-Transition (F(5.72)=2.901; p=0.015; ƞp2=0.170). Messparameter wie der F0-Umfang über dem Vokal und die Vokaldauer selbst erreichten für beide Faktoren nicht einmal annähernd das Signifikanzniveau von p<0.05. Neben beiden Haupteffekten führte die MANOVA zu einer hoch signifikanten Interaktion beider Faktoren, die darauf zurückzuführen ist, dass Stärke und Richtung des Einflusses der Region auf die Langvokale für jedes Zielwort unterschiedlich ausfiel (F(375.800)=6.443; p<0.001; ƞp2=0.691).
Aufgrund des recht geringen Stichprobenumfangs ist es schwer einzuschätzen, wie robust die Signifikanzen der Interaktion und der univariaten Tests sind. Auch vor diesem Hintergrund wird die Diskriminanzanalyse weiteren einen Einblick darin geben, in welchen der 12 Messparameter sich die regionalen Charakteristika am deutlichsten widerspiegeln. Die Diskriminanzanalysen testen, inwieweit die produzierten Langvokale allein anhand ihrer 12 erhobenen Messwerte korrekt als zur betreffenden Region bzw. zum betreffenden Zielwort gehörig vorhergesagt werden können. Damit ist die Vorhersageleistung ein Indikator dafür, wie deutlich sich die Langvokale der 6 Regionen bzw. Zielwörter gegeneinander abgrenzen.
Die auf das Zielwort ausgerichtete Diskriminanzanalyse hat ganz klar ergeben, dass sich die Langvokale über ihre 12 Messwerte signifikant überzufällig korrekt den Zielwörtern zuordnen ließen (Diskr.-Funk.1-5: Wilks' Lambda=0.007; df=80; p<0.001). Diese Leistung basierte vor allem auf den ersten drei kanonischen Diskriminanzfunktionen (1: Eigenwert=25.095; kanon. Korrel.=0.981; 2: Eigenwert=1.388; kanon. Korrel.=0.762; 3: Eigenwert=0.671; kanon. Korrel.=0.634). Insgesamt lag die korrekte Vorhersageleistung bei 69.4% und damit beträchtlich über dem Zufallsniveau von 16.6%. Über ihre 12 Messwerte konnten die Langvokale aus "Kohlen" sogar zu 100% als solche erkannt werden. Die Langvokale aus "gute" und "kein" konnten in immerhin 72.2% bzw. 77.8% korrekt ihrem Zielwort zugeordnet werden. Im Falle von "gehen" und "kaufen" betrugen die korrekten Vorhersageleistungen der Zielwörter über die Langvokalmesswerte 61.1% und 66.7%. Die Langvokale aus "kamen" wurden mit 38.9% am schlechtesten als zu diesem Zielwort gehörig erkannt. Was die Fehlzuordnungen anlangt, so fallen insbesondere zwei Verwechslungen heraus. Zum einen wurden die Langvokale der Zielwörter "gute" und "gehen" oft untereinander verwechselt (22.2% bzw. 16.7%). Zum anderen gab es eine häufige Verwechslung der Langvokale aus "kamen" mit denen aus "kein" (22.2%) und umgekehrt (38.9%).
Um zu bestimmen, welche der 12 Messparameter der Langvokale bei der Vorhersage des Zielwortes eine tragende Rolle spielten, wurden die Werte der standardisierten kanonischen Diskriminanzkoeffizienten für die ersten drei Diskriminanzfunktionen betrachtet. Im Einklang mit der deskriptiven Auswertung in 3.1 und der vorausgegangenen MANOVA waren die Formantlagen von F1 (vgl. Abb. 4) und F3 in der Mitte der Langvokale für die Vokal-Zielwort-Zuordnung weniger wichtig. Gleiches gilt für F0 in der Vokalmitte, den F0-Umfang über dem Langvokal (vgl. Abb. 3a) und die Vokaldauer. F2 in der Vokalmitte spielte indes eine größere Rolle (vgl. Abb. 4). Der größte Beitrag für die Zuordnung der Langvokale zu den Zielwörtern kam jedoch aus dem Umfang und der Dynamik der Transitionen von F1 und F2.
Die Diskriminanzanalyse, die auf die Vorhersage der Region abzielte, hat ebenfalls zu einem signifikanten Ergebnis geführt. Das heißt, über die 12 messphonetischen Eigenschaften der Langvokale konnte auch die Region in überzufällig korrekter Weise vorhergesagt werden (Diskr.-Funk.1-5: Wilks' Lambda=0.284; df=80; p=0.002). Dabei gründete sich die Vorhersageleistung primär auf die ersten beiden kanonischen Diskriminanzfunktionen (1: Eigenwert=0.816; kanon. Korrel.=0.670; 2: Eigenwert=0.480; kanon. Korrel.=0.569). An den Teststatistiken ist bereits abzulesen, dass die Vorhersageleistung der Region insgesamt schwächer war als die des Zielwortes. Entsprechend belief sich die mittlere korrekte Vorhersage der Region anhand der gemessenen Langvokaleigenschaften auf nur 51.9%, was jedoch noch immer erheblich über dem Zufallsniveau von 16.6% liegt. Dabei konnten die Regionen Holstein, Mecklenburg-Vorpommern und vor allem Nordbrandenburg mit 55.6%, 77.8% und 83.3% überdurchschnittlich gute Vorhersageleistungen erzielen. Demgegenüber war die Zuordnung der Langvokale zu den Regionen Dithmarschen, Ostfriesland und Schleswig mit 30–40% nur unterdurchschnittlich erfolgreich.
Im Fazit zu 3.1 wurde festgestellt, dass die 6 Regionen bezüglich des Qualitätsspektrums in der Vokalmitte und des Grades der Diphthongierung über den Vokal hinweg eine Einteilung in drei Gruppen nahe legen, in denen Holstein, Mecklenburg-Vorpommern und Ostfriesland auf einer Seite Nordbrandenburg und Schleswig auf der anderen Seite gegenüberstehen. Die Dithmarscher Langvokale weisen Eigenschaften beider Gruppen auf bilden somit eine weitere, dritte Gruppe, die quasi ein verbindendes Element zwischen den anderen beiden Gruppen darstellt. Die Vorhersageleistungen im Rahmen der Diskriminanzanalyse spiegeln diese Dreiteilung in zweierlei Weise wider. Erstens erreichen die klarsten Vertreter der ersten beiden Gruppen, Mecklenburg-Vorpommern und Nordbrandenburg, mit rund 80% die besten Vorhersageleistungen, während die Vorhersageleistung für die qualitativ intermediären Vokale aus Dithmarschen mit 27.8% am niedrigsten ausfiel. Zweitens wurden die Regionen in stärkerem Maße innerhalb als zwischen den drei Gruppen verwechselt. Beispielsweise entfielen von den rund 20% Fehlvorhersagen für die Region Mecklenburg-Vorpommern 14.4% auf die Regionen Holstein und Ostfriesland. Die knapp 20% Fehlvorhersagen für Nordbrandenburg sind ausschließlich Verwechslungen mit der Region Schleswig geschuldet, und die gut 70% Fehlvorhersagen der Region Dithmarschen verteilen sich in etwa gleichen Teilen von etwas über 10% auf alle anderen 5 Regionen.
Das Fazit zu 3.1 findet weitere Unterstützung in den messphonetischen Parametern der Langvokale, auf denen die Vorhersage der Region im Wesentlichen basierte. Anhand der standardisierten kanonischen Diskriminanzkoeffizienten der ersten beiden Funktionen können die folgenden 5 Langvokaleigenschaften als entscheidend für die Regionszuordnung angesehen werden: F0, F1 und F3 in der Vokalmitte (vgl. Abb. 3b, und Abb. 4) sowie Transitionsumfänge und -dynamiken von F1, F2 und insbesondere F3 (vgl. Abb. 6–7). Die Vokaldauer und der F0-Umfang über dem Vokal spielten eine vergleichsweise untergeordnete Rolle bei der Vorhersage der Region. Gleiches gilt für den F2-Wert in der Vokalmitte, der in stärkerer Weise durch das Zielwort geprägt wurde als F1 und F3 (vgl. 3.2.3 und Abb. 4).
Vor dem Hintergrund der von Heike und Schindler (1970) geforderten, wechselseitigen Fehlerminimierung zwischen auditiven und akustischen Vokalanalysen wurde schließlich noch eine dritte Diskriminanzanalyse durchgeführt. Hierin sollte bestimmt werden, inwieweit die ohrenphonetisch identifizierten Vokalqualitäten aus Tabelle 1 mit Hilfe der akustischen Messungen korrekt vorhergesagt werden konnten. Zum Zwecke dieser Kreuzvalidierung wurden die Vokalqualitäten aus Tabelle 1 entlang des Vokalraumes in vier Gruppen unterteilt, die in Abbildung 8 illustriert sind. Im Falle diphthongierter Langvokale war die initiale, nukleare Qualität für die Gruppenzugehörigkeit maßgeblich. Offene, [ɐ̞]- oder [ɑ̟]-artige Vokale wurden Gruppe 2 zugeordnet.
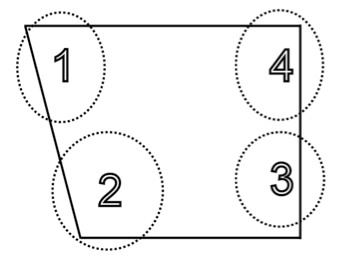
Abbildung 8: Schematische Darstellung der vierfachen Untergliederung des ohrenphonetisch analysierten Vokalraumes aus Tab.1. Die Diskriminanzanalyse zielt darauf ab, die 4 Gruppen aus den 12 akustischen Messparametern korrekt vorherzusagen. Der dargestellte Vokalraum orientiert sich an den primären Kardinalvokalen.
Die Diskriminanzanalyse ergab eine deutlich signifikante und entsprechend überzufällig korrekte Zuordnung der messphonetischen und ohrenphonetischen Gruppen (Diskr.-Funk.1-3: Wilks' Lambda=0.088; df=51; p<0.001), die vor allem auf den ersten beiden kanonischen Diskriminanzfunktionen fußte (1: Eigenwert=3.230; kanon. Korrel.=0.874; 2: Eigenwert= 1.183; kanon. Korrel.=0.736). Die durchschnittliche korrekte Vorhersage der vier ohrenphonetischen Vokalgruppen durch die 12 Messwerte betrug 88.0%, wobei sich alle 4 Gruppen durch gleichermaßen wenige Fehlklassifikationen (0–20%) auszeichneten. Die einflussreichsten akustischen Größen für die Vorhersage der ohrenphonetischen Gruppen waren F2 und in geringerem Umfang auch F1 und F3, jeweils gemessen in der Vokalmitte. Der Einfluss aller anderen Messparameter war praktisch vernachlässigbar. Das heißt, die ohrenphonetische Analyse kann in hohem Maße mit den messphonetisch gewonnenen Formantlagen zur Deckung gebracht werden. Die gemessenen Formantlagen haben eine konsistente auditive Entsprechung und umgekehrt. Diese Parallelen bekräftigen die Validität beider Analysen, insbesondere jedoch die der subjektiveren, ohrenphonetischen Analyse.
Anders als bei Heike und Schindler (1970) kam es also in unserer Studie nicht zu beträchtlichen Diskrepanzen, vor allem nicht zwischen dem ohrenphonetisch transkribierten und dem akustisch (in Form von F1) gemessenen Öffnungsgrad eines Vokals. Die Einteilung und die Vorhersage der vier Vokalgruppen lässt leider keine äquivalente Aussage bezüglich der Diphthongierung zu. Daher wurden diesbezüglich gesonderte t-Test für unabhängige Stichproben durchgeführt. Hierbei zeigte sich klar, dass die mit Diphthongierung transkribierten Langvokale gegenüber den Monphthongen signifikant größere Formanttransitionen in F1 (t=-2.876; df=84; p<0.001) und in F2 (t=4.790; df=84; p<0.001) aufwiesen. Folglich ist auch für diesen Vokalparameter eine eindeutige Korrespondenz zwischen Transkription und Akustik gegeben. Es ist unklar, warum in unserer Studie Transkription und Akustik besser korrespondierten als bei Heike und Schindler (1970). Möglich ist, dass dieser Umstand den seit damals deutlich verbesserten Audiowiedergaben und Signalverarbeitungsmethoden zu verdanken ist.
In der präsentierten Studie ging es um kombinierte, mess- und ohrenphonetische Analysen niederdeutscher Langvokale, basierend auf den Daten von 18 Sprecherinnen, die ausgewählte Wenkersätze gelesen und spontan übersetzt haben. Bei der Auswahl und Vermessung der Sprachdaten wurden einige Einschränkungen vorgenommen, um die Validität der Analysen zu unterstützen. Beispielsweise wurden lediglich die lesesprachlichen Daten solcher Sprecherinnen herangezogen, die ihre Mundart regelmäßig verwenden und sie gemäß Selbsteinschätzungen und Evaluierungen durch fachkundige Interviewer mit mindestens mittlerer Verkehrskompetenz beherrschten. Darüber hinaus wurden die so vorgefilterten Spontanüberseztungen nochmals durch die Erstautorin dahingehend kontrolliert, dass sie auch tatsächlich mit klar erkennbarer Mundarteinfärbung produziert worden waren. Die Wenkersätze selbst wurden so ausgewählt, dass die Analyse der Langvokale in einem koartikulatorisch weitgehend konstanten Kontext stattfinden konnte. Zudem wurden nur wortinitiale Silben berücksichtigt, die, wie die gefundenen F0-Bewegungen bekräftigten, alle mit klaren Satzakzenten realisiert wurden. Auch die Präsupposition, dass alle analysierten Vokale tatsächlich von phonologisch langer Quantität waren, wird durch den Vergleich der gemessenen Vokaldauern mit Referenzwerten aus der Literatur untermauert. Des Weiteren war im Vorfeld bekannt, dass Vokalqualitäten – vor allem bezüglich der für uns wichtigen Parameter Öffnungsgrad und der Grad der Diphthongierung – im Rahmen von Transkriptionen sehr variabel und nicht immer adäquat wiedergegeben werden. Daher wurde prüfstatistisch gezeigt, dass den ohrenphonetischen Beschreibungen der Langvokalqualitäten nahezu perfekt separierbare Formantmuster zugeordnet werden konnten, wobei die Beziehungen zwischen gehörten Vokalqualitäten und gemessenen Formantmustern überdies mit bekannten Bezugspunkten aus der Literatur in Einklang stehen. Insofern stützen sich die mess- und ohrenphonetischen Analysen gegenseitig, und es kann davon ausgegangen werden, dass beide Analysen valide Daten hervorgebracht haben. Zudem wurde jede Region durch drei Sprecherinnen repräsentiert, wodurch das Risiko, etwaige ideolektale Eigenarten als Mundarteigenschaften fehlzuinterpretieren, zumindest geringer ausfiel als in vielen früheren phonetischen Arbeiten.
Insgesamt liegt unseren Analysen somit zwar eine durch die zahlreichen Kontrollmechanismen immer noch recht kleine Datenmenge zugrunde. Diese kann jedoch als belastbar genug angesehen werden, um vor dem Hintergrund der eingangs formulierten Zielsetzungen erste Schlussfolgerungen zu ermöglichen. Welche weiteren Schritte zur Unterstützung und Präzisierung der Schlussfolgerungen unternommen werden müssen, wird im Ausblick skizziert.
Die standarddeutschen Zielwörter in den Wenkersätzen wurden in der Erwartung ausgewählt, dass auch deren Spontanübersetzungen in die jeweilige Mundart ein großes Qualitätsspektrum relevanter Langvokale elizitieren würde. Diese Erwartung findet sich in der Gesamtübersicht über die Messwerte der ersten beiden Formanten F1 und F2 in Abbildung 4 klar bestätigt. Insofern ist es nicht überraschend, dass der Faktor Zielwort in der MANOVA die Varianz in den akustischen Langvokalmesswerten am besten erklären konnte. Die dazugehörige Diskriminanzanalyse konnte auf Basis der Messwerte in 70% aller Fälle korrekt vorhersagen, welches Zielwort zu den jeweiligen Langvokalen gehörte. Diese Vorhersageleistung ist zwar deutlich überzufällig und entsprechend statistisch signifikant. Sie ist aber gleichzeitig weit von 100% entfernt. In dieser Tatsache spiegelt sich die Bedeutung des zweiten Faktors, der Region, wider, der gemäß der MANOVA für sich allein genommen immerhin zu mehr als 55% der Varianz in den akustischen Langvokalmesswerten beigetragen hat und der in der Diskriminanzanalyse mit knapp 52% einen vergleichbar hohen Wert für die Vorhersageleistung der Langvokalqualität erzielte.
Das heißt, es konnten substantielle und multiparametrische phonetische Unterschiede zwischen den Langvokalen in den einzelnen Regionen nachgewiesen werden. Die Fähigkeit dieser multiparametrischen Unterschiede, die 6 untersuchten Regionen so klar zu kennzeichnen, dass sie alle signifikant voneinander trennbar waren, macht es nachvollziehbar, dass die Vokale im metalinguistischen Bewusstsein einen hohen Stellenwert einnehmen und niederdeutsche Sprecherinnen und Sprecher sich über vokalische Charakteristika mit ihren Mundarten identifizieren können, wie es in der Anekdote von Bargstedt (2008; vgl. 1.2.1) eingangs angeklungen ist. Mit anderen Worten: Das niederdeutsche Wort hat über die Mundarten hinweg kein einheitliches Klangbild. Letzteres wird vielmehr in erheblichem Maße durch Variationen in der Vokalqualität mundartenspezifisch geprägt. Es ist kaum vorstellbar, dass entlang einer einzelnen grammatischen Dimension oder eines lexikalischen Paradigmas eine vergleichbare Differenzierbarkeit erreicht werden kann.
Die Langvokalunterschiede können im Sinne der Binneneinteilung als phonetischer Indikator dafür gewertet werden, dass in den einzelnen Regionen jeweils andere Mundarten gesprochen wurden. Daneben fielen ergänzende F-Tests, die zwischen den Sprecherinnen innerhalb jeder Region auf Basis von F0–F3-Lagen und -Umfängen durchgeführt wurden, alle nicht signifikant aus. Die hierin zum Ausdruck kommende Varianzhomogenität innerhalb der Regionen legt nahe, dass die Repräsentatinnen jeder Region eine einheitliche Mundart gesprochen haben. Insofern kann die am Beginn der Analyse eingeführte Trennung von Regionen und Mundarten nun zurückgenommen werden. Das heißt, in Schleswig wurde Schleswigsch gesprochen, in Ostfriesland Ostfriesisch, in Nordbrandenburg Nordmärkisch usw. Nach der kontrastiven Untersuchung von Heike und Schindler (1970) zum Schlesischen hat sich somit erneut gezeigt, dass eine Mundarteneinteilung ausgehend von phonetischen Details prinzipiell möglich und aufschlussreich ist. Phonetische Kriterien könnten sogar ein besonders sensitiver Ansatzpunkt sein. So deutet sich in Dialektstudien wie denen von Herrgen u. a. (2001) und Nerbonne und Siedle (2005) an, dass Dialektmerkmale zwar immer weiter zurückgedrängt werden, vokalische und intonatorische Merkmale von dieser Erosion aber weit weniger betroffen zu sein scheinen als zum Beispiel konsonantische Merkmale oder solche Merkmale, die jenseits des Lautlichen grammatische Aspekte betreffen.
Bezüglich vokalischer Charakteristika hob sich in unserer Studie die Region Dithmarschen von anderen Regionen ab. Dieser Umstand lässt die in der heute gängigen Binneneinteilung vorgesehene Zuordnung zur holsteinischen Mundart fragwürdig erscheinen, da sich auch die holsteinische Region von der Dithmarscher Region in ihren Langvokalproduktionen abgrenzen ließ. Dabei bestehen durchaus Ähnlichkeiten zwischen den Langvokalen beider Regionen. Dithmarschen und Holstein sind zum Beispiel die einzigen beiden Regionen, in denen mess- und ohrenphonetische Analysen das Vorhandensein offener vorderer Vokalqualitäten im Bereich von [æ] angezeigt haben (vgl. Abb.3, Tab.1). Darüber hinaus zeichneten sich Dithmarschisch und Holsteinisch im Vergleich der 6 Mundarten durch die größten Transitionen und Transitionsdynamiken in den ersten drei Formanten F1-F3 aus. Insofern ist es – von grammatischen und lexikalischen Kriterien einmal abgesehen – auch aufgrund der vokalphonetischen Ergebnisse dieser Studie nicht aus der Luft gegriffen, Dithmarschisch und Holsteinisch derselben Mundart zuzuordnen. Auch in der Diskriminanzanalyse wurden die Holsteiner Langvokale am häufigsten mit denen aus Dithmarschen verwechselt. Mit rund 22% stellen die Verwechslungen Holstein-Dithmarschen knapp die Hälfte aller Verwechslungen der Holsteiner Langvokale dar. Der hohe Grad an Dihthongierung und die große Variation in der Lippenrundung, die sich in den umfangreichen und dynamischen F1-F3-Transitionen Dithmarschens und Holsteins widerspiegeln, sind zudem ebenso auditiv saliente Eigenschaften wie [æ]-artige Vokalqualitäten. Es ist daher anzunehmen, dass auch der erste Höreindruck dazu führen würde, Dithmarschen und Holstein nicht zu differenzieren.
Die gefundenen Unterschiede zwischen beiden Regionen sind eher subtilerer Natur. Sie betreffen, anders als zum Beispiel der Kontrast zwischen Dithmarschen und Mecklenburg-Vorpommern, nicht das insgesamt genutzte Spektrum des Parameters Öffnungsgrad, das im F1-Wert zum Ausdruck kommt. Sowohl die Holsteiner als auch die Dithmarscher Sprecherinnen haben deutliche Exemplare offener und geschlossener Vokalqualitäten produziert. Der Unterschied zwischen Dithmarschen und Holstein liegt vielmehr darin, dass die mess- und ohrenphonetischen Ergebnisse ausschließlich für Dithmarschen neben den geschlossenen, hinteren, gerundeten Vokalen (z. B. [u]) auch auf das Vorhandensein geschlossener, vorderer Vokale – gerundet und ungerundet (z. B. [ɪ] und [y]) – hinweisen. Des Weiteren wurden nur für Dithmarschen und nicht für Holstein im Rahmen der offenen Vokale zusätzlich zu den vorderen, [æ]-artigen auch hintere, [ɑ̟]-artige Qualitäten gefunden. Das heißt, Dithmarschen zeigt gegenüber Holstein innerhalb der offenen und geschlossenen Langvokale eine größere Variationsbreite in der horizontalen Zungenposition. Angesichts der kleinen Datenmenge ist zudem darauf hinzuweisen, dass diese Unterschiede im phonetischen Detail zwischen Dithmarschen und Holstein durch die Produktionen aller drei Sprecherinnen gestützt werden, was das Zustandekommen der Unterschiede durch ideolektale Eigenarten ausschließt. Auf dieser Grundlage sind die Befunde dieser Studie als ein erstes, phonetisches Argument dafür zu werten, die Dithmarscher und Holsteiner Sprecherinnen unterschiedlichen, wenngleich einander ähnlichen Mundarten zuzuordnen, wie es Horn (1984) und zuvor bereits Foerste (1957) vorgeschlagen haben. Dithmarscher sprechen also kein Holsteinisch, sondern Dithmarschisch.
Diese Schlussfolgerungen wären noch belastbarer, wenn sie sich auf eine größere Stichprobe stützen könnten, in deren Rahmen es wahrscheinlicher ist, wirklich alle Langvokalphoneme beider Sprachen phonetisch zu erfassen. Daher ist inzwischen bereits eine weitergehende, ohrenphonetische Analyse der Interviewdaten der jeweils drei Dithmarscher und Holsteiner Sprecherinnen in Angriff genommen worden. Vorläufige Resultate sprechen dafür, die Schlussfolgerung bezüglich vorderer, geschlossener Vokale zu relativieren. Auch für die Holsteiner Sprecherinnen wurden in der deutlich erweiterten Datenbasis vordere Vokale wie [i, ɪ] und [y, ʏ] gefunden, allerdings in sehr viel geringerer Zahl als für die Dithmarscher Sprecherinnen und oft nur als Bestandteil von stark diphthongierten Langvokalen. Aus dem kategorischen muss somit ein statistischer Unterschied werden. Hinsichtlich des Vorhandenseins [ɑ̟]-artiger Qualitäten kann der kategoriale Unterschied zwischen Dithmarschen und Holstein indes weiterhin aufrecht erhalten werden (vgl. überdies die F0-Unterschiede in 4.3).
Trotz dieser geringfügig präzisierten Schlussfolgerungen ist es wichtig zu sehen, dass die phonetischen Unterschiede, die sich zwischen Dithmarschisch und Holsteinisch abzeichnen, keineswegs als Unterschiede im Vokalphonemsystem der Mundarten repräsentiert sein müssen. Gleiches gilt für die Unterschiede zwischen allen Mundarten, die nachfolgend in 4.3 resümiert werden. Es kann sich um allophonische Unterschiede innerhalb eines konstanten phonematischen Rahmens handeln. In der Tat gehen viele uns bekannter Studien (vgl. 1.2.1) von einem einzigen Vokalphomensystem aus, das für das Niederdeutsche an sich gültig sein soll. Inwieweit dieses Konzept adäquat ist, führt jedoch über die Fragestellung dieser Pilotstudie hinaus. Angesichts unserer heterogenen Vokaldaten wäre aber in Betracht zu ziehen, die Frage der Vokalphoneme auf empirischem Wege mittels experimental-phonologischer Studien und für jede Mundart einzeln zu klären, anstatt - der Strategie der Laboratory Phonology folgend (vgl. Kohler 2007b) – ein einzelnes a priori am Reißbrett festgelegtes phonologisches System ins Labor zu tragen und dort post hoc mit mundartspezifischer phonetischer Substanz zu füllen. Es ist unserer Ansicht nach wahrscheinlich, dass so ein a priori festgelegtes einheitliches System für einzelne Mundarten über- oder unterspezifiziert ist, was dann unweigerlich zu Systemzwängen in der Projektion phonetischer Substanz auf phonematische Kategorien führen würde. Im Bereich der Vokale sind die für eine Über- bzw. Unterspezifikation anfälligsten Merkmale sicherlich die Differenzierung zwischen Monophthongen und Diphthongen sowie die jeweils binären Qualitäts- und Quantitätsoppositionen. Tatsächlich wurde der Zwang, jede dieser Oppositionen mundartübergreifend mit Substanz füllen zu müssen, bereits von Kohler u. a. (1986a, b) kritisiert und provozierte seinerzeit schwammige Aussagen wie die, dass sich für einige Vokaltripel und Mundarten "die zweifache Qualitäts- und Quantitätsdifferenzierung […] am konsistentesten und ausgeprägtesten" zeigt, während für andere Mundarten und Vokaltripel der Kontrast "verwischt" (Kohler u. a. 1986a: 81 und 1986b: 154), etwa zugunsten einer dreifachen Dauerabstufung oder eines einzelnen, binären Kontrasts.
Die sich in der deskriptiven Auswertung der akustischen und auditiven Analysen herauskristallisierenden Unterschiede zwischen den Langvokalen stehen im Einklang mit den phonetischen Parametern, die auch von den prüfstatistischen Verfahren der MANOVA und der Diskriminanzanalyse als primär relevant für die regionalen Trennungen identifiziert wurden. Hierbei handelt es sich zum einen um F0 in der Vokalmitte. Diese fielen zum Beispiel für die Dithmarscher Sprecherinnen mit etwa 200 Hz besonders niedrig aus (insb. für Frauenstimmen), während sie für die ostfriesischen Sprecherinnen mit im Durchschnitt gut 300 Hz am höchsten lagen. Vor dem Hintergrund, dass die Akzentuierung der Wörter in allen Mundarten durch Tonhöhenakzente mit etwa gleich umfangreichen F0-Gipfeln über der betonten Silbe stattfand (70–80 Hz) und andere Faktoren ausgeschlossen werden konnten (vgl. 3.1), müssen die F0-Unterschiede dadurch zustande gekommen sein, dass die einzelnen Mundarten verschiedene Gestalten und/oder Synchronisationen für ihre F0-Gipfel verwendet haben (vgl. auch Niebuhr 2007). Abbildung 9 stützt diese Schlussfolgerung und zeigt anhand von Produktionen des Wortes "Kohlen" typische Beispiele der Dithmarscher, Holsteiner und der ostfriesischen F0-Gipfel.
Es ist deutlich zu erkennen, dass der ostfriesische F0-Gipfel in etwa mittig über dem Langvokal der Silbe mit und einem plateauartigen Gipfelmaximum realisiert wurde, während der Dithmarscher Gipfel erstens sehr viel spitzer und zweitens stark asynchron zur Vokalmitte platziert worden ist. Genau gesagt, begann der Anstieg zum Gipfel erst nach der Vokalmitte. Die Holsteiner F0-Gipfel stellten eine Art Zwitter dar. Sie verhielten bezüglich ihrer Synchronisation eher wie die ostfriesischen. Das heißt, das Gipfelmaximum wurde um die Vokalmitte herum erreicht. Demgegenüber ist der Gipfel hinsichtlich seiner Gestalt dem spitzen Dithmarscher Gipfel ähnlicher. Neben den vokalischen Unterschieden aus 4.2 sind diese Intonationseigenschaften ein starkes Argument gegen die Integration von Dithmarschisch und Holsteinisch in eine gemeinsame Mundart, da Synchronisationsunterschiede zwischen Akzentgipfeln typischerweise dialektübergreifend auftreten, während sie dialektintern (innerhalb einer konstanten Tonhöhenakzentkategorie) nur sehr gering ausfallen (vgl. Atterer/Ladd 2004). Gleiches gilt für Unterschiede in der Gipfelform. Zusammen genommen lassen beispielsweise die F0-Analysen von Häsler u. a. (2005) und Leemann und Siebenhaar (2008) darauf schließen, dass die Akzentgipfel im Zürichdeutschen nicht nur früher synchronisiert sind als im Berner- und Wallisdeutschen, sondern obendrein durch geringere Gipfelhöhen und flachere Gipfelflanken gekennzeichnet sind.
In diesem Zusammenhang ist es wichtig zu sehen, dass die Synchronisations- und Gestaltunterschiede, wie Abbildung 9 sie für die Dithmarscher und ostfriesischen Intonationsgipfel exemplifiziert, nicht aus Anpassungen der Tonhöhenakzentkategorien an die semantisch-pragmatischen Satzkontexte resultieren können, da das Lesematerial in allen Mundarten identisch war. Das heißt, Abbildung 9 zeigt keine semantisch bedingte (phonologische) Variation (vgl. Niebuhr 2007), sondern eine dialektale Variation.
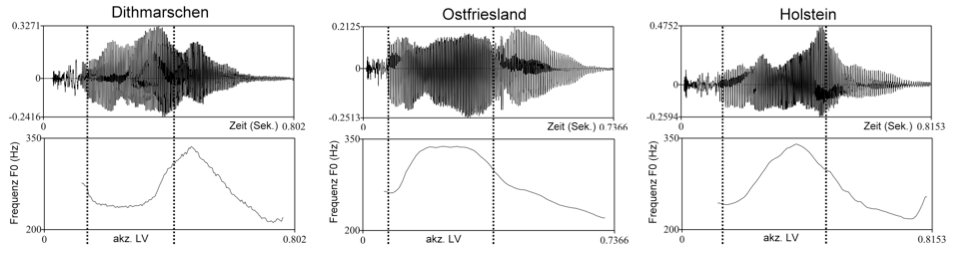
Abbildung 9: Exemplarische Oszillogramme (oben) und F0-Gipfel (200-350 Hz unten) zu Produktionen des Zielwortes "Kohlen" durch je eine Dithmarscher (links), ostfriesische (Mitte) und holsteinische (rechts) Sprecherin. Als Bezugspunkte für die F0-Gipfelformen und -synchronisationen sind die Grenzen des akzentuierten Langvokals (akz. LV) eingezeichnet.
Unter ihren spezifischen intonatorischen Überdachungen manifestierten sich die lautlichen Unterschiede zwischen den Langvokalen der einzelnen Mundarten in den Parametern Öffnungsgrad, Lippenrundung und dem Grad der Diphthongierung. Auf akustischer Seite waren dementsprechend die F1- und F3-Lagen in der Vokalmitte sowie die Transitionsumfänge und -dynamiken aller drei Formanten betroffen. F2-Unterschiede bestanden weniger zwischen den einzelnen Mundarten als vielmehr zwischen den einzelnen Zielwörtern. Die holsteinischen, mecklenburgischen und ostfriesischen Langvokale zeichneten sich insgesamt weniger durch offene oder geschlossene Qualitäten aus. Stattdessen fanden sich für das Holsteinische und das Ostfriesische ausgeprägtere Variationen in der Lippenrundung als in den anderen Mundarten; und das Mecklenburgische war, ebenso wie erneut das Holsteinische, durch einen höheren Grad an Diphthongierung gekennzeichnet. Die nordmärkischen und die schleswigschen Mundarten variierten hingegen eher den Öffnungsgrad. Tabelle 1 zeigt für beide Mundarten folglich nicht eine einzige Diphthongierung, während es für das Holsteinische und Mecklenburgische jeweils mindestens fünf sind. Auf der anderen Seite enthält Tabelle 1 für das Nordmärkische und Schleswigsche mehrfach [u]-, [i]- und [ɑ̞]-Qualitäten, die für das Holsteinische und Mecklenburgische – ebenso wie in Teilen für das Ostfriesische – auf Basis der untersuchten Zielwortstichprobe nicht beobachtet werden konnten. Die Langvokale des Dithmarscher Landschaftsdialekts, der fortan als eigene Mundart behandelt werden soll, wiesen ausgeprägte Variationen entlang aller drei Parameter auf. Sie waren somit phonetisch am vielfältigsten. Zudem hob sich die Dithmarscher Mundart zusammen mit der Holsteiner Mundart durch [æ]-artige Langvokale von allen anderen Mundarten ab. Auf die Unterschiede zwischen den Dithmarscher und Holsteiner Mundarten bezüglich des Vorkommens bzw. der Vorkommenshäufigkeit von [i], [y] und [ɑ̞] wurde in 4.2 bereits im Detail hingewiesen.
Dass sich die niederdeutschen Mundarten im Öffnungsgrad und der Diphthongierung ihrer Langvokale deutlich voneinander unterscheiden, steht im Einklang mit den Befunden aus früheren Studien, die in 1.2.1 zusammengefasst wurden. Öffnungsgradunterschiede standen zum Beispiel schon in den beiden Wortpaaren "hürt" und "führt" vs. "hört" und "föhrt" aus Anekdote von Bargstedt (2008) im Vordergrund. Dass zudem Kohler (1986) vor allem Dithmarscher Gewährsperonen als diphthongierend empfand, passt ebenfalls in unser Ergebnisbild, allerdings ergänzt um den Umstand, dass auch Holsteiner gleichermaßen stark diphthongieren und somit das gesamte südliche Schleswig-Holstein diese Eigenart zeigt. Konform mit frühren Studien geht auch der Umstand, dass alle Diphthongierungen schließender Natur waren, das heißt, von einer offeneren zu einer geschlosseneren Qualität hin führten. In einer größeren Perspektive ist es ferner erwähnenswert, dass Öffnungsgrad und Diphthongierung nicht nur innerhalb des niederdeutschen Sprachgebiets das Klangbild der Wörter einer Mundart prägen. Auch für das schlesischen Sprachgebiet haben sich diese beiden Vokalparameter als besonders mundartenspezifisch herausgestellt (vgl. Heike/Schindler 1970).
Abschließend ist noch hervorzuheben, dass unsere Analysen keine Unterschiede zwischen den Dauern der Langvokale aus den einzelnen Mundarten ergeben haben. Das Ausbleiben solcher Unterschiede ist in einer größeren Perspektive keinesfalls ungewöhnlich. Unter anderem haben auch akustische Analysen zum Schweizerdeutschen Sprachraum ergeben, dass die phonologischen Klassen der Langvokale und Diphthonge sowohl untereinander als auch zwischen Mundarten wie Berndeutsch und Zürichdeutsch nicht unterschiedlich lang ausfallen müssen (vgl. Häsler u. a. 2005). Andererseits wurden für Berndeutsch und Wallisdeutsch Dauerunterschiede gemessen (vgl. Leemann/Siebenhaar 2007). Auch die Ergebnisse früherer Studien zum Niederdeutschen weisen auf Dauerunterschiede hin (vgl. 1.2.1). Diese betreffen allerdings primär den Dauerabstand zwischen phonologischen Lang- und Kurzvokalen. Daher werden unsere nachfolgenden Studien auch die Gruppe der phonologisch kurzen Vokale mit einbeziehen. Diese Erweiterung ist auch deswegen interessant, da erste impressionistische Beobachtungen darauf hindeuten, dass Dauerunterschiede innerhalb der Kurzvokale ein weiteres phonetisches Abgrenzungskriterium zwischen Holsteinisch und Dithmarschisch darstellen könnten. Die holsteinischen Sprecherinnen scheinen Kurzvokale mit etwas größerer Dauer zu produzieren als die Dithmarscher Sprecherinnen. Für die schleswigschen Sprecherinnen zeichnen sich innerhalb der 6 Mundarten die kleinsten Kurzvokaldauern ab. Dadurch, dass unsere Ergebnisse keine signifikanten Dauereffekte aufweisen, sind ferner die deutlichen Unterschiede in den Transitionsdynamiken der Formanten allein auf deren signifikant unterschiedliche Transitionsumfänge zurückführbar (Dynamik wurde aus der Division von Umfang/Dauer berechnet). Es gab keine Fälle, in denen Unterschiede in der Transitionsdynamik daraus resultierten, dass sich vergleichbar umfangreiche Formanttransitionen über unterschiedliche Vokaldauern erstreckten. Ebenfalls kam es nicht vor, dass aus kleinen und prüfstatisch einzeln nicht abbildbaren Unterschieden in Vokaldauern und Formanttransitionen größere und statistisch signifikante Formantdynamikunterschiede entstanden. Die Unterschiede in den Transitionsumfängen und -dynamiken der Formanten wurden daher in den vorangegangenen Ausführungen zusammenfassend behandelt und nicht gesondert diskutiert sowie in ihren jeweiligen Implikationen für die Wahrnehmung von Diphthongierung nicht einzeln interpretiert.
Was die Implikationen unserer Studie für die Einteilung niederdeutscher Mundarten und Mundartgruppen anlangt, so wurden die Argumente für eine Ausgliederung des Dithmarschischen als eigene Mundart zusätzlich zur holsteinischen Mundart bereits in 4.2 und 4.3 eingehend diskutiert. Des Weiteren wurde darauf hingewiesen, dass Vergleiche innerhalb der drei Sprecherinnen jeder Region keine Anzeichen für eine weitere Ausdifferenzierung der Mundarten ergeben haben. Bezüglich der weiteren, in 1.2.2 aufgeworfenen Fragen zur Binneneinteilung können wir Folgendes festhalten. Unsere Ergebnisse lassen keine eindeutige Abgrenzung der west- und ostniederdeutschen Dialekträume anhand der untersuchten phonetischen Langvokalunterschiede zu. Weder in den F0- noch in den Formantmustern gab es Eigenschaften, die für die schleswigschen, holsteinischen, Dithmarscher und ostfriesischen Mundarten auf der einen Seite und für die mecklenburgischen und nordmärkischen Mundarten auf der anderen Seite kennzeichnend waren. Wenn überhaupt, dann fällt am ehesten noch der F3-Transitionsumfang ins Auge, der für die ostniederdeutschen Mundarten Mecklenburgisch und Nordmärkisch durchschnittlich weniger ausgeprägt war als für die übrigen, westniederdeutschen Mundarten. Das heißt, Variation in der Lippenrundung spielt in den westniederdeutschen Mundarten tendenziell eine größere Rolle als in den ostniederdeutschen. Dies ist auch mit ein Grund dafür, dass in der Diskriminanzanalyse die ostniederdeutschen Mundarten anhand ihrer Langvokale am besten erkannt wurden, während die westniederdeutschen Mundarten anhand ihrer Langvokale weitgehend untereinander und so gut wie gar nicht mit den ostniederdeutschen Mundarten verwechselt wurden. Auf dieser Basis lohnt es sich, Hinweisen auf phonetische Charakteristika ganzer Dialekträume intensiver nachzugehen.
Des Weiteren haben die Langvokalproduktionen im Vergleich der schleswig-holsteinischen Mundarten (aus den Regionen Schleswig, Holstein und Dithmarschen) keine erkennbar größeren Ähnlichkeiten aufgewiesen als im Gesamtvergleich über alle Mundarten. Allenfalls zwischen den Dithmarscher und Holsteiner Mundarten wurden einige markante Ähnlichkeiten und prüfstatistische Verwechslungen (in 22% der Fälle) gefunden. Die schleswigsche Mundart hingegen wurde nicht mit der Holsteiner oder Dithmarscher, sondern – im Einklang mit den deskriptiven Befunden – mit der ostfriesischen Mundart am häufigsten verwechselt (in rund 17% der Fälle). Damit lässt das Gesamtbild der Ergebnisse nicht die Schlussfolgerung zu, dass die vergleichsweise hohe Mundartendichte in Schleswig-Holstein über die Zeit hinweg zu größeren sprachkontaktbedingten Ähnlichkeiten im Vokalismus geführt hat.
Was die Besonderheit des friesischen Substrats im Ostfriesischen betrifft, so haben sich diesbezüglich ebenfalls keine Alleinstellungsmerkmale in den Langvokalproduktionen herauskristallisiert. Im Gegenteil, das Ostfriesische ließ auf Basis unserer Daten nur wenig von den variantenreichen Vokalproduktionen erkennen, die zumindest für einige Varietäten des Friesischen charakteristisch sind (vgl. Bohn 2004). Bemerkenswert ist allerdings, dass das Ostfriesische gegenüber den anderen Mundarten in intonatorischer Hinsicht durch einen besonders hohen Durchschnittswert für F0 in der Vokalmitte auffiel. Dies ist umso interessanter, als dass intonatorische Analysen der friesischen Inselvarietäten Fering und Öömrang (gesprochen auf Föhr bzw. Amrum, vgl. Bohn 2004) Ähnliches gezeigt haben. Konkret sind die F0-Gipfel über den betonten Silben in Fering und Öömrang typischerweise durch deutliche Hochplateaus zwischen An- und Abstieg gekennzeichnet (Fuß 2011). Plateauförmige F0-Gipfel sind im Vergleich zu anderen Dialekten und Sprachen auf nationaler und internationaler Ebene eine sehr seltene Eigenschaft, die zum Beispiel im Standarddeutschen sowie im Britischen Englisch vor allem als Folge von emphatischer Hervorhebung anzutreffen ist (vgl. Niebuhr 2010). Unterstützt durch zusätzliche mess- und ohrenphonetische Stichproben, scheint das Ostfriesische diese seltene intonatorische Eigenschaft als Standardrealisierung für F0-Gipfel mit Fering und Öömrang zu teilen (vgl. auch Abb.9). Weitere Studien sollten diese Möglichkeit eingehender prüfen. Hierbei sollte ferner mit einbezogen werden, dass Zwirner u. a. (1956) auf Zusammenhänge zwischen dem Grad der Diphthongierung und den Verlaufseigenschaften von Intonationsgipfeln hinweisen.
Ganz in Sinne einer Pilotstudie hat unser Beitrag erste Schlussfolgerungen zu Antworten auf Fragen der vokalischen Unterschiede zwischen niederdeutschen Mundarten und ihrer Implikationen hinsichtlich der existierenden Binneneinteilung geben können, dabei jedoch auch eine ganze Reihe weiterer Forschungsperspektiven aufgezeigt. Die offensichtlichste Forschungsperspektive betrifft den Umfang bzw. die Repräsentativität der untersuchten Daten. In 4.1 wurden zwar eine Reihe von Argumenten für die Belastbarkeit der analysierten Daten ins Feld geführt. Dennoch müssen nachfolgende Studien auf einer größeren Datenbasis mit mehr Zielwörtern und Gewährspersonen pro Region/Mundart beruhen und dabei idealerweise auch über Lesesprache hinausgehen. Letzteres ist zum einen nötig, weil Lesesprache in Bezug der Alltagskommunikation immer als weniger repräsentativ für die Ausprägung phonetischer Muster angesehen werden muss als Spontansprache. Zum anderen ist insbesondere in der Dialektforschung unklar, inwieweit die standarddeutsche Orthographie beim Ablesen mit den intendierten Mundartproduktionen interferiert. Was die Gewährspersonen anlangt, so wurden die in unsere Daten eingegangenen Sprecherinnen auf der Basis von Sprachtests, Selbsteinschätzungen und einer auditiv-impressionistischen Beurteilung durch die erste Autorin zwar mehrfach auf ihre homogene Mundartenkompetenz hin gefiltert. Zudem konnten keine systematischen Unterschiede innerhalb der Sprecherinnen einer Mundart gefunden werden. Trotzdem werden in Tabelle 1 und in den Standardabweichungen einiger Messparameter ideolektale Einflüsse erkennbar, die durch eine größere Personenstichprobe noch weiter in den Hintergrund gedrängt werden müssen. Um die phonetischen Detailbeschreibungen niederdeutscher Mundarten voranzubringen, bedarf es zudem der Aufnahme zusätzlicher Gewährspersonen unter Studiobedingungen. Die im Rahmen des DFG-Projektes 'Sprachvariation in Norddeutschland' entstandenen und dieser Studie zugrundegelegten Interviewdaten sind qualitativ sehr variabel und insgesamt für messphonetische Zwecke nur begrenzt brauchbar.
Über diese generellen methodischen Aspekte hinaus legt unsere Studie eine weitere Vertiefung der folgenden Forschungsperspektiven nahe:
Ob sich multiparametrisch-vergleichende Studien zu den Konsonanten des Niederdeutschen ebenfalls lohnen, ist zwar prinzipiell offen, darf aufgrund der Bemerkungen von Panzer und Thümmel (1971: 46; vgl. 1.2.1) sowie der anschließenden empirischen Studien von Herrgen u. a. (2001) und Nerbonne und Siedle (2005) jedoch infrage gestellt werden.
Atterer, Michaela/Ladd, Robert D. (2004): "On the phonetics and phonology of "segmental anchoring" of F0: evidence from German". Journal of Phonetics 32: 177–197.
Bargstedt, Stefan (2008): Platt – Wo und wie Plattdeutsch ist. Bremen: Schünemann.
Berkovits, Rochelle (1993): "Progressive utterance-final lengthening in syllables with final fricatives". Language and Speech 36: 89–98.
Bohn, Ocke-Schwen (2004): "How to organize a fairly large vowel inventory: the vowels of Fering (North Frisian)". Journal of the International Phonetic Association 34: 161–173.
Braak, Ivo (1956): Niederdeutsch in Schleswig-Holstein. Kiel: Hirt.
Cambier-Langeveld, Tina/Nespor, Marina/van Heuven, Vincent J. (1997): "The domain of final lengthening in production and perception in Dutch". Kokkinakis, George u. a. (Hrsg.):: Proc. 5th European Conference on Speech Communication and Technology, EUROSPEECH, Rhodos, Griechenland: 931–934.
Cruttenden, Alan (1997): Intonation. Cambridge: Cambridge University Press.
de Jong, Kenneth (1995): "The supraglottal articulation of prominence in English: linguistic stress as localized hyperarticulation". Journal of the Acoustical Society of America 97: 491–504.
Dellwo, Voker/Ferragne, Emmanuel/Pellegrino, François (2006): "The perception of intended speech rate in English, French, and German by French speakers". Hoffmann Rüdiger/Mixdorff, Hansjörg (Hrsg):Proc. 3rd International Conference of Speech Prosody, Dresden, Deutschland: 101–104.
Foerste, William (1957): "Geschichte der niederdeutschen Mundarten". In: Stammler, Wolfgang (Hrsg.): Deutsche Philologie im Aufriss, Bd. I. Berlin, Erich Schmidt: 1730–1898.
Huf, Rike (2011): Intonatorische Merkmale des Fering-Öömrang. Magisterarbeit in Analyse gesprochener Sprache, Christian-Albrechts-Universität zu Kiel.
Goltz, Reinhard (2009): "Niederdeutsch: vom wenig einheitlichen Profil einer bedrohten Regionalsprache". In: Stolz, Christel (Hrsg.): Neben Deutsch: die autochthonen Minderheiten- und Regionalsprachen Deutschlands. Bochum, Brockmeyer: 59–86.
Harrington, Jonathan/Cassidy, Steve (1999): Techniques in Speech Acoustics. Dordrecht: Kluwer Academic Press.
Häsler, Katrin/Hove, Ingrid/Siebenhaar, Beat (2005): "Die Prosodie des Schweizerdeutschen - Erkenntnisse aus der sprachsynthetischen Modellierung von Dialekten". Linguistik Online 24: 187–224.
Heike, Georg/Schindler, Frank (1970): "Versuche zur Dialektgeographie akustisch-phonetischer Messwerte am Beispiel schlesischer Mundartaufnahmen". Zeitschrift für Dialektologie und Linguistik 37: 26–43.
Herrgen, Joachim u. a.(2001): Dialektalität als phonetische Distanz: Ein Verfahren zur Messung standarddivergenter Sprechformen. Verfügbar unter: http://archiv.ub.uni-marburg.de/es/2008/0007/, Stand: 6. Juni 2012.
Hildebrandt, Bruno (1963): Experimentalphonetische Untersuchungen zur Bestimmung und Wertung der 'durativen Funktion' akzentuierter Vokale im Nordniedersächsischen. PhD Disseration der Universität Hamburg.
Hillenbrand, James u. a. (1995): "Acoustic characteristics of American English vowels". Journal of the Acoustical Society of America 97: 3099–3111.
Hoole, Philipp/Nguyen-Trong, Noel/Hardcastle, William (1993): "A comparative investigation of coarticulation in fricatives: electropalatographic, elctromagnetic and acoustic data". Language and Speech 36: 235–260.
International Phonetic Association (1999): Handbook of the International Phonetic Association. Cambridge: Cambridge University Press.
Kohler, Klaus J. (1982): "Rhythmus im Deutschen". 19: 89–105.
Kohler, Klaus J. (1983): "Prosodic boundary signals in German". Phonetica 40: 89–134.
Kohler, Klaus J. (1986): "Überlänge und Schleifton im Niederdeutschen – Zusammenfassung der Ergebnisse aus vier Dialektuntersuchungen". AIPUK 23: 5–18.
Kohler, Klaus J./Tödter, Regina/Weinhold, Michael (1986a): "Ergänzende Untersuchungen zur 'Überlänge' in der Mundart Hassmoor (Kreis Rendsburg-Eckernförde)". AIPUK 23: 19–116.
Kohler, Klaus J./Tödter, Regina/Weinhold, Michael (1986b): "Untersuchungen zur 'Überlänge' in den Mundarten von Brarupholz (Kreis Schleswig-Flensburg) und Windbergen (Kreis Dithmarschen)". 23: 117–177.
Kohler, Klaus J. (2007a): "Heterogeneous exponents of homogeneous prososodic categories - The case of dialectal variability of pitch contour synchronization with articulation. Beitrag in "Standard Prosody or Prosody of Lingusitic Standards? Prosodic Variation and Grammar Writing". 29. Jahrestagung der Deutschen Gesellschaft für Sprachwissenschaft, Siegen, Deutschland. Verfügbar unter: http://www.ipds.uni-kiel.de/kjk/forschung/lautmuster.de.html, Stand 6. Juni 2012 .
Kohler, Klaus J. (2007b): "Beyond Laboratory Phonology: The Phonetics of Speech Communication". In: Solé/Maria-Josep/Beddor, Patrice/Ohala, Manjari (Hrsg.): Experimental Approaches to Phonology. Oxford, Oxford University Press: 41–53.
Ladefoged, Peter (1996): Elements of acoustic phonetics. Chicago: University of Chicago Press.
Lameli, Alfred (2004): "Hierarchies of dialectal features in a diachronic view – implicational scaling of real time data". Proc. 2nd Int. Conf. Language Variation in Europe, Uppsala, Schweden: 253–266.
Leemann, Adrian/Siebenhaar, Beat (2006): "Prosodic features of spontaneous utterance-initial phrases in Bernese and Valais Swiss-German". Proc. International Symposium on Linguistic Patterns in Spontaneous Speech, Tapei, Taiwan: 127–142.
Leemann, Adrian/Siebenhaar, Beat (2007): "Intonational and temporal features of Swiss German". Trouvain, Jürgen/Barry, William (Hrsg):Proc. 16th International Congress of Phonetic Sciences, Saarbrücken, Deutschland: 957–960.
Leemann, Adrian/Siebenhaar, Beat (2008): "Swiss Alpine and Midland Intonation" .Barbosa, P . u. a. (Hrsg): Proc. 4th International Conference of Speech Prosody, Campinas, Brasilien: 289–292.
Lehiste, Ilse (1970): Suprasegmentals. Cambridge, MA: MIT Press.
Lenz, Philipp (1900): "Unsere Lautschrift". Zeitschrift für hochdeutsche Mundarten 1: 6–8.
Markel, John D./Gray, Augustine Jr. (1976): Linear Prediction of Speech. Berlin: Springer.
Möbius, Bernd/van Santen, Jan (1996): "Modeling segmental duration in German text-to-speech synthesis". Proc. 4th International Conference on Spoken Language Processing, Philadelphia, USA: 2395–2398.
Möller, Frerk (1997): "Plattdüütsch – een Spraak stellt sik vör". Schriften des Instituts für Niederdeutsche Sprache 19: 1–46.
Nerbonne, John/Siedle, Christine (2005): "Dialektklassifikation auf der Grundlage aggregierter Ausspracheunterschiede". Zeitschrift für Dialektologie und Linguistik 72: 129–147.
Niebuhr, Oliver (2007): "The signalling of German rising-falling intonation categories - The interplay of synchronization, shape, and height". Phonetica 64: 174–193.
Niebuhr, Oliver (2010): "On the phonetics of intensifying emphasis in German". Phonetica 67: 170–198.
o. A. (2007): "Deutsch: Die deutschen und niederländischen Dialekte nach dem Jahr 1945". http://de.wikipedia.org/wiki/Datei:Deutsche_Dialekte.PNG, Stand 11. Juni 2012.
Panzer, Baldur/Thümmel, Wolf (1971): "Die Einteilung der niederdeutschen Mundarten auf Grund der strukturellen Entwicklung des Vokalismus". In: Baumgärtner, Klaus/von Polenz, Peter/Steger, Hugo (Hrsg.): Linguistische Reihe 7. München, Max Hueber: 1–200.
Pätzold, Matthias/Simpson, Adrian P. (1997): "Acoustic analysis of German vowels in the Kiel Corpus of Read Speech". AIPUK 32: 215–247.
Peters, Bruno/Kohler, Klaus J./Wesener, Thomas (2005): "Phonetische Merkmale prosodischer Phrasierung in deutscher Spontansprache". AIPUK 35a: 143–184.
Peters, Jörg (2006): Intonation deutscher Regionalsprachen. Berlin/New York: Walter de Gruyter.
Reershemius , Gertrud (2004): "Niederdeutsch in Ostfriesland". Zeitschrift für Dialektologie und Linguistik 119, Beiheft: 1–193.
Sanders, Willy (1982): Sachsensprache, Hansesprache, Plattdeutsch. Sprachgeschichtliche Grundzüge des Niederdeutschen. Göttingen: Vandenhoeck & Ruprecht.
Sawusch, James R. (1996): "Effects of duration and formant movement on vowel perception". Proc. 4th International Conference on Spoken Language Processing, Philadelphia, USA: 2482–2485.
Scheffers, Michel/Thon, Werner (1991): "Workstation and signal processing software for experimental phonetics". Proc. 12th International Congress of Phonetic Sciences, Aix-en-Provence, Frankreich: 486–489.
Schröder, Ingrid (2004): "Niederdeutsch in der Gegenwart. Sprachgebiet - Grammatisches - Binnendifferenzierung". In: Stellmacher, Dieter (Hrsg.): Niederdeutsche Sprache und Literatur der Gegenwart. Hildesheim: Olms: 35–97.
Scott, Sophie K. (1998): "The point of P-centres". Psychological Research 61: 4–11.
Simpson, Adrian P. (1998): "Phonetische Datenbanken des Deutschen in der empirischen. Sprachforschung und der phonologischen Theoriebildung". AIPUK 33: 1–233.
Simpson, Adrian P. (2009): "Phonetic differences between male and female speech". Language and Linguistics Compass 3: 621–640.
Speyer, Augustin (2010): Deutsche Sprachgeschichte. Göttingen: Vandenhoeck & Ruprecht.
Sproat, Richard/Fujimura, Osamu (1993): "Allophonic variation in English /l/ and its implications for phonetic implementation". Journal of Phonetics 21: 291–311.
Stellmacher, Dieter (1981): Stellmacher, Dieter (1981): Niederdeutsch. Formen und Forschungen. Tübingen: Niemeyer.. Tübingen: Niemeyer.
Stellmacher, Dieter (2005): "Die Einheit der Vielfalt. Die heutige Binnengliederung des Niederdeutschen". In: Arendt, Birt/ Lippman, Enrico (Hrsg.): Die Konstanz des Wandels im Niederdeutschen. Politische und historische Aspekte einer Sprache. Hamburg, Kovač: 127–137.
Strange, Winfried/Bohn, Ocke-Schwen (1998): "Dynamic specification of coarticulated German vowels: Perceptual and acoustical studies". Journal of the Acoustical Society of America 104: 488–504.
Syrdal, Ann K./Gopal, H. S. (1986): "A perceptual model of vowel recognition based on auditory representation of American English vowels". Journal of the Acoustical Society of America 79: 1086–1100.
Tödter, Regina (1982): "Phonetische Untersuchungen zur Vokaldauer in einem niederdeutschen Dialekt." AIPUK 17: 49–93.
Turk, Alice E./Shattuck-Hufnagel Stefanie (2007) "Multiple targets of phrase-final lengthening in American English words." Journal of Phonetics 35: 445–472.
Wenker, Georg (1881): Sprach-Atlas von Nord- und Mitteldeutschland. Strassburg/London: K.J. Trübner.
Wiesinger, Peter (1964): "Das phonetische Transkriptionssystem der Zeitschrift "Teuthonista"". Zeitschrift für Mundartforschung 31: 1–20.
Wiesinger, Peter (1970): Phonetisch-phonologische Untersuchungen zur Vokalentwicklung in den deutschen Dialekten. Bd. 1: Die Langvokale im Hochdeutschen. Berlin/New York: Walter de Gruyter.
Zwirner, Eberhard/Zwirner, Kurt (1936): Grundfragen der Phonometrie. Berlin: Metten.
Zwirner, Eberhard/Maack, Adalbert/Bethge, Wolfgang (1956): "Vergleichende Untersuchungen über konstitutive Faktoren deutscher Mundarten". Zeitschrift für Phonetik und Allgemeine Sprachwissenschaft 9: 14–30.
* Die Autoren möchten insbesondere Dr. Viola Wilcken (Germanistik, Universität Kiel), Dr. Alexander Werth (Deutscher Sprachatlas, Marburg) und Dr. Felicitas Kleber (IPS, Universität München) und zwei anonymen Gutachtern für die vielen anregenden Diskussion und Vorschläge danken, die in den Beitrag eingeflossen sind. Besonderer Dank gilt ferner Herrn Prof. Dr. Michael Elmentaler und dem Germanistischen Seminar der Universität Kiel für die Bereitstellung des verwendeten Sprachmaterials. zurück
1 European Treaty Series – No. 148: 2: "regional or minority languages means languages that are: (i) traditionally used within a given territory of a State by nationals of that State who form a group numerically smaller than the rest of the State's population; and (ii) different from the offcial language(s) of that State; it does not include either dialects of the official language(s) of the State or the languages of migrants;[...]". zurück
2 Im Falle von "verkaufen" hat die Artikulationsart des Lautes zwischen Plosiv und Frikativ variiert; der Artikulationsort war jedoch konsistent labial. zurück
3 Editiert nach Wikipedia-Quelle (http://de.wikipedia.org/wiki/Datei:Deutsche_Dialekte.PNG). zurück
{kind=link}