http://dx.doi.org/10.13092/lo.78.2951
Si l’importance de l’enseignement aux LNN1 des structures « courantes »2 n’est plus mise en doute en didactique du FLE, les grands corpus informatisés, comme source de données linguistiques, ne sont pas encore très exploités. Les données empiriques apparaissent en effet quelque peu négligées dans les manuels, juste parfois annexées à différentes étapes de l’acquisition du vocabulaire et à l’expression orale ou écrite, par exemple. Pourtant, depuis quelques années, des linguistes comme Novakova et Tutin (2009), Diwersy et François (2011), Tutin et Grossmann (2014) et Cavalla et al. (2015), entre autres, préconisent l’utilisation des grandes bases de données telles que Frantext (www.atilf.fr/spip.php?rubrique78, [04.09.2015], textes littéraires du XVIe au XXe siècle), Scientext (http://scientext.msh-alpes.fr/scientext-site/spip.php?article9, [04.09.2015], textes scientifiques de la fin du XIXe au début du XXIe siècle) et Emolex (http://emolex.u-grenoble3.fr/emoConc/emoConc.new.php, [04.09.2015], textes journalistiques du début du XXIe et textes littéraires de la fin du XIXe au début du XXIe siècle), comme corpus pour l’enseignement et l’apprentissage dans une classe de langue. Selon les auteurs, le bénéfice acquis par la constitution des concordances informatisées est double : d’une part le recours à des corpus fournissant des données empiriques variées et attestées permet de faire une description réaliste de l’environnement de la lexie, d’autre part, il trace son usage.
Il n’en demeure pas moins que dans le cas des collocations3 d’émotions, les manuels de FLE ne présentent que rarement des exemples authentiques; ils limitent souvent leur choix à quelques expressions figées ou aux collocations bien connues comme « procurer du bonheur », « faire plaisir » ou « entrer dans une colère noire », et ceci uniquement au niveau avancé en français (Cavalla/Labre 2009). Les manuels ne précisent pas non plus que les collocations d’émotions peuvent avoir des formes et des structures très variables, comme c’est le cas de la construction V causatif + N d’émotion (désormais Vcaus + N_émot).
En partant de l’étude de la fréquence4 des différents mécanismes causatifs que nous classons selon des critères syntaxico-sémantiques (Dixon 2000 ; Talmy 2000 et Diwersy/François 2011) et en nous fondant sur la variété des formes et des structures telles qu’elles peuvent être observées empiriquement dans le corpus (corpus Emolex), nous cherchons à établir les attirances entre ces deux classes grammaticales (les Vcaus et les N_émot). Un deuxième objectif consiste à chercher à répondre à l’interrogation suivante : quelles collocations enseigner ?
Nous présenterons d’abord les hypothèses de notre recherche, ainsi que la méthodologie de la constitution du corpus d’étude et de l’analyse linguistique (section 2). Ensuite, nous étudierons la répartition des collocatifs verbaux au sein des différents champs d’émotions de la classification d’Emolex (section 3) et présenterons une analyse lexicale de la collocation la plus fréquente de tous les champs : créer DET surprise (section 4). Nous réfléchirons ensuite aux critères de sélection des collocations, pertinentes du point de vue des finalités didactiques, pour passer enfin aux conclusions.
Nous essaierons d’apporter des éléments de réponses aux questions suivantes sous-tendant cette recherche :
A partir de ces interrogations, nous formulons les hypothèses suivantes :
Deux théories seront utilisées conjointement ici: la conception des collocations statistiquement significatives de Williams (2003) qui mentionne que même si la fréquence ne sert qu’à évaluer les collocations, elle fournit des informations sur leur usage9 et la théorie de la disponibilité lexicale de Hausmann (1985)10. En effet, comme nous l’avons signalé supra pour Hausmann, le critère de fréquence n’est pas toujours pertinent car la collocation peut être usuelle mais pas forcément fréquente en fonction du corpus considéré. Hausmann (1985) mentionne ainsi „Viele Kollokationen sind nicht frequent, aber dennoch verfugbar“. (Il existe un nombre important de collocations qui, bien que leur fréquence soit peu élevée, restent disponibles à l’usage)11 (cf. Hausmann 1985: 124). Dans la même lignée, Tutin (2005a) remarque que certaines lexies ou combinaisons peuvent être fréquentes, mais uniquement en contexte particulier, comme la fourchette qui risque de n’apparaitre que dans le contexte alimentaire ou les collocations partager DET haine, porter DET haine qui sont liées aux situations de conflit12.
Les données sont issues du corpus Emolex (http://emolex.u-grenoble3.fr/emoBase, [20.06.2015]). Il s’agit d’une base de données contenant environ 150M de mots dont 134M de mots provenant de textes journalistiques (deux années de parution : 2007–2008) des quatre quotidiens français Le Monde, Ouest-France, Libération et Le Figaro et 16M provenant de textes littéraires sur la période XIXe-XXe siècle.
Le Tableau 1 recense la provenance, la nature, ainsi que la taille des corpus pour la langue française :
|
Nom du corpus |
Période |
Mots-occurrences |
Genre |
|
Le Monde (presse nationale) |
2007–2008 |
45 527 166 |
journalistique |
|
Ouest-France (presse nationale) |
2007–2008 |
30 998 093 |
journalistique |
|
Le Figaro (presse nationale) |
2007–2008 |
40 547 032 |
journalistique |
|
Libération (presse nationale) |
2007–2008 |
20 322 010 |
journalistique |
|
Littérature française contemporaine |
1950–2000 |
15 978 230 |
littéraire |
|
TOTAL |
153 372 531 |
Tableau 1 : Descriptif du corpus français (Emolex)
La méthodologie employée s’inscrit dans la linguistique du corpus. Elle cherche à mettre en évidence les attirances entre les Vcaus et les N_émot en se basant sur des textes authentiques dont le paramètre log-likelihood (abrégé LL) (Manning/Schütze 1999) sert à cibler les collocations usuelles et fréquentes. Notre analyse recourt en outre à neuf champs d’émotion de la classification d’Emolex13 et à notre liste de 106 Vcaus (détaillée dans la suite de cette section).
Les méthodes lexico-statistiques (Diwersy/François 2011) nous ont permis d’élaborer les profils combinatoires des N_émot et de formuler ainsi des généralisations. Nous avons procédé par étapes : d’abord, nous avons fait une analyse quantitative qui consistait en un examen systématique des occurrences pour chacun des N_émot étudiés, ensuite, nous avons affiné notre analyse en effectuant des recherches ponctuelles sur des lexies considérées comme pertinentes (fréquence, typicité...). À partir des régularités repérées, nous avons effectué des listes des combinaisons ainsi que des tableaux synthétiques et comparatifs.
Sélectionnés dans le cadre du projet Emolex14, les 46 N_émot ont été répartis de la façon suivante :
Les champs sont diversifiés sur le plan de la polarité : ADMIRATION, par exemple, a une polarité positive, COLÈRE négative, tandis que SURPRISE est neutre (Grutschus/Kern/Tutin 2013) et, également, par rapport au caractère réactif/interpersonnel des affects : les champs comme COLÈRE, DÉCEPTION, JOIE, SURPRISE, TRISTESSE sont réactifs, c’est-à-dire qu’ils impliquent un expérienceur plutôt qu’un agent, tandis que ADMIRATION, JALOUSIE, RESPECT, MÉPRIS sont interpersonnels, c’est-à-dire qu’ils se dirigent prototypiquement vers un patient (Tutin et al. 2006).
Les champs sémantiques ne sont pas équilibrés au niveau du nombre de noms recueillis : dans certains d’entre eux, il y en a moins, à cause des critères de fréquence et de sélection retenus (par exemple, le champ COLÈRE comprend dix N_émot, tandis que celui JALOUSIE n’en a que trois). Toutes nos fréquences sont donc calculées en pourcentages.
En ce qui concerne la méthodologie de notre analyse linguistique, nous avons d’abord procédé à la création d’une liste de verbes causatifs. La liste de 120 Vcaus établie dans le cadre de notre Master 215 pour le corpus Scientext (http://scientext.msh-alpes.fr/scientext-site/spip.php?article9, [05.05.2015]) nous a servi de point de départ. Nous l’avons vérifiée dans le corpus Emolex en appliquant notre patron syntaxique Vcaus + N_émot: 106 verbes causatifs ont été répertoriés au total. A partir de cette liste pré-établie, nous avons classé le lexique verbal causatif selon la typologie de Diwersy et François (2011)16.
Le Tableau 2 illustre cette classification. Certaines classes comme la classe de « causation négative » et la classe de « décroissance » ont été reprises du classement de Diwersy et François (2011). Etant donné le nombre important de Vcaus se trouvant dans notre liste, nous nous limitons, dans le tableau 2, à quelques verbes parmi les plus représentatifs pour chaque classe :
|
|
C. verbale |
N_émot |
|
C1 |
Vcaus neutres (au total: 29 V) |
créer (stupeur), donner (plaisir), provoquer (indignation), réserver (surprise), susciter (admiration) [...] |
|
C2 |
V de causation négative (au total: 14 V) |
apaiser (ire), adoucir (fureur), entamer (enthousiasme), freiner (enthousiasme), réduire (fascination) [...] |
|
C3 |
Vcaus phasiques inchoatifs (au total: 18 V) |
déchaîner (jalousie), déclencher (stupeur), exciter (fureur), réveiller (nostalgie), soulever (enthousiasme) [...] |
|
C4 |
Vcaus phasiques terminatifs (au total: 9 V) |
chasser (tristesse), étouffer (colère), éteindre (émerveillement), effacer (déception), gâcher (plaisir) [...] |
|
C5 |
Vcaus phasiques d’intensité forte (croissance graduelle) (au total: 22 V) |
alimenter (colère), attiser (jalousie), décupler (colère), nourrir (émerveillement), prolonger (plaisir) [...] |
|
C6 |
Vcaus phasiques d’intensité faible (décroissance graduelle) (au total: 14 V) |
atténuer (regret), calmer (euphorie), canaliser (colère), modérer (enthousiasme), tempérer (euphorie) [...] |
|
|
Au total: 6 classes |
106 Vcaus |
Tableau 2 : Proposition de classement des Vcaus17
Au premier palier se trouve la classe des « Vcaus neutres » qui réunit au total 29 verbes et qui correspond aux verbes tels que causer ou exercer :
(Frédéric Dard 1991)
2) L’horreur nous révulse en même temps qu’elle exerce sur nous une certaine fascination.
(Ouest-France 2008)
Cette classe est suivie de la classe des « V de causation négative » avec au total 14 verbes, dont, à titre d’exemple, nous pouvons citer endiguer et entamer :
(Ouest-France 2007)
4) Pourtant, les mauvais sondages n’ont pas semblé entamer l’enthousiasme de celui qui, jusqu’au dernier moment, a espéré « créer la surprise ».
(Le Figaro 2008)
La 3ème classe est la classe des « Vcaus phasiques inchoatifs » (18 verbes comme déclencher, exciter) :
6) C’est Zira, qui se moque sans méchanceté de mes efforts et sa présence excite toujours la colère de la fille. (Pierre Boulle 1963)
La suivante est la classe des « Vcaus phasiques terminatifs » qui ne compte que neuf verbes tels que chasser, étouffer, etc. :
(Maurice Druon 1955)
8) Pas sûr que la riposte de Royal suffise à étouffer la colère des autres ténors socialistes.
(Libération 2007)
Les deux dernières classes sont : la classe des « Vcaus phasiques d’intensité forte » (croissance graduelle) et la classe des « Vcaus phasiques d’intensité faible » (décroissance graduelle). La première comprend des verbes comme attiser, nourrir (au total 22 verbes) :
(Le Monde 2008)
10) Des cités-dortoirs succédaient à des bâtiments colossaux, arborant des tons mornes qui paraissaient absorber le soleil pour nourrir leur seule amertume.
(Jean-Christophe Grange 2000)
La seconde (la classe des « Vcaus phasiques d’intensité faible » (décroissance graduelle)) comprend des verbes comme atténuer et canaliser (au total 14 verbes) :
(Le Figaro 2008)
12) Les actions en nom collectif sont la meilleure façon de canaliser la colère qui provoque chaque année quelque 40 000 disputes autour des questions environnementales.
(Le Monde 2008)
Notons encore que, faute de résultat, la classe de « causation durative » correspondant aux verbes tels qu’entretenir et maintenir a été retirée de notre classement.
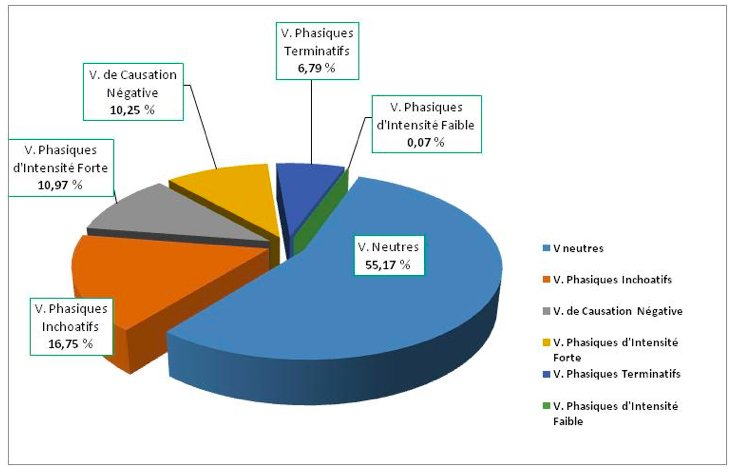
Le corpus Emolex nous a fourni 3456 cooccurrences que nous avons réparties dans les six classes verbales :
Figure 1 : Comparaison, en pourcentage, des classes de Vcaus dans notre corpus
Il en ressort que la classe des « Vcaus neutres » (28 V) est prédominante : elle comporte, au total, 2340 occ. correspondant à 55,17 % de l’ensemble. La classe des « Vcaus phasiques inchoatifs » (18 V correspondant aux 441 occ.) vient en deuxième position avec 16,75 %. La classe des « Vcaus phasiques d’intensité forte » (21 V) et la classe des « V de causation négative » (18 V) apparaissent à parts presque égales, mais, par rapport aux classes précédentes, elles sont nettement moins volumineuses (respectivement 315 occ. correspondant à 10,97 % et 273 occ. correspondant à 10,25 %). La classe des « Vcaus phasiques terminatifs » (9 V) et la classe des « Vcaus phasiques d’intensité faible » (11 V) sont statistiquement les moins significatives : elles comportent, respectivement, 6,79 % et 0,07 % de l’ensemble.
Sur l’ensemble des 338 combinaisons différentes répertoriées dans le corpus Emolex, nous avons sélectionné 11 combinaisons ayant une fréquence supérieure à 100 occurrences. Le Tableau 3 répertorie l’ensemble des informations concernant ces combinaisons : la première colonne du lexicogramme intitulée « Type de combinaison » indique la combinaison, la deuxième (f) désigne sa fréquence, la troisième (f1) et la quatrième (f2) correspondent à la fréquence propre de ses composants : celle du mot-pivot (ici: N_émot) et celle de son « collocatif » (ici: Vcaus). Quant aux cinquième et sixième colonnes (« Score LL » et « champ »), elles correspondent, respectivement, au paramètre log-likelihood marquant la spécificité statistique de cette cooccurrence et au champ sémantique auquel appartient le N_émot. Les combinaisons sont classées par fréquence décroissante du test du log-likelihood :
|
Type de combinaison |
f |
f1 |
f2 |
C. verbale |
Score LL |
champ |
|
faire DET plaisir |
154 |
24946 |
1387387 |
Vcaus neutres |
4773,9189 |
JOIE |
|
créer DET surprise |
565 |
21558 |
117498 |
Vcaus neutres |
3665,1881 |
SURPRISE |
|
faire DET bonheur |
436 |
18048 |
1387387 |
Vcaus neutres |
2409,6210 |
JOIE |
|
provoquer DET colère |
283 |
17433 |
76433 |
Vcaus neutres |
2002,0050 |
COLERE |
|
réserver DET surprise |
244 |
21558 |
27223 |
Vcaus neutres |
1844,5689 |
SURPRISE |
|
susciter DET engouement |
122 |
4332 |
31354 |
Vcaus neutres |
1165,4956 |
ADMIRATION |
|
susciter DET convoitise |
130 |
1452 |
31354 |
Vcaus neutres |
1145,6113 |
JALOUSIE |
|
susciter DET enthousiasme |
126 |
7347 |
31354 |
Vcaus neutres |
1061,7810 |
JOIE |
|
susciter DET colère |
129 |
31354 |
76433 |
Vcaus neutres |
824,8042 |
COLÈRE |
|
susciter DET indignation |
118 |
2831 |
31354 |
Vcaus neutres |
744,7285 |
COLÈRE |
|
faire DET joie |
122 |
11624 |
1387387 |
Vcaus neutres |
259,8158 |
JOIE |
Tableau 3 : Lexicogramme des combinaisons les plus spécifiques sur le plan de la fréquence et selon le test du log-likelihood
L’intérêt de nous baser sur la valeur du log-likelihood et non uniquement sur la fréquence de la combinaison apparaît clairement dans le cas defaire DET plaisir: selon nos calculs cette combinaison a une fréquence moins forte que créer DET surprise ou faire DET bonheur (154 occ. contre 565 et 436, respectivement), mais comme la fréquence propre (f1) du nom plaisir est plus élevée (24946 vs 21558 respectivement 18048), la valeur du paramètre log-likelihood est plus forte (4773 vs 3665 respectivement 2409). Or, il faut d’autre part signaler aussi que les résultats de notre requête pour la collocationfaire DET plaisir comportaient des formes qui étaient syntaxiquement et sémantiquement peu intéressantes pour notre étude18, comme la forme figées faire (DET)0 plaisir :
(Ouest-France 2008)
Ainsi, nous avons testé notre hypothèse selon laquelle il existe, dans le langage « authentique », une attirance « naturelle » entre certaines lexies (la théorie des Halbfertigprodukte de la langue de Hausmann 1984). Les statistiques valident notre hypothèse : il existe, par exemple, une attirance particulière entre les N_émot et la classe des « Vcaus neutres », tandis qu’entre les N_émot et la classe des « Vcaus phasiques d’intensité faible » l’attirance est très limitée (cf. Figure 1).
Ainsi le Tableau 3 donne lieu à quelques observations essentielles, à savoir :
Deux verbes forment plus d’une association : susciter (cinq combinaisons) et faire (trois combinaisons). Les autres combinaisons sont uniques, à savoir créer DET surprise, réserver DET surprise et provoquer DET colère.
Nous avons identifié deux verbes transversaux: susciter (qui entre en combinaison avec 25 N_émot19provenant de huit champs différents) et provoquer (qui entre en combinaison avec 21 N_émot provenant de sept champs).
Comme on peut le voir dans le Tableau 3, certaines de ces combinaisons sont très spécifiques sur le plan de la fréquence, comme c’est le cas de provoquer DET colère (qui se place en 3ème position du classement de fréquence). Aucune association du verbe susciter n’atteint une fréquence aussi élevée que celle de provoquer qui a 283 occ. Or, sur notre liste des 11 combinaisons les plus spécifiques des champs, c’est le verbe susciter qui est le plus présent: il forme cinq combinaisons ayant une fréquence supérieure à 100 occ. : susciter DET engouement, susciter DET convoitise, susciter DET enthousiasme,susciter DET colère et susciter DET indignation.
La combinaison créer DET surprise réunit un verbe de la classe des « Vcaus neutres » et un nom d’émotion du champ SURPRISE. Selon nos calculs, le N_surprise est le plus spécifique auprès des verbes de cette classe puisque sur l’ensemble des 3950 occ. repérées, 889 occ. reviennent à ce nom.
Le Tableau 4 ci-dessous, constitué selon le même modèle que le Tableau 3 de la section 3.1., illustre l’ensemble des collocatifs verbaux du nomsurprise repérés dans le corpus. La fréquence (f1), celle du N_surprise, est commune. Les verbes sont classés par valeur du test du log-likelihood décroissante (« Score LL ») :
|
Mot-pivot |
Coll.verb. |
f |
f1 |
f2 |
Score LL |
C. verbale |
|
surprise |
créer |
565 |
21558 |
180292 |
6645,1076 |
Vcaus neutres |
|
réserver |
244 |
41989 |
3450,2399 |
Vcaus neutres |
||
|
ménager |
16 |
9621 |
187,1161 |
Vcaus phasiques d’intensité faible (décroissance graduelle) |
||
|
causer |
22 |
19974 |
149,4207 |
Vcaus neutres |
||
|
provoquer |
26 |
76433 |
72,2868 |
Vcaus neutres |
||
|
susciter |
17 |
53308 |
71,0915 |
Vcaus neutres |
||
|
apporter |
15 |
94694 |
12,8919 |
Vcaus neutres |
||
|
Total |
7 Vcaus |
905 occ. |
||||
Tableau 4 : Liste des huit collocatifs verbaux du N_surprise repérés dans le corpus Emolex
On constate ainsi que surprise présente un vaste éventail de combinaisons. Or, excepté le verbe ménager appartenant à la classe des « Vcaus phasiques d’intensité faible » (décroissance graduelle), les autres verbes proviennent de la classe des « Vcaus neutres ». En tête de classement, nous retrouvons les deux verbes les plus saillants de cette classe : créer et réserver, avec les log-likelihood les plus élevés de toutes les associations: 6645 et 3450, respectivement. En troisième position se place la combinaison ménager DET surprise, mais, en fait, la fréquence de cette combinaison est moins élevée que celle du verbe provoquer : 16 occ. vs 26. Si le log-likelihood de la combinaison ménager DET surprise est supérieur à celui de provoquer DET surprise (187 vs 72), c’est dû à la fréquence du verbe provoquer, très élevée par rapport à celle de ménager : 76433 vs 9621.
Le nom surprise comprend au total 905 occ., ce qui le place en première position dans le classement général de fréquences. Ceci s’explique principalement par les fréquences très élevées de ces deux combinaisons les plus spécifiques : créer DET surprise (qui domine les statistiques en termes de fréquence et de spécificité) et réserver DET surprise (244 occ. et LL 3450). Cela signifie que ces associations ne sont pas fortuites : il existe une véritable attirance entre ces lexies. Illustrons ce constat avec deux exemples issus de notre corpus :
15) Les résultats des équipes de tête du groupe D réservent bien des surprises. (Ouest-France 2008).
Ainsi, nous pouvons constater qu’il existe des attirances privilégiées entre surprise et ses deux collocatifs verbaux : créer et réserver. Il serait intéressant, à notre avis, de procéder dans la suite de notre travail à une analyse plus fine de tous les N_émot qui s’associent à ces deux verbes.
Le Tableau 5 présente les associations du verbe créer ayant un taux d’occurrences supérieur/égal à un. Ce tableau est construit d’après les mêmes principes que le tableau précédent (Tableau 4), mais cette fois c’est la fréquence (f2) du verbe créer qui est commune :
|
Vcaus |
arguments (N_émot) |
f |
f1 |
f2 |
Score LL |
champ |
|
créer |
surprise |
565 |
21558 |
117498 |
6645,1076 |
SURPRISE |
|
irritation |
1 |
1029 |
116,9562 |
COLERE |
||
|
envie |
5 |
25163 |
51,9355 |
JALOUSIE |
||
|
engouement |
15 |
4332 |
29,3864 |
ADMIRATION |
||
|
indignation |
1 |
2831 |
27,5877 |
COLERE |
||
|
agacement |
1 |
1522 |
17,0010 |
COLERE |
||
|
exaspération |
1 |
1155 |
15,6505 |
COLERE |
||
|
stupeur |
5 |
1735 |
11,7415 |
SURPRISE |
||
|
Total |
8 |
594 occ. |
|
3 champs |
||
Tableau 5 : La liste des N_émot qui entrent en combinaison avec le Vcaus créer (corpus Emolex)
A première vue, le verbe créer semble avoir un emploi riche et varié : il entre en combinaison avec huit N_émot de quatre champs différents, à savoir le champ SURPRISE, COLERE, JALOUSIE et ADMIRATION et sa combinaison dominante créer DET surprise se place en première position du classement général des fréquences (cf. Tableau 3). Or, si ce verbe peut être considéré comme « fréquent », c’est quasi uniquement grâce à la fréquence élevée de sa combinaison avec surprise : 563 occ. Par rapport à cette dernière, les autres associations de ce verbe semblent beaucoup moins significatives: sur les huit N_émot entrant en association avec ce verbe dans notre corpus il y en a quatre, à savoirindignation, irritation, agacement et exaspération, qui sont des hapax21.
Se plaçant en seconde position sur la liste des collocatifs verbaux de surprise, le verbe réserver correspond également à un résultat intéressant méritant une étude spécifique : 244 occ. et une valeur de LL égal à 1844 (cf. Tableau 4). Or, dans notre corpus, l’association avec surprise est unique pour ce verbe. Ainsi, nous considérons qu’il existe, peut-être, des contraintes sémantiques propres à ce verbe qui limitent sa capacité de se combiner avec d’autres N_émot. Ce constat mérite une étude supplémentaire qui n’entre pas dans le cadre de la présente étude.
Finalement, sur l’ensemble des 3456 occurrences repérées dans les neuf champs d’émotions, nous avons identifié 338 combinaisons ayant une fréquence entre une et 565 occurrences. La Figure 2 ci-dessous illustre leur répartition :
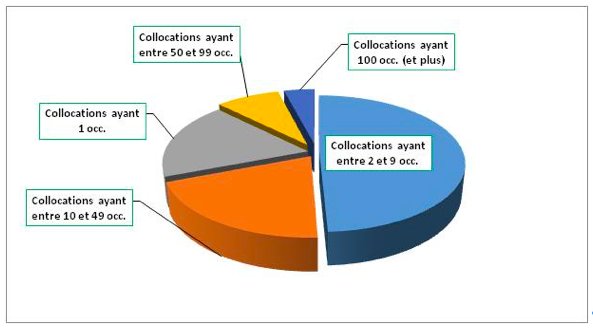
Figure 2 : Répartition, par rapport à la fréquence, des différents types de collocations
Il en ressort que les combinaisons ayant entre 2 et 9 occ. sont les plus fréquentes: 49,26 % de l’ensemble. Dans une grande partie il s’agit des associations des verbes de « causation négative » avec les noms du champ JOIE22 (désormais N_JOIE): entamer DET enthousiasme8, refreiner DET enthousiasme5, etc. Il y a également trois classes des verbes phasiques: la classe des verbes d’« intensité forte » (croissance graduelle) qui entre en association avec les champs COLERE, TRISTESSE et ADMIRATION ( alimenter DET colère8, aviver DET regret6, nourrir DET fascination5), la classe des verbes d’« intensité faible » (décroissance graduelle) qui s’associe avec les noms du champ COLERE (calmer DET courroux8, tempérer DET fureur4) et la classe des verbes « terminatifs » qui forme des associations avec quasiment l’ensemble des neufs champs d’Emolex: étouffer DET colère8 (champ COLERE), gâcher DET bonheur7 (champ JOIE), chasser DET tristesse4 (champ TRISTESSE), dissiper DET amertume3 (champ DECEPTION) , éteindre DET émerveillement3 (champ ADMIRATION), etc.
Moins fréquentes que les précédentes, les combinaisons ayant entre 10 et 49 occ. présentent encore un poids statistiquement important de 19,85 %. Les plus représentatives sont ici : la classe des « Vcaus neutres » et la classe des « Vcaus phasiques inchoatifs ». Pour les deux, les associations avec les N_COLERE sont les plus spécifiques : susciter DET irritation21, provoquer DET engouement18 (« Vcaus neutres ») et soulever DET indignation36, déclencher DET ire35, etc. (« Vcaus phasiques inchoatifs »).
Les collocations ayant une seule occurrence (des hapax) sont également fréquentes dans notre corpus (18,38 %). Elles impliquent quasiment l’ensemble des lexies provenant de nos deux classes grammaticales : attiser DET jalousie (verbe d’« intensité forte »+ N_JALOUSIE),empêcher DET fascination (verbe de « causation négative » + N_ADMIRATION), susciter DET liesse (« Vcaus neutres » + N_JOIE), etc.
Les plus rares sont les combinaisons ayant entre 50 et 99 occ. et celles ayant plus de 100 occurrences (les plus spécifiques donc): elles constituent à peine 8 % et 4 % de l’ensemble. A quelques exceptions, comme inspirer DET respect66, déclencher DET colère66 (verbes « inchoatifs ») et attiser DET convoitise65 (verbe d’« intensité forte »), elles ne sont formées que par les « Vcaus neutres » associés aux N_émot provenant des champs comme ADMIRATION, COLERE, JALOUSIE, JOIE et SURPRISE (cf. Tableau 3 de la section 3.1.).
Notons encore que parmi les combinaisons ayant une seule occurrence, on trouve la construction être cause de qui, selon Nazarenko (2000), représente le prototype des causatifs opérant sur une action humaine :
En fait, d’une manière générale, la fréquence des causatifs prototypiques tels que causer ou faire/laisser + Vinf n’est pas très élevée dans notre corpus. Ceci va dans le sens de l’observation de Gross et al. (2009) dont l’analyse des associations verbo-nominales de causation dans un grand corpus journalistique constitué de dix années d’éditions du journal Le Monde23 a fait ressortir que les verbes prototypiques comme provoquer ou causer24 se combinent pratiquement exclusivement avec les noms de polarité négative : dégâts, catastrophes, maladies, etc. Effectivement, dans notre corpus, le verbe provoquer apparait le plus souvent dans des combinaisons avec des N_émot de polarité négative et, plus spécifiquement, ceux provenant du champ COLERE : provoquer DET colère (283 occ.), provoquer DET indignation (61 occ.), provoquer DET ire (53 occ.), etc. Ceci est également le cas du prototypique causer ; excepté le nom surprise (22 occ.) qui est de polarité neutre, ce verbe entre en association uniquement avec des noms ayant une polarité négative : chagrin (huit occ.), malheur (sept occ.), déception (sept occ.), irritation (cinq occ.), etc. Or, il nous semble que les faibles résultats statistiques de certaines combinaisons sont liés au type de corpus choisi (des corpus journalistiques dans nos deux cas). Nous avons vérifié, d’ailleurs, dans le Web francophone25, l’usualité des deux combinaisons du verbe provoquer qui ont une polarité positive: provoquer DET fascination et provoquer DET émerveillement. Ces deux collocations sont peu usuelles dans notre corpus (respectivement deux occ. et trois occ.), mais nous les considérons intuitivement comme courantes. Notre petite requête a fait ressortir l’usage fréquent de ces collocations dans la langue courante : provoquer DET émerveillement (www.google.fr/#q=provoquer+%2B+%C3%A9merveillement, [04.09.2015]) est apparu dans sept énoncés (sur dix) du contenu de la première page de google.fr, tandis que provoquer DET fascination (www.google.fr/#q=provoquer+%2B+fascination+, [04.09.2015]) était présent dans tous les énoncés de la première page Web français.
Les résultats empiriques de notre étude prenant appui sur le corpus Emolex, nous ont permis non seulement de confirmer notre hypothèse concernant l’existence des liens privilégiés entre les N_émot et certains Vcaus (la théorie des Halbfertigprodukte de la langue de Hausmann 1984), mais ont fourni également des arguments convaincants en faveur de la théorie du Lexical priming de Hoey (2005) ; il existe de véritables « attirances » entre certaines lexies (créer + surprise, faire + bonheur, réserver + surprise, etc.).
Or, malgré ces résultats très encourageants, notre étude ne nous a pas apporté de réponse définitive sur le choix des collocations à enseigner étant donné que quatre champs sur neuf ont des fréquences très faibles, à savoir MEPRIS, TRISTESSE, RESPECT et DECEPTION. Si, pour dresser des listes de collocations à enseigner, nous nous basons uniquement sur les critères de fréquence et de valeur de log-likelihood élevées (en prenant en compte, par exemple, les collocations les plus spécifiques, indiquées dans le Tableau 3), sur l’ensemble des 338 combinaisons recensées pour le patron Vcaus + N_émot, 11 combinaisons provenant des cinq champs seulement correspondront à ce critère. Le problème persiste même si nous élargissons nos critères.
Ceci nous a fait réfléchir à notre deuxième hypothèse selon laquelle la fréquence peu élevée de la collocation dans un corpus donné ne signifie pas toujours que cette dernière n’est pas usuelle (Hausmann 1984 ; Tutin 2009). C’est le cas, par exemple, des collocations provoquer DET émerveillement et provoquer DET fascination qui, comme nous l’avons signalé supra, sont peu fréquentes dans notre corpus, mais d’un usage fréquent selon les résultats de notre « requête » effectuée sur le Web francophone. Ainsi ce constat fournit des arguments en faveur de notre troisième hypothèse selon laquelle les faibles résultats statistiques de certaines combinaisons peuvent être liés au type de corpus choisi, aux préférences linguistiques de tel ou tel journaliste ou même de tel ou tel support.
En prenant en compte ce facteur, dans le cas des champs les plus faibles statistiquement (comme les quatre champs cités ci-dessous), nous jugeons pertinent de prendre en considération la théorie de la disponibilité lexicale des collocations de Hausmann (1985), repris par Tutin (2005a) et de retenir, par exemple, dans le champ MEPRIS, les combinaisons comme inspirer DET mépris (huit occ.), nourrir DET mépris (cinq occ.) ou flatter DET mépris26 (deux occ.), car ces collocations sont les seules dans ce champ. Ce qui est évident aussi, c’est qu’au moment d’avoir un choix de combinaisons, nous allons recourir au concept des collocations statistiquement significatives de Williams 2003). Dans le champ JOIE, par exemple, pour introduire l’aspect terminatif de la collocation Vcaus + N_émot, nous allons retenir la collocation gâcher DET plaisir qui a 40 occ. et un LL de 290 et non gâter DET plaisir qui n’a que trois occ. et un LL de 20 (laquelle nous considérons intuitivement comme moins courante). Nous avons vérifié, d’ailleurs, dans le Web francophone, l’usualité de ces deux associations et notre requête a fait ressortir qu’effectivement gâcher DET plaisir (www.google.fr/#q=g%C3%A2cher+plaisir, [14.02.2016]) a un usage beaucoup plus fréquent dans la langue courante que gâter DET plaisir (www.google.fr/#q=g%C3%A2ter+plaisir, [14.02.2016]).
Ainsi, dans le choix des collocations à enseigner, nous allons prendre en compte aussi bien le critère de fréquence que les facteurs dits « subjectifs » (tels que, par exemple, notre propre intuition concernant l’usage, la typicité ou des critères didactiques comme les objectifs spécifiques, le niveau du public-cible, etc.). La consultation de plusieurs sources à la fois dans le cas de certaines collocations nous semblerait aussi bénéfique, même si, d’après Williams (2003), les données d’un corpus informatisé sont suffisantes pour évaluer l’usage des expressions.
Bak Sienkiewicz, Monika (2010): Le lexique verbal causatif et le raisonnement causal dans les textes scientifiques issus de Scientext, Mémoire de Master 2. Grenoble, Université Stendhal Grenoble 3.
Blumenthal, Peter (2002): « Profil combinatoire des noms. Synonymie distinctive et analyse contrastive ». Zeitschrift für Französische Sprache und Literatur 112: 115–138.
Cavalla, Cristelle/Loiseau, Mathieu/Lascombe, Valérie/Socha, Joanna (2015): « Corpus, base de données, cartes mentales pour l’enseignement ». In: Blumenthal, Peter/Novakova, Iva/Siepmann, Dirk (eds.): Les émotions dans le discours. Berlin, Lang: 327–341. doi: 10.3726/978-3-653-03879-8.
Cavalla, Cristelle/Labre, Virginie (2009): « L’enseignement en FLE de la phraséologie du lexique des affects ». In: Novakova, Iva/Tutin, Agnès (eds.): Le Lexique des émotions et sa combinatoire lexicale et syntaxique. Grenoble, Éditions littéraires et linguistiques de l’université de Grenoble: 297–316.
De Mulder, Walter (2008): “Force dynamics”. In: Geeraerts, Dirk/Cuyckens, Hubert (eds.): The Oxford Handbook of Cognitive Linguistics. Oxford, Oxford University Press: 294–317.
Diwersy, Sascha et al. (2014): « Traitement des lexies d’émotion dans les corpus et les applications d’EmoBase ». Corpus 13. http://corpus.revues.org/2537 [04.09.2015].
Diwersy, Sascha/François, Jacques (2011): « La combinatoire des noms d’affect et des verbes supports de causation en français ». Travaux Neuchâtelois de Linguistique. Travaux Neuchâtelois de Linguistique 55: 139–161.
Dixon, Robert Malcolm Ward (2000): “A Typology of Causatives: Form, Syntax, and Meaning”. In: Dixon, Robert Malcolm Ward/Aikhenvald, Alexandra (eds.): Changing Valency: Case Studies in Transitivity. Cambridge, Cambridge University Press: 30–83.
Gross, Gaston/Pauna, Ramona/ Valetopoulos, Freiderikos (2009): Sémantique de la cause. Leuven/Paris: Peeters.
Grutschus, Anke/Kern, Beate/Tutin, Agnès (2013): « La polarité du lexique de l’affect : perspective combinatoire et contrastive ». In: Cislaru, Georgeta/Baider, Fabienne (eds.): Cartographie des émotions. Propositions linguistiques et sociolinguistiques. Paris, Presses Sorbonne Nouvelle: 85–98.
Hausmann, Franz Josef (1989): « Le dictionnaire de collocations ». In: Hausmann, Franz Josef/Reichmann, Oskar/Wiegand, Herbert/Zgusta, Ladislav (eds.): Dictionaries. International Encyclopedia of Lexicography. 1st vol.. Berlin/New York, de Gruyter: 1010–1019.
Hausmann, Franz Josef (1984): „Wortschatzlernen ist Kollokationslernen. Zum Lehren und Lernen französischer Wortverbindungen“. Praxis des neusprachlichen Unterrichts 31: 395–406.
Hausmann, Franz Josef (1985): „Lexikographie“." In: Schwarze, Christoph/Wunderlich, Dieter (eds.): Handbuch der Lexikologie. Königstein, Athenäum: 367–411.
Hoey, Michael (2005): Lexical Priming: A New Theory of Words and Language. London, Routledge.
Legallois, Dominique/François, Jacques (2011): « La Linguistique fondée sur L’usage: parcours critique ». Travaux de linguistique 62: 7–33. doi: 10.3917/tl.062.0007.
Manning, Chris/Schütze, Hinrich (1999): “Collocations”. DRAFT! http://nlp.stanford.edu/fsnlp/promo/colloc.pdf [05.05.2015].
Nazarenko, Adèle (2000): La cause et son expression en français. Gap/Paris: Ophrys.
Novakova, Iva/Goossens, Vannina/Melnikova, Elena (2012): « Associations sémantiques et syntaxiques spécifiques. Sur l’exemple du lexique émotionnel des champs de surprise et de déception ». SHS Web of Conferences 1. 1017–1029. doi: 10.1051/shsconf/20120100181.
Novakova, Iva/Tutin, Agnès (eds.) (2009): Le lexique des émotions. Grenoble, Éditions littéraires et linguistiques de l’université de Grenoble.
Talmy, Leonard (2000): Toward a Cognitive Semantics. Vol. 1. Cambridge: MIT Press.
Tutin, Agnès/Grossmann Francis (eds.) (2014): L’écrit scientifique: du lexique au discours. Autour de Scientext. Rennes, Presses universitaires de Rennes.
Tutin, Agnès (2010): “Showing phraseology in context: an onomasiological access to lexico-grammatical patterns in corpora of French scientific writings”. In: Granger, Sylviane/Paquot, Magali (eds.): Lexicography in the 21st Century: New Applications, New Challenges. Louvain, Presses universitaires de Louvain: 313–324.
Tutin, Agnès/Novakova, Iva/Grossmann, Francis/Cavalla, Cristelle (2006): « Esquisse de typologie des noms d’affect à partir de leurs propriétés combinatoires ». Langue française 150. Paris, Armand-Colin: 32–49.
Tutin, Agnès (2005a). « Les dictionnaires de collocations sont-ils nécessaires ? ». In: Revue Française de Linguistique Appliquée 2: 31–48. www.cairn.info/revue-francaise-de-linguistique-appliquee-2005-2-page-31.htm [05.05.2015].
Williams, Geoffrey (2003): « Les collocations et l’école contextualiste britannique ». In: Tutin, Agnès/Grossmann, Francis (eds.): Les collocations: analyse et traitement, Travaux de recherches en linguistique appliquée. Amsterdam, de Werelt: 33–44.
1 Les apprenants non natifs. retour
2 Comme les collocations. retour
3 L’association Vcaus + N_émot est conçue dans notre travail comme une collocation au sens large de Hausmann (1989) et de la méthodologie élaborée dans le cadre du projet Emolex (Diwersy et al. 2014), c’est-à-dire comme une association d’un nom et d’un verbe entretenant une relation sémantique et syntaxique spécifique : susciter DET colère, déclencher DET colère, calmer DET colère, etc. retour
4 La fréquence (ou « répétition dans l’usage ») est considérée ici comme la « source » de systématisation à travers l’effet de la répétition sur le stockage et le traitement cognitif des unités. Pour plus de détails, cf. Legallois et François (2011). retour
5 Ce terme est utilisé ici au sens de Novakova et al. (2012). retour
6 Dans le sens où les relations entre les différents éléments linguistiques sont gérées par la langue elle-même (Hausmann 1984). retour
7 Un « produit préfabriqué » de la langue. retour
8 Cette classe comprend les verbes qui, hors contexte, ne présentent pas de dimensions clairement marquées (comme provoquer, susciter, créer, etc.) (Diwersy et al. 2014). retour
9 Les bases des données, équilibrées et représentatives, fournissent des indications importantes sur les plans quantitatif et qualitatif de l’usage des lexies (Williams 2003). retour
10 Sous le terme de la disponibilité lexicale nous comprenons ici les lexies repérées dans le corpus Emolex selon le paramètre log-likelihood dont le seuil est d’au moins 10,83. retour
11 Traduction personnelle. retour
12 Tutin a effectué une étude à partir de la base catégorisée de Frantext sur un siècle, de 1900 à 2005. retour
13 Le projet franco-allemand sous la responsabilité d’I. Novakova (Université Grenoble-Alpes) et de P. Blumenthal (Université de Cologne) étudie le lexique des émotions dans cinq langues européennes. retour
14 Pour plus de détails cf. Diwersy et al. (2014). retour
15 Bak Sienkiewicz (2010). retour
16 La classification des verbes supports de causation proposée par Diwersy et François (2011) repose sur le principe de la « force dynamics » de Talmy (2000) discutée par De Mulder (2008). retour
17 Ce classement est inspiré des travaux de Dixon (2000), Nazarenko (2000), Diwersy / François (2011) et Diwersy et al. (2014). retour
18 Sur l’ensemble des 1506 occ. repérées pour cette collocation, 154 occ. seulement correspondaient à notre patron syntaxique Vcaus DET N_émot. Ceci peut expliquer la fréquence moins élevée de cette combinaison. retour
19 Sur l’ensemble des 46 N_émot sélectionnés dans le cadre du projet Emolex. retour
20 Selon nos calculs et le test du log-likelihood, l’attirance entre les 106 Vcaus de notre liste et les neuf champs d’émotions est la plus forte pour ces deux verbes : provoquer DET colère a le LL de 2002, tandis que les LL des cinq associations les plus spécifiques de susciter sont supérieurs à 700. retour
21 Une seule occurrence. retour
22 A une seule exception : gâcher DET plaisir40. retour
23 A partir de ce corpus, Gross a extrait environ 6000 substantifs différents sur lesquels opèrent les prédicats de cause. retour
24 On trouve le même constat chez Hoey (2005: 22–23) pour le verbe to cause dont les arguments sont, dans la majorité des cas, négatifs: accident, death, disease, trouble, problems, etc. retour
25 Notre objectif n’étant pas de prouver la prédominance des combinaisons véhiculant la polarité positive de ces deux verbes, mais uniquement de souligner des risques liés à l’homogénéité du corpus d’étude. Notre requête ne s’est basée alors sur aucun corpus précis sur le Web ; nous avons fait appel à un navigateur internet « services Web libres » permettant l’accès à l’ensemble des énoncées sans aucune contrainte (sauf les nôtres). retour
26 Cette association est pour le moins inattendue et on peut l’attribuer à un discours journalistique, à une figura qui renforcent l’« accroche » du lecteur. Elle apparaît dans le contexte « renoncer aux expressions qui abaissent la culture et flattent le mépris des intellectuels... » (Libération 2007). retour