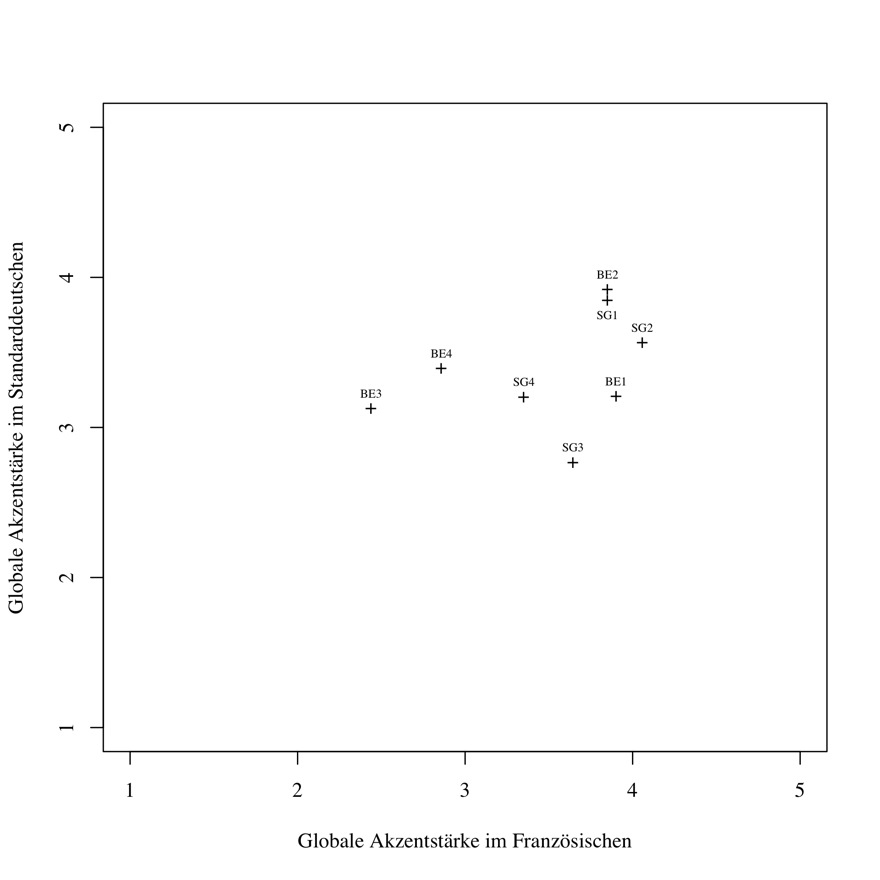
 Abbildung 4: Akzent im Standarddeutschen und im Französischen: Streudiagramm
Abbildung 4: Akzent im Standarddeutschen und im Französischen: StreudiagrammWie kommt es, dass wir eine Zweit- oder Fremdsprache (L2) gut beherrschen können, in unserer Aussprache aber trotzdem immer der Akzent1 unserer Muttersprache (L1) durchscheint? Wenn eine Schweizer Dialektsprecherin2 Französisch oder Standarddeutsch spricht, ist dabei meist ein dialektaler Akzent erkennbar – für die meisten Dialektsprecher ist ja das Französische die erste Fremdsprache, die sie lernen und die deutsche Standardsprache nicht gerade eine Fremdsprache, aber doch eine Art Zweitsprache, eine "erweiterte"3 Form ihrer L1. Wenn nun besagte Sprecherin in einer dieser Sprachen einen ausgeprägteren Akzent hat als ihr Nachbar: Woran könnte das liegen? Hat sie einfach weniger Sprachtalent, oder sind vielleicht andere Faktoren im Spiel?
Sprachen, Sprachlernen, Spracheinstellungen, Kommunikation zwischen den verschiedensprachigen Landesteilen der Schweiz und deren Bewohner – all dies ist Teil unserer Diskussion sowohl auf politischer und wirtschaftlicher Ebene, als auch Thema am Kaffee-, Familien- oder Stammtisch. Zum Zweit- oder Fremdspracherwerb4 an der Schule und seinen Ergebnissen entstehen auch durch die Medien immer wieder angeregte Debatten. Das oben abgedruckte, für Spracheinstellungen in der Schweiz geradezu symptomatische Zitat wirft die Frage auf, wie solche Einstellungen im Einzelfall aussehen und woher sie kommen. Weiter stellt sich aber auch die Frage, wie sie auf den Lernprozess eines Individuums einwirken.
Ausgehend von solchen Überlegungen soll im Rahmen der vorliegenden Arbeit folgende Hypothese empirisch überprüft werden:
Zum Testen dieser Hypothese wurden von Sprechern aus zwei Schweizer Dialektgebieten, Stadtbernern und Stadt-St.-Gallern, Aufnahmen angefertigt, auf welchen sie Standarddeutsch und Französisch frei sprechen und vorlesen. Beide Sprachen wurden von allen Sprechern in der Schule gelernt und regelmässig gesprochen. Diese Aufnahmen wurden in einem Perzeptionsxperiment deutschsprachigen und frankophonen Probanden vorgespielt, welche die jeweiligen Sprachproben nach Akzentstärke und dialektaler Herkunft der Sprecherin zu beurteilen hatten (vgl. Kolly (im Druck) für die Resultate zur regionalen Identifizierbarkeit dialektaler Akzente in den standarddeutschen und französischen Sprachproben). Mit einem semantischen Differential wurde zusätzlich die Einstellung der Sprecher zu den jeweiligen Sprachen erhoben.
Die theoretische Grundlage, welche für die empirische Studie einen Rahmen bildet, hebt einerseits die relevanten Aspekte der Akzentforschung, aufgeteilt in Sprachproduktion und Sprachrezeption, hervor. Insbesondere wird dabei Lauterwerb im Erst- und im Zweitsprachenkontext eine Rolle spielen, sowie die Fragen der konstitutiven und kausalen Aspekte des fremdsprachlichen Akzents. Andererseits werden Spracheinstellungen und deren Messbarkeit mit Blick auf die Sprachen, die für die vorliegende Untersuchung eine Rolle spielen, in ihrem schweizweiten Kontext diskutiert.
Die Beschränkung auf die beiden Dialekte aus dem Schweizer Mittelland resultierte einerseits aus dem Versuch, für die oben erwähnte Studie zur regionalen Identifizierbarkeit von Akzenten einen West/Ost-Kontrast zu erfassen (vgl. Kolly im Druck); andererseits wird die Aufmerksamkeit der Teilnehmer beim Perzeptionsexperiment durch die Sprachproben jedes Sprechers in zwei Sprachen und zwei Konditionen schon stark strapaziert. Der Einbezug einer gewissen Sprechervariation und männlicher sowie weiblicher Gewährspersonen in die Studie für eine Untermauerung der Resultate wurde hier einer grösseren Variation der Herkunftsdialekte vorgezogen. Der abstrakte Referenzbegriff einer uniformen und homogenen Standardsprache, wie er hier und anderswo verwendet wird, bleibt ein Konstrukt, welches der jeder Sprache "inhärente[n] Variabilität von Varietäten" (Lameli 2004 : 24) sowie deren Ansiedlung auf einem Kontinuum nicht gerecht wird. Um die Variabilität insbesondere des Schweizerhochdeutschen als nationaler Standardsprache im Folgenden adäquat beschreiben zu können, braucht es aber die abstrakte Referenzgrösse eines überregionalen Standards (für eine ausführlichere Diskussion vgl. z. B. Hove 2002, Lameli 2004: 34–38 sowie Kapitel 4.1 und 5.4 des vorliegenden Artikels).
Umfassende Monographien zum Thema sind zwar spärlich gesät, aber die Forschungsartikel, die sich im weiteren Sinne mit Akzent beschäftigen, behandeln das Thema aus vielen unterschiedlichen Blickwinkeln. Es gilt einschränkend, dass die meisten Fragestellungen sehr spezifisch und eng gehalten werden und dass der Grossteil der Sprachkonstellationen Englisch als Hauptkomponente und -untersuchungsobjekt enthalten.
Im Folgenden wird ein theoretischer Rahmen zum fremdsprachlichen Akzent präsentiert: Verschiedene Studien sowohl zu perzeptiven als auch zu produktiven Aspekten von Akzent sollen kurz zusammengefasst und in ihrer Bedeutsamkeit für die vorliegende Untersuchung dargestellt werden. Das erste Unterkapitel betrachtet zwei Aspekte der Perzeption "fremd" klingender Sprache: Einerseits wird die Wahrnehmung von Akzent je nach Textsorte und in dessen Bedeutung für die Kommunikationssituation diskutiert, andererseits die Perzeption von unvertrauten Lauten einer L2. Der Teil zum Akzent in der Sprachproduktion ist dreigegliedert: Einerseits soll er als Einführung und Grundlage einen kurzen Überblick über den unterschiedlichen Lauterwerb in Erst- und Zweitsprache geben, andererseits soll er erklären, woraus Akzent besteht und was dessen Stärke verrät, bzw. weshalb man (noch) einen Akzent hat.
Wie der Akzent einer Person im Bezug auf seine Intensität und Qualität wahrgenommen wird, hängt nicht zuletzt von der Textsorte, welcher die Hörerin ausgesetzt ist, ab. Insbesondere stellt sich hier die Frage, ob hinsichtlich der Akzentstärke ein Unterschied zwischen vorgelesenen Texten und freier Rede besteht. Grundsätzlich wird davon ausgegangen, dass in formelleren Situationen standardnähere Sprach- und Lautformen verwendet werden, da eine Sprecherin in solchen Kontexten ihre (Aus-)Sprache stärker kontrolliert und stigmatisierte Formen bzw. L1-Transfer zu vermeiden sucht (vgl. Major 2001: 71f.). Hove (2002: 139) bestätigt das in ihrer Studie zur Aussprache des Standarddeutschen durch Deutschschweizer. Dies führt zur Annahme eines schwächeren Akzents in vorgelesener Sprache, was aber nicht immer in Einklang mit den im Folgenden besprochenen empirischen Studien steht. So weisen Thompsons (1991: 193–195) Resultate auf einen tendenziell stärkeren Akzent in vorgelesener Sprache hin, der Unterschied zur freien Rede ist jedoch nicht signifikant. Bei Molnár (2010: 4–7) sind die beiden vorzulesenden Texte so konzipiert, dass sie viele Ausspracheschwierigkeiten des Deutschen abdecken und folglich den Eindruck eines stärkeren Akzents hervorrufen könnten als freie Rede. Dennoch lassen sich hinsichtlich der Akzentunterschiede zwischen vorgelesener und freier Rede keine generalisierenden Aussagen machen, was den bei Major (2001: 71f.) genannten Umständen zumindest nicht widerspricht. Auch eine Studie von Strik/Cucchiarini/Binnenpoorte (2000) untersucht die Beziehungen zwischen der Aussprachequalität vorgelesener und freier Rede und berücksichtigt dabei sowohl objektiv messbare Merkmale als auch die Urteile von Sprachexperten. Die automatische Beurteilung der (nur temporalen)5 Merkmale liefert eindeutige und gemäss Major (2010: 71f.) erwartbare Unterschiede: Die freie Rede schneidet, insbesondere da es nur um temporale Aspekte geht, schlechter ab als die vorgelesene. Das globale Sprechtempo und die mittlere Länge der Äusserungseinheiten zwischen zwei Pausen sind bei der freien Rede nur halb so hoch, die Pausenlängen doppelt bis dreimal so hoch wie beim Vorlesen. Die Artikulationsfrequenz jedoch scheint über beide Konditionen konstant zu bleiben (vgl. Strik/Cucchiarini/Binnenpoorte 2000: 584). Die Unterschiede zwischen freier und vorgelesener Rede in der Beurteilung durch menschliche Experten ist etwas komplizierter und wird in Strik/Cucchiarini/Binnenpoortes (ebd.: 585) Diskussionsteil vermieden. Grund dafür scheint die Aufteilung der Sprecher in zwei Niveaugruppen mit je verschiedenen Aufgaben zum Elizitieren freier Rede zu sein, was in einem inhomogenen Korpus resultiert. Einer Tabelle mit Durchschnittsbewertungen und Standardabweichungen kann jedoch entnommen werden, dass zumindest für die Gesamtaussprache die freie Rede, Majors Feststellung zum Trotz, besser abschneidet, und bezüglich der Segmentqualität weder die eine, noch die andere Kondition als die akzentbelastetere gelten kann.
Vergleicht man die automatischen Resultate mit den Beurteilungen durch Experten so folgt, dass quantitative, temporale Messungen erstaunlich gute Voraussagen über die allgemeine Aussprachequalität eines Sprechers erlauben (vgl. ebd.: 582). Ob phonetisch erfahrene Linguisten oder "Laien" die Intensität eines Akzents akkurater beurteilen, ist in der Forschung umstritten. Thompsons (1991: 183f.) Resultate suggerieren, dass Experten zwar zuverlässigere, konstantere Urteile abgeben, jedoch grundsätzlich mildere.
Das Sprechen mit einem Akzent bleibt für das sprachliche Handeln in Kommunikationssituationen nicht ohne Konsequenzen: Auf einer rein linguistischen Ebene erfordert der Akzent meist eine erhöhte Konzentration des Hörers, in manchen Fällen kann er die Verständlichkeit von Äusserungen stark beeinträchtigen (vgl. Ehlich 1986: 49–51; Flege 1995: 234).6 Suprasegmentale Abweichungen, kombiniert mit segmentalen Fehlern oder zu vielen Pausen innerhalb einer Äusserung, führen für viele Hörer zu totaler Unverständlichkeit des Gesagten (vgl. Hirschfeld/Trouvain 2007: 173). Aber auch paralinguistische Eigenschaften akzentbeladener Sprache können Verständnisprobleme hervorrufen – dies betrifft z. B. den Ausdruck des Satzmodus, aber auch den von Emotionen, Freundlichkeit, Müdigkeit usw., der in jeder Sprache durch Konventionen geregelt ist, welche den native speakers (NaS) dieser Sprache ganz selbstverständlich erscheinen. Des Weiteren schliesst ein NaS aufgrund eines fremden Akzents unbewusst auch auf Bildungsgrad, sozialen Status, Intelligenz und sogar Persönlichkeitszüge der Sprecherin (vgl. ebd.: 171). Dies und die Aktivierung von Gruppenstereotypen und persönlichen Einstellungen kann negative Beurteilungen zur Folge haben – je nach Akzenttyp werden beim Hörer aber auch positive Gefühle aktiviert, so dass manche Sprecherinnen ihren Akzent regelrecht pflegen (vgl. auch Ehlich 1986: 53). Hentschel (2000: 268) beschreibt dabei eine etwas paradoxe Tatsache: "The amount of miscommunication grows [...] with a greater command of the foreign language and cultural behaviour." Ein fremdsprachlicher Akzent kann einen Sprecher für "unangebrachtes" Verhalten in der Zielkultur gleichsam entschuldigen; je besser die Zielsprache beherrscht wird, desto weniger "entschuldigende" Sympathien bringen die NaS für den "Fremden" auf (vgl. auch Ehlich 1986: 48f.).
Auch nach langjähriger Erfahrung mit einer Sprache nehmen L2-Sprecherinnen Laute anders wahr als NaS derselben Sprache. Daraus folgt einerseits eine abweichende Produktion dieser Laute und damit der Effekt eines fremdsprachlichen Akzents, andererseits ein Lernerlexikon mit vielen Homophonen, die durch "mangelnde lautliche Differenzierung" (Bohn 1998: 1) entstehen. Die unterschiedliche Lautwahrnehmung durch L1- und L2-Sprecher hängt mit einer Vielzahl von Faktoren zusammen. Bohn (ebd.: 2, 16) nennt dafür sowohl Lerner- und L1-Variablen wie Interferenzen, Erfahrung mit der L2, Alter beim L2-Erwerb, als auch L2-Variablen wie akustische und visuelle Merkmale der Laute, insbesondere im Vergleich zu L1-Lauten. Ebenso wird ein L2-Laut je nach lautlicher Umgebung und Position im Wort verschieden wahrgenommen. Selbst wenn Lerner- und L1-Variablen wie Alter, L1, L2-Erfahrung und Alter zu Beginn des L2-Erwerbs konstant gehalten werden, stellt man individuelle Wahrnehmungsunterschiede zwischen Sprecherinnen fest (vgl. ebd.: 2). Bohn (ebd.: 9f.) lehnt eine mögliche Erklärung dessen durch den Einfluss von affektiven Variablen wie der Einstellung zur L2-Kultur und -Sprache sowie der Lernmotivation auf lautliche Aspekte der Sprache ab; ihm scheint die Variable "Sprachtalent" als Erklärung besser zuzusagen (vgl. dazu Kapitel 3.2 der vorliegenden Arbeit).
Die Wahrnehmung von Beziehungen zwischen L1- und L2-Lauten auf der konkreten phonetischen Ebene7 durch Lerner scheint die Hauptursache für Wahrnehmungsprobleme zu sein: Ab dem vollendeten ersten Lebensjahr gilt, dass jeder Lerner ein "L1-spezifischer Wahrnehmer" (Bohn 1998: 2) ist, wenigstens im Bereich der Konsonanten. Als Evidenz dafür gelten v. a. Untersuchungen zur L1-spezifischen Kategorisierung von Plosiven aufgrund der voice onset time (VOT)8. Solche Stimmhaftigkeitsoppositionen (besonders im Silbenanlaut) und Konsonantenkontraste mit aus der L1 nicht bekannten Artikulationsorten sind "am schwierigsten zu differenzieren und am erwerbsresistentesten" (ebd.: 11). Viele Wahrnehmungsprobleme, besonders bei Vokalkontrasten, können aber mit zunehmender Erfahrung gemindert und zum Teil überwunden werden, sodass Lerner, die eine hohe Erfahrung mit der gesprochenen L2 haben, deren Laute auf eine ähnliche Art diskriminieren wie NaS. Dies ergeben z. B. Untersuchungen mit L1-Japanern unterschiedlichen Sprachniveaus, die sich englische [r] vs. [l]-Kontraste mit der Zeit aneignen können, oder Experimente mit L1-Deutschen, die den englischen Kontrast [ɛ] vs. [æ], der im Standarddeutschen nicht distinktiv ist, nach und nach besser beherrschen (vgl. auch The International Phonetic Association 1999/2003: 87). Dabei werden die Laute anfangs nur aufgrund temporaler Unterschiede diskriminiert, mit steigendem Niveau werden, wie bei muttersprachlichen Hörern, auch spektrale Unterschiede berücksichtigt (vgl. Flege 1992: 565). Dieser Effekt gilt aber nicht für alle Kontraste: Englisches [ɪ] vs. [i], das auch im Deutschen distinktiv ist, wird von L1-Deutschen mit viel L2-Erfahrung gleich schlecht perzipiert wie von Lernern mit wenig Erfahrung (vgl. Bohn 1998: 3f.). Solche Unterschiede im Bezug auf spezifische Kontraste erklärt Fleges (1995: 237–243) Speech Learning Model, das L2-Laute auf einem Kontinuum von "identisch zum Laut der L1" über "ähnlich zum Laut der L1" zu "neuer Laut" ansiedelt. Dabei beeinträchtigen die ähnlichen Laute eine Unterscheidung des L1-Lauts vom L2-Laut am stärksten und werden oft als äquivalent in derselben Lautkategorie zusammengefasst (vgl. [ɪ] vs. [i] oben); "neue Laute" sind von den L1-Lauten so verschieden dass für sie eine neue Kategorie etabliert werden kann (vgl. [ɛ] vs. [æ] oben). Dieses Modell erklärt auch, weshalb L2-Vokale leichter diskriminiert werden als Konsonanten: "[I]m Gegensatz zu kategoriell wahrgenommenen Konsonanten [werden sie] kontinuierlich wahrgenommen"; so ist bei Vokalen die "intrakategorielle Diskriminationsfähigkeit besser ausgeprägt [...], als bei Konsonanten" (Bohn 1998: 12).
Fleges Speech Learning Model wurde dazu entwickelt, altersbedingte Unterschiede in der Perzeption und Produktion fremder Laute zu erklären (vgl. Flege 1995: 237). Gemäss Flege (1992: 565) betreffen zwei wichtige Unterschiede das Erlernen eines Phonemsystems in der L1 als Kind und das spätere Erlernen dessen als L2: Lerner einer L2 können, im Gegensatz zum Kleinkind, ihren Sprechapparat schon besser kontrollieren, und sie besitzen schon ein phonetisches System, um Sprache zu produzieren. So resultieren Fehler in der Produktion oft aus dem unangemessenen Gebrauch von früher erlernten Lautstrukturen. Diese Strukturen können sich jedoch zu neuen, korrekten L2-Strukturen weiterentwickeln, die dann wiederum auf die L1-Laute zurückwirken (vgl. ebd.: 577, 597). Die Güte dieser neuen Strukturen hängt davon ab, wie L2-Laute, die von L1-Lauten differieren, kategorisiert werden. Beim L1-Erwerb ist es für ein Kind sehr wichtig, im Prozess der Kategorisierung von Lauten in Phoneme zwischen verschiedenen Phonen Äquivalenzen herzustellen und so mit phonetischer Variation bezüglich der Lautstellung im Wort, des Sprechers, der Betontheit und dem Sprechtempo sowie mit Allophonen umgehen zu lernen. Daraus folgt aber auch, dass beim Erlernen einer L2 ähnliche Äquivalenzrelationen zwischen den L2- und den L1-Lauten hergestellt werden (vgl. Flege 1992: 573). Bei späteren L2-Lernern besteht ein höheres Risiko, solche L2-Laute mit den ähnlichsten L1-Lauten gleichzusetzen, für diese also keine neue Kategorie zu bilden und sie folglich auch nicht authentisch auszusprechen (vgl. ebd.: 597). Diese späten Lerner, die an ihrem fremdsprachlichen Akzent erkannt werden, setzt Flege (ebd.: 597) schon ab einem Alter von fünf bis sieben Jahren an: In diesem Alter steigt das segmentale Bewusstsein von Kindern, ab diesem Alter wurden akzentbeladene Äusserungen registriert; auch ändern sich Lernstrategien und die Art der Konzeptbildung, entwickelt sich die Fähigkeit, auf spezifische Aspekte von Stimuli (z. B. segmentale Einheiten) zu fokussieren sowie ein gewisses metalinguistisches Bewusstsein. Laut Fleges (ebd.: 592–595) Hypothesen etablieren Kinder in diesem Alter nicht nur die phonetischen Kategorien selbst, sie entwickeln auch einen Prototypen sowie Grenzen für jede Kategorie und eine grosse Anzahl an sprecher-, sprechtempo- und positionsbezogenen Lautvarianten, die zu diesem Prototypen und dieser Kategorie gehören, weil sie für ihre L1 nicht distinktiv sind. Dadurch, dass die einzelnen Lautkategorien grösser werden, wird der Raum9 für potentielle L2-Laute, die eine neue Kategorie bilden könnten, kleiner. So entsteht die paradoxe Situation, dass Kinder ab einem Alter, in dem sie mehr segmentales Bewusstsein entwickeln und L1-Laute effizienter perzipieren und produzieren, mehr Schwierigkeiten mit der Produktion von Lauten erfahren, die nicht zu ihrem L1-Inventar gehören (vgl. ebd.: 592f., 597).
"It is well known that adult learners are rarely, if ever, completely successful at mastering the sound system of an L2" (Flege 1992: 565): Ein seit Langem bekannter Sachverhalt, der in einer auf Lenneberg (1967) zurückgehenden und umstrittenen Hypothese resultierte, nach der es eine sog. critical period für den (insbesondere lautlichen) Erwerb einer L2 gibt. Die critical period hypothesis (CPH) basiert auf der Tatsache, dass mit der Reifung des Gehirns ein gewisser Plastizitätsverlust und die Lateralisierung des Sprachzentrums10 einhergehen und postuliert, dass nach einem gewissen Alter, meist mit dem Erreichen der Pubertät,11 der Erwerb einer Sprache nicht mehr native-like12 erfolgen kann (vgl. ebd.; Major 2001: 7; Moyer 2004: 17f.).
Flege (1992) stellt zwar mehrfach dar, dass L2-Laute nach dem Alter von fünf bis sechs Jahren anders perzipiert und kategorisiert werden, und dass frühe und späte Lerner im Allgemeinen ganz klar unterschiedlich gute Aussprachefähigkeiten erreichen, was beides mit einem stärkeren fremdsprachlichen Akzent bei späten L2-Lernern einhergeht, lässt aber einen Zusammenhang dieser Studien mit einer critical period offen. Insbesondere hebt er hervor, dass Akzent auch schon bei fünf- bis siebenjährigen Kindern auftritt, wo Lenneberg (1967: 181) noch von 11–14 Jahren sprach (vgl. Flege 1992: 590). Thompson (1991: 199) findet leichte fremdsprachliche Akzente schon bei Personen, die den L2-Erwerb mit 4 Jahren begonnen hatten. Solche Kinder, die einen starken Akzent aufweisen, wie auch sog. exceptional learners, die als späte Lerner eine sehr hohe Aussprachekompetenz erreichen, werden immer wieder gegen die CPH angeführt. Ebenfalls gegen eine CPH gerichtet ist Fleges (1992: 591) Argument, Akzent entstehe nicht durch neurologische Reifung und eine damit einhergehende verminderte Sprachlernfähigkeit, sondern durch die Entwicklung und Stabilisierung des phonetisch-phonologischen Systems als kognitiver Prozess (vgl. dazu Kapitel 2.1.2). Auch Molnár (2010) stellt die CPH in Frage; dafür untersucht sie vier hochmotivierte, "potentiell sehr erfolgreiche [L2-]Lerner" (ebd.: 5), die erst nach der Pubertät Deutsch gelernt haben, und vergleicht sie mit fünf NaS im Bezug auf ihre Aussprachekompetenz. Weitere vier NaS des Deutschen beurteilen den Grad eines eventuellen Akzents der insgesamt neun Sprecher, wobei nur einer der vier non native speakers (NNaS) Resultate erreicht, die mit denen der NaS vergleichbar sind (vgl. ebd.: 8). Molnár (ebd.: 10) folgert, dass ein muttersprachliches Niveau in der L2 auch ohne Aussprachetraining möglich ist; es muss jedoch im Auge behalten werden, dass ihre Probanden explizit aufgrund ihrer hohen Aussprachekompetenz für die Teilnahme an der Studie ausgewählt wurden. Auch im Zusammenhang mit der CPH hat Moyer (2004) untersucht, welche biologisch-experientiellen, instruktional-kognitiven, experientiell-sozialen und sozial-psychologischen Aspekte auf die phonetisch-phonologischen Fähigkeiten von Immigranten aus unterschiedlichen Herkunftsländern in Deutschland einwirken. Ihre Arbeit zeigt mit qualitativen sowie quantitativen Methoden auf, dass das Alter des Erwerbsbeginns, wenn es auch einen unabhängigen Einfluss auf das Lautsystem und die Aussprachekompetenz der untersuchten Probanden zu haben scheint, nur einer neben vielen sozialen und psychologischen Aspekten ist, die den Akzent eines Lerners mitbestimmen (vgl. ebd.: 93–96). Unter anderem spielen die Konzepte Motivation, Einstellung und Identität eine wichtige, weiter zur erforschende Rolle. Moyer wählt die Phonologie als zu untersuchende Sprachkomponente, da diese durch ihre Abhängigkeit sowohl von motorischen als auch von höheren, analytischen Kompetenzen am ehesten noch den Prozess des neurologischen Plastizitätsverlusts (und die daraus folgende Diskrepanz zwischen Produktion und Perzeption bei älteren Sprechern) illustriert und damit ein biologisches Argument für die critical period darstellen könnte (vgl. ebd.: 7). Allgemein sind die empirischen Evidenzen zur Bestätigung oder nicht der CPH widersprüchlich, jedoch gibt es "overwhelming evidence that age does influence acquisition" (Major 2001: 10). "In summary, research indicates that when acquiring L2 phonology, the younger the better, but how young and how much better remain unresolved" (ebd.: 11).
Eine Vielzahl von segmentalen, silbischen und prosodischen Aspekten der L2-Aussprache trägt zum globalen Hörereindruck eines fremdsprachlichen Akzents bei. Beim L2-Erwerb muss einerseits gelernt werden, neue Laute und Lautverbindungen zu artikulieren, also neue motorische Bewegungen anzuwenden und vor allem zu automatisieren. Andererseits gehören zum Erwerb aber auch die L2-Prosodie13, das Wissen über distinktive Merkmale, Allophone und Silben, die Anwendung von Koartikulations- und Reduktionsphänomenen usw. (vgl. Major 2001: 12; Monlár 2010: 2).
Gemäss Flege (1992: 589) sind prosodische Fehler weniger stark für den Akzent verantwortlich als segmentale. Jedoch fügt er an, dass manche segmentalen Fehler aus dem Einfluss suprasegmentaler, z. B. rhythmischer Phänomene auf die segmentale Ebene entstehen können (vgl. ebd.: 595). Demgegenüber sieht die neuere Forschung für die Wahrnehmung eines Akzents in der Prosodie eine Schlüsselrolle (vgl. Jilka/Möhler 1998; Atterer/Ladd 2004; Hirschfeld/Trouvain 2007: 171). So zeigt z. B. eine empirische Untersuchung von Missaglia (2007: 249), dass NaS bei der Beurteilung eines Akzents stärker durch suprasegmentale (46.6%) als durch segmentale Kompetenz (22.5%) beeinflusst werden.
Wie in den Kapiteln 2.1.2 und 2.2.1 beschrieben verfügen L2-Lerner im Gegensatz zu Kindern beim Erstspracherwerb schon über ein Lautsystem für die Produktion ihrer L1 und einen motorisch eingeübten Sprechapparat, was bei der Produktion von L2-Lauten Interferenzen erwarten lässt. L2-Lerner tendieren dazu, die für ihre L1 irrelevanten akustischen Unterschiede nicht wahrzunehmen, insbesondere wenn z. B. ihr eigenes Vokalsystem weniger Laute (d. h. weniger und somit grössere Kategorien) enthält als das Vokalsystem der zu erwerbenden Sprache. Sie nehmen Laute L1-spezifisch wahr, also nach der Hierarchie von distinktiven Merkmalen, die für ihre L1 relevant ist. So werden etwa einzelne distinktive Merkmale wie Aspiration oder Vokallänge je nach L1 der Sprecherin unterschiedlich gewichtet: In manchen Sprachen werden z. B. /t/ vs. /d/ durch Stimmhaftigkeit unterschieden, in anderen durch Fortis/Lenis-Kontraste, durch Längenunterschiede oder durch Aspiration. Neben dieser L1-spezifischen Wahrnehmung scheint es auch universelle Strategien für das Erlernen von Lauten zu geben: Es wurde z. B. beobachtet, dass sich Lernerinnen bei der Unterscheidung von L2-Vokalen eher auf quantitative als auf qualitative Aspekte stützen, auch wenn in ihrer L1 Vokalquantität nicht distinktiv ist. Die typologisch unmarkierten Laute, die auch Kinder als erste erwerben, sind die, welche in der L2-Aussprache mit den wenigsten phonetischen Abweichungen wiedergegeben werden (vgl. Flege 1992.: 570–571, Leather/James 1996: 293–295). Die Hypothese, dass eine grobe, universelle Reihenfolge für das Erlernen von Phonemen existiert und dass die vereinfachenden phonologischen Prozesse, die Kinder beim Erstspracherwerb anwenden, in allen Sprachen ähnlich sind, wird zwar vielenorts gestützt, muss jedoch mit einer gewissen Flexibilität gehandhabt werden (vgl. Fox 2006: 64). So zeigt Fox (ebd.: 64f.) mit ihrer Untersuchung, dass Lauterwerb durchaus auch einzelsprachlich gebunden ist: Beim Erwerb des Deutschen ersetzen z. B. 40% der Kinder in einem ihrer Entwicklungsstadien [s] und [z] durch [θ] und [ð]. Unter allen bisher beschriebenen Sprachen treten diese phonologischen Prozesse jedoch nur für das Deutsche und das Maltesische auf.
Die noch in den 1950er und 1960er Jahren geltende Ansicht der Contrastive Analysis, dass die Güte der Produktion eines L2-Lautes linear von seiner perzipierten Distanz14 zum nahesten L1-Laut abhängt, dass also ein Laut authentischer produziert wird, wenn er eine nahe Entsprechung im L1-Lautsystem hat und abweichend, wenn im L1-Lautsystem kein ähnlicher Laut vorhanden ist, muss revidiert werden. Folgende, in den Kapiteln 2.1.2 und 2.2.1 schon angetönte Kategorisierung beschreibt die Tatsachen realistischer (vgl. Flege 1992: 566, 572–577):
Aus den Kapiteln 2.1.2 und 2.2.1 oben geht hervor, dass diese Ähnlichkeit der Laute nicht nur eine artikulatorische ist, sondern sich auch auf die Perzeption der Laute bezieht, die ebenso L1-spezifisch abläuft wie deren Produktion; ein falsch wahrgenommener L2-Laut kann, wenn der Lerner seine Lautproduktion auf auditivem L2-Input aufbaut, selbstverständlich nicht authentisch ausgesprochen werden. Illustriert wird das zusätzlich durch eine Studie von Catford/Pisoni (1970: 480f.), die nachweist, dass "exotische" Laute durch rein artikulatorisches Training und ohne je gehört worden zu sein besser gelernt werden, als durch die Imitation eines Vorsprechers auf auditiver Basis.
Die oben beschriebenen, segmentalen Aspekte machen nur einen Teil des Akzents aus. Eine weitere Schwierigkeit stellen L2-Laute dar, die zwar im L1-Phonemsystem eine Entsprechung haben, jedoch in der L2 in anderen phonotaktischen Kontexten auftreten (vgl. Flege 1992: 567–569). Die Silbenstruktur in der L2 wird von Lernern oft der eigenen L1-Silbenstruktur angepasst, so wie auch Lehnwörter silbisch oft der Zielsprache angepasst werden (vgl. Major 2001: 15). Laute in unterschiedlicher Umgebung sowie in unterschiedlichen Wortpositionen werden von Lernenden unterschiedlich wahrgenommen, und auch mit unterschiedlicher Präzision wiedergegeben. So begünstigt z. B. der Wortanfang eine präzise Perzeption und Produktion: Viele Französischsprachige sprechen ein deutsches /a/ in ganz nasalisiert aus; sie kennen aber, auch in ihrer L1, sehr wohl ein nicht nasalisiertes /a/ vor /n/, z. B. in Anne. Hier ist von einem Einfluss sowohl der Umgebung als auch der Schrift auszugehen.
Wie oben beschrieben sehen viele Forscher in der Prosodie den ausschlaggebenden Faktor für fremdsprachlichen Akzent. Dies betrifft Abweichungen beim Wort- oder Satzakzent, dem Rhythmus, dem Ton und der Intonation, den Längenkontrasten und dem Timing. Einerseits irritiert es, wenn Wort- oder Satzakzent nicht oder falsch gesetzt werden, andererseits fällt aber auch eine abweichende phonetische Realisation derselben z. B. durch die falsche Kombination der Faktoren Lautstärke, Tonhöhe und Länge auf. Auch der Sprachrhythmus wird oft aus der L1 auf die L2 übertragen und ist ein starker Faktor für die Sprachwahrnehmung und -identifizierung. Typologisch werden traditionell Silbensprachen von Wort- oder Akzentsprachen unterschieden, wobei erstere phonologische Strukturen zur Optimierung der Silbe17 unterstützen, letztere solche zur Profilierung des Worts18. Die neuere Forschung sieht dabei nicht mehr zwei streng distinkte Gruppen, sondern eher ein Kontinuum – auf welchem Sprachen wie (Standard-)Deutsch, Englisch, Russisch eher bei den Wortsprachen angesiedelt sind, Französisch und Spanisch eher bei den Silbensprachen (vgl. Auer 2001: 1391–1394). Dass die Übertragung rhythmischer Muster für den fremdsprachlichen Akzent ausschlaggebend ist, zeigt z. B. Missaglia (2007: 245) für italienischsprachige Lerner des Deutschen. Atterer/Ladd (2004) präsentieren einen Ansatz, der die Intonationskurven eines Sprechers in ein Verhältnis zu segmentalen Werten setzt: Der temporale Einsatz der Tonhöhenvariation bezüglich segmentaler Stützpunkte innerhalb einer Sprache erfolgt nach einem bestimmten System, sieht aber von Sprache zu Sprache unterschiedlich aus. Diese einzelsprachlichen Muster werden durch Sprecherinnen auch in die L2 übertragen und machen so einen Teil des Akzents aus. Insbesondere konnte so ein Unterschied zwischen nord- und süddeutschen Sprechern festgestellt werden, sowohl beim Sprechen ihrer L1-Varietät, als auch in ihren englischsprachigen Äusserungen (vgl. ebd.: 191–193). Ein falsches Anwenden von Längenkontrasten kann ebenfalls zum Akzent beitragen, auch wenn Länge in der Zielsprache nicht distinktiv ist. Schliesslich beeinflusst auch das Timing der Äusserungen den Akzent eines Sprechers, wie eine Studie von Strik/Cucchiarini/Binnenpoorte (2000) zeigt (vgl. hierzu Kapitel 2.1.1).
Ein Beispiel, das die Verschiedenheit prosodischer Strukturen unterschiedlicher Sprachen und deren kulturell verschiedene Interpretation illustriert, schildert Hentschel (2000: 261): Die serbischen/kroatischen Intonationsmuster und die allgemein höhere Tonlage der Sprecher in diesen Sprachen führten sie bei ihrer ersten Reise nach Zagreb zur Annahme, alle Leute um sie herum seien am Streiten. Tatsächlich, so Hentschel (ebd.), gibt es den übereinzelsprachlichen Grundsatz, dass höhere Tonlage und lauteres Sprechen als Ausdruck von Unmut dienen – dies aber immer bezüglich der jeweils kulturell festgelegten "normalen" Tonlage und -stärke.
Wie aus dem Kapitel 2.2.2 hervorgeht, bringt der Erwerb eines unbekannten phonetisch-phonologischen Systems immer Schwierigkeiten mit sich. Ein fremdsprachlicher Akzent ist also bis zu einem gewissen Sprachniveau rein aufgrund von Interferenzphänomenen unvermeidbar. Unterschiede in der Akzentstärke zweier Lerner mit derselben L1 lassen sich teilweise erklären durch das Alter, ab welchem die L2 erworben wurde, die Aufenthaltslänge in einem Land, wo die L2 alltäglich gesprochen wird, die Frequenz, mit der die L1 noch verwendet wird, die Länge und Intensität des Sprachunterrichts und der Kontakte mit NaS, kognitive Stile, Intelligenz usw. Besonders das Erwerbsalter hat einen grossen Einfluss auf die Aussprachekompetenz einer Lernerin (vgl. Kapitel 2.2.1). Auch das Geschlecht einer Person kann auf ihren Akzent einwirken: Die Lautung von männlichen Sprechern scheint grundsätzlich stärker regional geprägt zu sein als die von Frauen (vgl. Labov 1972: 243; Major 2001: 76f.).
Dann gibt es aber, auch wenn die oben genannten Variablen konstant gehalten werden, Personen, die ihren Akzent schneller verlieren als andere. Es gibt Menschen, die fast ein Leben lang im "Ausland" leben und ihren Akzent in der L2 nie loswerden. Ebenso kommt es vor, dass ein Sprecher mit einem relativ tiefen Sprachniveau einen schwächeren Akzent hat als ein anderer, der zwar fliessend und korrekt spricht aber rein aufgrund seiner Aussprache sofort als NNaS erkannt wird. Solche individuelle Variation, die nicht mit den oben genannten Variablen zu erklären ist, beruht wahrscheinlich auf Spracheinstellungen, aber auch auf Konzepten wie "empathy, motivation, sense of identity, ego permeability, self-esteem, risktaking, anxiety, and introversion versus extroversion, musicality" (Major 2001: 66f.). Diese affektiven Variablen werden für die Forschung zum L2-Erwerb hinzugezogen, da "unterschiedliche Lernerfolge [...] oft nicht mit anderen Variablen [...] zu erklären sind" (Rost-Roth 2001: 714). Eine experimentelle Studie von Guiora u. a. (1972) untersucht den Zusammenhang zwischen Aussprachekompetenzen und dem Konzept der Empathie, und damit der ego permeability:
In einem Experiment wurden "Ego-Grenzen" von Probanden durch die Aufnahme geringer Alkoholmengen herabgesetzt. Die Aussprachekompetenz der Probanden in der L219 stieg mit der konsumierten Alkoholmenge signifikant an, mit einer Menge von 1.5 oz20 wurden die höchsten Resultate erzielt. Noch grössere Alkoholmengen setzten die Qualität der Aussprache herab. Dies bestätigt, dass Aussprachekompetenz, und so auch fremdsprachlicher Akzent, von der psychologischen Variablen "Empathie" oder ego permeability abhängt (vgl. ebd.: 426f.).
Moyer (2004: 75) weist empirisch nach, dass das Vorhandensein und die Stärke eines Akzents nicht (nur) vom Alter des Erwerbsbeginns abhängen, sondern zu einem grossen Teil aus sozial-psychologischen Variablen, insbesondere aus der Einstellung zur L2, resultieren (vgl. hierzu auch das Kapitel 3.2). Mit diesen Variablen als Einflussfaktoren für Akzentstärke kann Moyer (ebd.: 1) ihre Aussage "[b]y all accounts, we cannot yet explain either extreme of the success scale: entrenched fossilization and exceptional learning" etwas revidieren. Dieser Zusammenhang zwischen der Einstellung zur L2 und der Akzentstärke in dieser Sprache wird im empirischen Teil dieser Arbeit untersucht.
Im Folgenden soll zuerst ein Überblick über die Entstehung und die Natur von Einstellungen sowie deren Rolle für den Zweitspracherwerb gegeben und dann speziell auf Literatur zur Rolle von Einstellungen für den Lauterwerb eingegangen werden. Im dritten Teil des Kapitels werden einige prominente Möglichkeiten für das Messen von Einstellung besprochen.
Seit den 30er Jahren des 20. Jahrhunderts dient das Konzept der Einstellung oder attitude zur Erklärung menschlichen Verhaltens. Nicht nur die (Sozial-)Psychologie prägte den Begriff, auch in anderen Forschungsfeldern und insbesondere in der Kommunikations- und Spracherwerbsforschung hat sich die Idee der Einstellung als massgeblichem Einflussfaktor und hoher Erklärungskomponente etabliert (vgl. Lasagabaster 2004: 399f.).
Einstellung ist, gemäss einer prominenten Definition von Ajzen (1988: 4), "a disposition to respond favourably or unfavourably to an object, person, institution or event"; oder, etwas differenzierter nach Osgood/Suci/Tannenbaum (1975: 190),
Einstellungen sind also erworbene mentale Haltungen, die von verschiedenen Faktoren bestimmt werden – wichtige Einflussgrössen sind Familie, Erziehung, Freunde, Arbeit oder Religion, aber auch Erfahrungen mit dem Einstellungsobjekt. Tendenziell passt sich der Mensch seiner Umgebung an, so dass seine Einstellung konform ist zur in der Gruppe prominentesten Einstellung (vgl. Lasagabaster 2004: 399). Weitere, individuelle Faktoren, welche die Einstellungen einer Person gegenüber einer Sprache prägen können, sind ihr Alter und Geschlecht, ihre Sprachkompetenz sowie ihre sprachliche, soziale und kulturelle Herkunft. Baker (1992: 5) nimmt an, dass die teenage years zwischen 10 und 15 Jahren eine kritische Zeitspanne für die Entwicklung von Einstellungen gegenüber Minderheitensprachen darstellen. Dabei ist nicht das wachsende Alter kausal, sondern der daraus resultierende Sozialisierungsprozess mit den dazu gehörigen interindividuellen Beziehungen, Beeinflussungen durch Medien und peer groups und, nicht zuletzt, durch die Schule (vgl. ebd.: 41f.). Ähnliche Resultate sind auch bei Lambert (1967: 98f.) zu finden, wobei seine Studie insbesondere die negativere Bewertung des Französischen in Kanada durch Frankokanadierinnen der höheren sozialen Schichten hervorhebt. Mädchen haben in Bakers Untersuchung generell eine positivere Einstellung zur dort betrachteten Sprache Walisisch als Jungen. Hier sind wieder nicht biologische, sondern soziokulturelle Faktoren verantwortlich für den Unterschied. Dieser Einfluss des Geschlechts auf die Einstellung wird z. B. bei Siebenhaar (2000: 232) nicht bestätigt. Auch Sprachkompetenz ist ein Faktor, der in Bakers Untersuchung mit Einstellung korreliert. Wie die kausale Beziehung aussieht, ist unklar, wahrscheinlich beeinflussen sich die beiden Konzepte gegenseitig. Schliesslich werden Einstellungen zu einer bestimmten Sprache oft automatisch auch durch die Einstellungen gegenüber den Sprechern dieser Sprache und ihrer Kultur mitgeprägt (vgl. Fasold 1987: 148; Rost-Roth 2001: 715).
Die Hauptcharakteristik von Einstellungen ist ihre bewertende Natur, die sowohl eine Richtung als auch eine Intensität besitzt und so quantitativ fassbar wird (vgl. Ajzen 1988: 4; Osgood/Suci/Tannenbaum 1975: 190). Klassischerweise wird zwischen drei Komponenten der Einstellung unterschieden; der kognitiven (Meinungen, Überzeugungen), der affektiven (Gefühle dem Objekt gegenüber) und der konativen (Handlungsbereitschaft) Komponente. Dabei können die verschiedenen Komponenten der Einstellung einem bestimmten Objekt gegenüber durchaus widersprüchlich sein. So muss z. B. Handlungsbereitschaft nicht heissen, dass wirkliches Verhalten mit der ausgedrückten Einstellung identisch ist (vgl. Fasold 1987: 148; Osgood/Suci/Tannenbaum 1975: 198).21 Menschliches Verhalten ist keine konstante Grösse, sondern stark an situationale Aspekte gebunden – die minime Änderung einer Situation kann das Verhalten eines Individuums umkrempeln. So können Einstellungen bessere Voraussagen über späteres Verhalten bieten, als das beobachtete Verhalten eines Individuums: Sie können zuverlässiger gemessen werden und sind weniger stark an kontextuale Aspekte gebunden (vgl. Baker 1992: 16).
Wie menschliches Verhalten ist auch Einstellung keine starre Grösse; ihre Alteration hängt, so Lasagabaster (2004: 400), von drei Faktoren ab: Von der Kultur eines Individuums, den sozialen Gruppen, welchen dieses Individuum begegnet und seinem Temperament, seiner Flexibilität und seiner Anpassbarkeit. So kann Einstellung, etwa im Zusammenhang mit Zweitspracherwerb, sowohl als Einflussfaktor als auch als beeinflusste Grösse figurieren:
Für eine Abgrenzung des Konzepts "Einstellung" von verwandten Begriffen vgl. Baker (1992: 13–15). Hier soll nur kurz Bakers (ebd.: 14) Unterscheidung von Einstellung und Motivation wiedergegeben werden: "[A]ttitudes are object specific, motives are goal specific". In der Forschungsliteratur lassen sich jedoch global keine präzisen Relationen und Abgrenzungen zwischen den beiden Termini festmachen, sie werden von verschiedenen Autoren unterschiedlich verwendet, entspringen aber unterschiedlichen Forschungstraditionen (vgl. ebd.).
Die Forschungsliteratur zur Einstellung im Zusammenhang mit Spracherwerb fokussiert grösstenteils auf die Rolle der Einstellung als Erklärung für die individuellen Resultate beim L2-Erwerb – diese Forschungstradition geht vor allem auf Gardner/Lambert (1972) zurück (vgl. Lasagabaster 2004: 404). In Gardners (1985: 146–154) socio-educational model wird Einstellung als eine Variable neben anderen22 betrachtet, die sowohl auf den Spracherwerb einwirkt, als auch aus ihm resultiert. Es kann also davon ausgegangen werden, dass dieselben Umstände insbesondere für den Erwerb der L2-Phonologie gelten, dass also die Einstellung einer Person zu einer Sprache auf deren Akzent in dieser Sprache einwirkt, und dass deren Aussprachekompetenzen wiederum ihre Einstellung beeinflussen (vgl. auch Major 2001: 66; Missaglia 2007: 248).
Affektive Variablen als zentrale Einflussgrössen für fremdsprachlichen Akzent werden vielenorts diskutiert (vgl. z. B. Leather/James 1996: 270–272; Major 2001: 66; Hove 2002: 141f.; Moyer 2004: 38–42; Aliaga-García 2007: 1; Gut 2009: 259f.). Nun gibt es aber auch Autoren, die einen Zusammenhang zwischen der Einstellung zu einer Sprache und dem Erfolg beim Erwerb ihrer Lautung kategorisch ablehnen. So argumentiert Bohn (1998: 9f.), es sei die grössere Manipulierbarkeit der Variablen "Einstellung" und "Motivation" durch Lehrpersonen (etwa im Vergleich zur schwer zu definierenden Notion "Talent"), die ihnen eine prominente Stellung in der Frage nach dem Lernerfolg zugeschrieben hätten.
Wie (einfach) diese affektiven Variablen durch Lehrpersonen manipulierbar sind, ist jedoch fraglich (vgl. Rost-Roth 2001: 716). Thompsons (1991: 198) empirische Untersuchung zum Akzent russischer Immigranten in den USA suggeriert ebenfalls, wenn auch etwas differenzierter, dass die Rolle der Einstellung beim Spracherwerb vernachlässigbar ist: "It seems [...] that the time is ripe to lay the entire issue of attitudes and motivation to rest at least as far as the acquisition of L2 pronunciation in naturalistic settings is concerned."
Mittlerweile gibt es aber die empirische Basis, die bei Bohn vermisst wird. Die quantitativen Ergebnisse von Moyer (2004: 74–76) zeigen auf, dass sozial-psychologische Faktoren global stärker mit der Intensität des fremdsprachlichen Akzents ihrer Probanden korrelieren, als die biologisch-experientiellen, instruktional-kognitiven und experientiell-interaktiven. Ihre qualitative Untersuchung illustriert den starken Zusammenhang zwischen negativen Einstellungen und geringen Fortschritten auf der phonologischen Ebene: "[N]egative orientations do appear to impact linguistic attainment, even demonstrating that fossilization can be a matter of conscious choice" (Moyer 2004: 108). Auch Leemann (2006: 127) weist die Auswirkung der Einstellungen seiner Deutschschweizer Probanden auf deren Aussprachequalität englischer Vokale nach. Molnár (2010) konnte in ihrer Pilotstudie, die sich methodisch an Moyer (2004) orientiert, aufgrund der geringen Zahl von vier Probanden keine endgültigen Aussagen machen; es finden sich jedoch Hinweise darauf, dass Motivation (sowie Aussprachetraining) ein wichtiger Faktor zum Abbau eines Akzents darstellt. Für Schweizer Sprecher des Standarddeutschen tönt Hove (2002: 141) die eventuelle Auswirkung der Einstellung auf die Aussprache an.
Als der Aspekt von Sprache, der am widerstandsfähigsten gegenüber Änderungen ist, bildet die Aussprache einen Teil der Identität eines Sprechers und ist somit dem Einfluss von affektiven Variablen, insbesondere Einstellungen, besonders stark unterstellt (vgl. Moyer 2004: 41).
Einstellung ist ein implizites Konzept; eine Variable, die nicht direkt beobachtet oder objektiv gemessen werden kann. Um die Einstellung einer Person zu einem bestimmten Referenzobjekt zu ermitteln, muss von ihrem Verhalten oder ihren Äusserungen darauf geschlossen werden (vgl. Lasagabaster 2004: 399; Baker 1992: 11). Somit wird das Messen der Einstellung selten die präzise Einstellung einer Person perfekt widerspiegeln: Probanden können in einem Test unauthentisch antworten, um netter, offener, prestigereicher zu erscheinen, als sie es wirklich sind, sie können bewusst oder unbewusst die Antworten geben, die sozial wünschenswert sind – Baker (1992: 19) spricht in diesem Zusammenhang von einem halo effect. Auch können Probanden beim Antworten vom erahnten Ziel des Forschers und seiner Studie beeinflusst werden. Deshalb wurde bei der im Folgenden beschriebenen empirischen Untersuchung das Ziel der Studie vor der Durchführung des Tests nicht besprochen.
Einstellung kann direkt, also durch unverdeckte Fragen in Interviews, erhoben werden; aufgrund der oben besprochenen Problematik, was die Erhebung authentischer Einstellungen angeht, bietet sich eine indirekte bzw. verdeckte Erhebung an, bei welcher die befragte Person nicht weiss, dass ihre Einstellung erhoben werden soll (vgl. Fasold 1987: 149). So können Einstellungen z. B. anhand eines Assoziationsverfahrens wie dem semantischen Differential gemessen werden (vgl. Osgood/Suci/Tannenbaum 1975: 189–199). Dabei soll das Einstellungsobjekt, im vorliegenden Fall eine bestimmte Sprache, mit bipolaren Eigenschaftspaaren assoziiert werden. Probandinnen geben auf einer Skala von 1 bis 7 für jedes Eigenschsftspaar an, wo sie diese Sprache auf der Skala ansiedeln. So wird die Richtung der Einstellung durch die Wahl der jeweils positiven oder negativen Eigenschaft bestimmt, deren Intensität durch den Grad der Assoziation (vgl. ebd.: 192). Osgood/Suci/Tannenbaum (ebd.: 76f.) betonen, dass es sich hierbei nicht um einen standardisierten Test handelt – für jede Studie kann das semantische Differential, insbesondere die Eigenschaftspaare, optimal angepasst werden. Es wird aber auch darauf hingewiesen, dass im Falle einer gewünschten Vergleichbarkeit der Einstellungen gegenüber verschiedenen Konzepten dasselbe Instrument, d. h. dieselben Gegensatzpaare verwendet werden müssen (vgl. ebd.: 196). Diese Gegensatzpaare brauchen bei der Erhebung der Einstellung nicht den ganzen semantischen Raum auszufüllen, so wie das bei Osgood/Suci/Tannenbaum (ebd.: 25–30) für die allgemeine Erfassung von Bedeutungen anhand der drei interkulturell relevanten Bedeutungsdimensionen evaluation, potency und activity vorgeschlagen wird, sondern sie werden durch eine Projektion der Bedeutung auf die evaluative Dimension charakterisiert (vgl. ebd.: 36–38, 190f.). Als Legitimation des semantischen Differentials für das Messen von Einstellungen wurde die Methode von Osgood/Suci/Tannenbaum (ebd.: 192–195) sowohl mit Thurstone-, als auch mit Guttman-Skalen verglichen; mit den Resultaten von beiden dieser älteren, klassischen Methoden zur Einstellungsmessung sind die Resultate, die anhand des semantischen Differentials gemessen wurden, hoch korreliert. Einer der grossen Vorteile dieser Methode ist ihre Anwendbarkeit auf ganz unterschiedlich geartete Stimuli: "ordinary nouns, phrases, pictures, cartoons, and even sonar signals" (ebd.: 198).
Eine weitere verbreitete, ebenfalls indirekte Methode ist die von Lambert (1967: 93–95) entwickelte matched-guise Technik. Dabei werden den Personen, deren Einstellung erhoben werden soll, Aufnahmen desselben Inhalts in verschiedenen Sprachen, Dialekten oder fremdsprachlichen Akzenten vorgespielt, die von denselben mehrsprachigen Sprechern gesprochen wurden. Bei der Anordnung der Sprachproben wird darauf geachtet, dass Aufnahmen desselben Sprechers weit genug auseinander liegen, damit letztere aufgrund ihrer Stimmqualität nicht wiedererkannt werden. Durch die Bilingualität der Sprecher werden alle Variablen der Aufnahme, ausser der Sprache, gleich gehalten. Die Probanden sollen aufgrund der Stimmen, die sie hören, die Persönlichkeit der Sprecher beurteilen, z. B. anhand eines semantischen Differentials. Dabei bewerten sie aber unbewusst die jeweilige Sprache oder Varietät, sowie deren Sprechergruppen. Die matched-guise Technik wurde für eine Untersuchung der Spracheinstellungen in der Schweiz z. B. von Werlen (2000: 255–260) verwendet.
Eine der meistverwendeten, direkten Techniken zur Einstellungsmessung geht auf Likert (1932) zurück. Sie lässt Aussagen über ein Objekt, aus deren Bewertung die Einstellung der Probandin erschlossen werden kann, auf sog. Likert-Skalen von 1 bis 5 beurteilen. Die Gesamtheit der Antworten wird für jede Probandin summiert, woraus ein Wert für ihre Einstellung dem Objekt gegenüber resultiert. So geht etwa Baker (1992) in seiner Studie zum Walisischen als Minderheitensprache vor.
Erwünscht wäre generell ein multivariater Ansatz, der nicht nur die Beziehung zwischen Einstellung und einer einzelnen Variable, wie der Kompetenz, betrachtet, sondern Einstellung als einen Faktor neben anderen (vgl. Baker 1992.: 19f.; Moyer 2004: 39). Der Rahmen der vorliegenden Arbeit erlaubt für die empirische Studie keinen solchen Ansatz, es wird einzig die Variable Einstellung betrachtet. Hierzu wurde eine Erhebung anhand des semantischen Differentials durchgeführt, wie es für zahlreiche linguistische Einstellungsstudien und auch die in diesem Artikel besprochene Untersuchung von Siebenhaar (2000) verwendet wurde.
Die viersprachige Schweiz ist ein "lebendiger Widerspruch zur Idee der Nationalsprache, die seit den Humanisten des 16. Jhs. [...] immer wieder vertreten worden ist" (Schläpfer 2000: 11; Hervorh. im Orig.). Dass das Miteinander- oder Nebeneinander der verschiedenen Sprachgemeinschaften im Wesentlichen funktioniert, hat auch damit zu tun, dass sich die meisten Schweizerinnen sowohl mit der Schweiz als Ganzem, als auch mit ihrer sprachlich-kulturellen Herkunft oder Region identifizieren. Wenn zwischen verschiedenen Schweizer Regionen, früher oder heute, Reibungen auftreten, so sind sie meist auf Vorurteile zurückzuführen, die auf mangelnder Kenntnis des Anderen – und seiner Sprache – beruhen (vgl. Schläpfer 2000: 11).
In der deutschsprachigen Schweiz werden vorwiegend Dialekte gesprochen und die deutsche Standardsprache geschrieben,23 zur L1 tritt in der Primarschule Französischunterricht hinzu. Im Folgenden werden die beiden Zielsprachen, anhand welcher der Akzent von Schweizer Dialektsprechern untersucht wird, näher betrachtet. Dabei soll insbesondere auf die Einstellungen der Deutschschweizer zum Standarddeutschen und zum Französischen eingegangen werden.
Das Französische, in der Schweiz insgesamt eine Minderheitensprache, wird in der deutschen Schweiz meist als erste L2 in der Schule gelernt, das Standarddeutsche in Form eines "erweiterte[n] Erstspracherwerb[s] mit Zügen von Zweitspracherwerb" (Häcki Buhofer/Burger 1998: 137). In einer Befragung von Werlen (2000: 272) geben Deutschschweizerinnen an, das Französische v. a. im französischsprachigen Sprachgebiet gelernt zu haben; als zweitwichtigste Quelle des Französischerwerbs wird die Schule angegeben. Die Deutschschweiz zeichnet sich von anderen deutschsprachigen Regionen durch die Verwendung der Dialekte als Umgangssprache ab, unabhängig von Bevölkerungsschicht und Sprachsituation und somit ohne Stigmatisierung dieser Varietäten (Hotzenköcherle 1984: 25). Dies kann auch daran illustriert werden, dass zur Dialektattributierung in der Deutschschweiz oft das Adjektiv breit verwendet wird ("er antwortet im breiten Lokaldialekt" (Wyss 1997: 254)), wo zur Bezeichnung einer ähnlichen Qualität in anderen deutschsprachigen Ländern tief dient. Diese vertikale Dimension, wobei der Dialekt im Gegensatz zum Standarddeutschen auf einem Hoch/Tief- Gefälle die sozial schwächere Varietät darstellt, ist in der Deutschschweiz weder belegt noch verträglich mit ihrer Dialektkonzeptualisierung, wo die Dialekte als ein "horizontales Nebeneinander[...]" (Christen 2010: 289) betrachtet werden. So ist die Deutschschweiz eine der vier Regionen, anhand derer Ferguson (1959) das Phänomen der Diglossie beschreibt (vgl. Haas 2004: 81–83). Eine diglossische Situation setzt zwei Varietäten derselben Sprache voraus,24 die in einer Gesellschaft in unterschiedlichen Kontexten verwendet werden. Jede Varietät hat eine ihr zugeschriebene Funktion und diese Funktionen überschneiden sich nicht oder nur an wenigen Stellen. Für die Deutschschweizer Sprachsituation hat Kolde (1981: 65–72) den Begriff der "medialen" Diglossie geprägt: Die Deutschschweizerin spricht im Allgemeinen Dialekt, schreibt und liest aber auf Standarddeutsch – die beiden Funktionen der Varietäten lassen sich also mit Mündlichkeit und Schriftlichkeit beschreiben. So wird Standarddeutsch in der Schweizer Umgangssprache bezeichnenderweise auch "Schriftdeutsch" genannt – was zum Ausdruck bringt, wie unnatürlich das Standarddeutsch-Sprechen zwischen zwei Schweizern ist (vgl. Siebenhaar 1994: 31). Dass es zwischen dieser Mundart-Mündlichkeit und Standardsprachen-Schriftlichkeit auch Überlappungen und Grauzonen gibt ist selbstverständlich. So wird in Deutschschweizer Schulen und Universitäten, an Vorträgen, öffentlichen Reden und in den Medien generell Standarddeutsch gesprochen; private SMS sowie E-Mails und sogar manche Werbetexte werden vermehrt im Dialekt verfasst und Mundartliteratur gehört seit langem zur Schweizer Literaturlandschaft.
Befragungen ergeben, dass die Romands den Deutschschweizern sehr sympathisch sind und zwar viel sympathischer als umgekehrt die Deutschschweizer den Romands (vgl. Pedretti 2000: 278f.). Grundsätzlich steht der negativen Einstellung zum Deutschen und den wenig befriedigenden Resultaten des Deutscherwerbs bei Romands eine eher positive Einstellung zum Französischen bei Deutschschweizern gegenüber (vgl. Werlen 2000: 262–284). Eine Erhebung von Spracheinstellungen durch Werlen (ebd.: 263) zeigt, dass die befragten Deutschschweizer zum Dialekt und zum Standarddeutschen erwartungsgemäss eine positivere Einstellung haben als die Romands; sie bewerten aber insgesamt auch das Französische positiver als die frankophonen Probanden. Bei derselben Erhebung von Werlen (ebd.: 266f.) bewerteten Deutschschweizer das Französische sogar positiver als das Berndeutsche. Standarddeutsch wurde in dieser Untersuchung weniger positiv als das Französische und der Dialekt bewertet; so sprechen deutschsprachige Schweizer mit Romands eher Französisch als Standarddeutsch (vgl. Siebenhaar/Wyler 1997: 14; Werlen 2000: 282). Im Gegensatz zu früheren Erhebungen wurde das Standarddeutsche durch die Deutschschweizer jedoch erstaunlich positiv beurteilt, wenn auch Werlen (ebd.: 284) vermutet, dass dies nicht zuletzt an der Erhebungsmethode der matched-guise Technik liegt, da den Probanden ein "eindeutig schweizerisch gefärbtes" Standarddeutsch vorgespielt wurde (vgl. ebd.: 262–265). Ebenfalls zu eher positiven Resultaten, was die Einstellung der Deutschschweizer zum Standarddeutschen angeht, kommt Hove (2002: 156–170).
Um die in der Einleitung aufgestellte Hypothese zu prüfen, werden zwei Stichproben benötigt. Zum einen wurden von je vier Deutschschweizern aus Bern und aus St. Gallen Tonaufnahmen gemacht, sowohl auf Französisch, als auch auf Standarddeutsch. Ebenso wurde für jeden dieser Sprecher seine Einstellung zum Standarddeutschen und zum Französischen erhoben. Um die Annahme eines Zusammenhangs zwischen Einstellung und fremdsprachlichem Akzent prüfen zu können, musste ferner die Akzentstärke jeder Sprecherin ermittelt werden. Dafür wurde eine zweite, grössere Stichprobe von Probanden benötigt, welche die gewonnenen Sprachdaten bei einem Perzeptionsexperiment zu beurteilen hatten. Anhand der Antworten dieser Probanden kann geprüft werden, ob Einstellung eine Einflussgrösse für Akzentstärke darstellt, ob also die Sprecherin mit der negativsten Einstellung zu einer Sprache innerhalb ihrer Dialektgruppe auch den stärksten Akzent in dieser Sprache hat.
In diesem Kapitel soll die Erhebung der Daten zur ersten Stichprobe beschrieben werden, insbesondere also die Zusammensetzung der Stichprobe, die Sprechaufgaben, die Rahmenbedingungen und technischen Details zu den Tonaufnahmen sowie der verwendete Einstellungstest.
Der Homogenität des Korpus halber wurden Gewährspersonen gewählt, die sich in Alter und sozialer Schicht nicht erheblich unterscheiden. Zum Zeitpunkt der Untersuchung waren alle Gewährspersonen zwischen 20 und 30 Jahre alt. Ausserdem wurden ausschliesslich Studierende aufgenommen. Pro Dialektgebiet wurden zwei Frauen und zwei Männer gewählt, um den potentiellen Einfluss "Geschlecht" testen bzw. ausschliessen zu können. So wurden also im Ganzen acht Sprecher aufgenommen – zwar ist die Fragestellung phonetisch-phonologischen Charakters, was für die L1 wenig Variation im Bezug auf Geschlecht und Alter erwarten lässt und "anders als traditionell in den Sozialwissenschaften wird in der Dialektologie Repräsentativität eher durch qualitative Kriterien als durch solche der Mindestgruppengrösse gewährleistet" (Bellmann 1994: 35). Da aber für L2-Kompetenzen und insbesondere Akzentstärke, anders als für Dialektmerkmale,25 durchaus eine hohe individuelle Variation erwartbar ist, war es ein Anliegen dieser Studie, mehr als einen Sprecher pro Ort aufzunehmen.
Die acht Personen, auf welche die Wahl fiel, erfüllen grösstenteils die vielen Kriterien, die Bellmann (ebd.: 37) als für die qualitative Repräsentativität der Untersuchung wichtig erwähnt: Sie besitzen durch ein gewisses Interesse an Sprachen und Dialekten die nötige Bereitwilligkeit und Motivation, an dieser Untersuchung teilzunehmen und verhalten sich der Mikrophonsituation gegenüber relativ unbefangen. Ebenso fügen sie sich problemlos in das von Bellmann (ebd.: 37–39) geforderte Konzept des NaS ein: Sie sind ortsfest in dem Sinne, dass alle in Bern bzw. St. Gallen aufgewachsen sind und wohnen, dass ihre Eltern zum grössten Teil je beide Stadtberndeutsch bzw. Stadt-St. Gallerdeutsch sprechen und dass sie keine zweite Muttersprache sprechen. Tabelle 1 gibt Aufschluss über die Daten zu den einzelnen Sprecherinnen, die nach ihrer Herkunft mit "SG1–4" und "BE1–4" benannt wurden, insbesondere zum Alter, in dem sie zum ersten Mal Kontakt zu Standarddeutsch und Französisch hatten. Als Kontext dieses Erwerbs geben die meisten die Schule an, für das Standarddeutsche vereinzelt auch das Fernsehen oder, im Fall von SG3, die Familie.26
| Alter | Geschlecht | Stddt.: erster Kontakt | Frz.: erster Kontakt | |
| SG1 | 21 | w | 4 | 11 |
| SG2 | 23 | m | 6 | 10 |
| SG3 | 21 | w | 0 | 0 |
| SG4 | 25 | m | 3 | 11 |
| BE1 | 23 | m | 7 | 11 |
| BE2 | 24 | m | 7 | 11 |
| BE3 | 25 | w | 7 | 3 |
| BE4 | 28 | w | 5 | 11 |
Anders als z. B. bei Strik/Cucchiarini/Binnenpoorte (2000: 582, 585), die für ihr Experiment verschiedene Aufgaben für zwei Sprechergruppen mit unterschiedlichem Sprachniveau verwenden, wurden für die vorliegende Studie die Aufgabenstellungen für alle Sprecherinnen gleich gehalten, um eine möglichst hohe Vergleichbarkeit und damit möglichst allgemeingültige Aussagen zu erlauben. Es wurde sowohl vorgelesene Sprache als auch freie Rede aufgenommen, um einen eventuellen Unterschied der Akzentstärke in den beiden Konditionen kontrollieren zu können. Für die Vorleseaufgabe wurde die Fabel Nordwind und Sonne bzw. La bise et le soleil des griechischen Dichters Aesop gewählt, die in der Phonetik aus Gründen der Vergleichbarkeit regelmässig verwendet wird. Die Texte wurden dem Handbook of the IPA (vgl. The International Phonetic Association 1999/2003: 81, 89) entnommen. Eine wichtige Voraussetzung für die Aufgabe zur freien Rede war, dass der elizitierte Text lang genug sein sollte, um in einem Perzeptionsexperiment als Basis für Beurteilungen über die Intensität des Akzents eines Sprechers und dessen regionale Herkunft dienen zu können. Es sollte garantiert werden, dass auch Faktoren wie Sprachfluss, Pausenlängen und -häufigkeit in die Urteile der Teilnehmer am Perzeptionsexperiment einfliessen. Ebenso sollte die Aufgabe von der kognitiven Seite her möglichst einfach zu lösen sein, ohne dass die Sprecher viel Energie und Konzentration auf den Inhalt aufwenden müssen. Als weitere Prämisse sollten emotionale oder persönliche sowie potentiell "peinliche" Themen vermieden werden. Deshalb wurden die Sprecher gebeten, ihre Morgenroutine, vom Aufwachen bis zur Ankunft an der Universität oder der Arbeit, zu schildern.
Die Texte wurden mit jeder Sprecherin allein, in ihrer Wohnung oder in ihrem Büro, aufgenommen. Dies sollte einerseits zur Unbefangenheit der Sprecherinnen und zu wenig Aufwand ihrerseits beitragen, andererseits konnten so externe Lärmquellen vorwiegend ausgeschaltet werden. Vor der Aufnahme wurden die Sprecher nicht über die Fragestellung der Studie aufgeklärt, um eine Beeinflussung der Daten zu verhindern. Sie erhielten die Aufgaben nach und nach, um Überforderungsgefühle und Stress zu vermeiden. Um die Sprecherinnen sukzessive an die Mikrophonsituation zu gewöhnen, wurden jeweils die einfacheren Aufgaben zuerst präsentiert: Zunächst wurden die standarddeutschen Sprachproben aufgenommen, dann die Französischen; dabei lasen die Sprecher jeweils zuerst den Text vor, danach erst sprachen sie frei über ihre Morgenroutine. Die Texte wurden ohne vorheriges Betrachten vorgelesen und auch die Aufgabe zur freien Rede wurde, ohne längeres Nachdenken zu erlauben, direkt aufgenommen.
Den Einstellungstest füllten die Sprecher zuletzt aus – auch dies, um eine mögliche Beeinflussung der Sprachdaten durch die Konfrontation mit Gefühlen und Urteilen bezüglich der beiden Sprachen vermeiden zu können.
Für die Tonaufnahmen diente ein Gerät der Marke Fostex, Modell FR-2LE. Zusätzlich wurde ein ansteckbares Mikrophon vom Typ Sennheiser MKE 2 p-c verwendet. Das Material wurde freundlicherweise vom Phonetischen Laboratorium und dem Phonogrammarchiv der Universität Zürich zur Verfügung gestellt. Als Format der Tondokumente wurde WAVE gewählt, da diese unkomprimierten Daten eine sehr hohe Qualität garantieren.
Die Tondokumente wurden so zugeschnitten, dass nur noch der relevante Teil zu hören ist: Instruktionen der Exploratorin und Fragen vor der Aufnahme fielen weg. Innerhalb der Aufgabe wurde selbstverständlich nichts herausgeschnitten, alle Fehler, Pausen und Wiederholungen gehören zu den für das Perzeptionsexperiment verwendeten Ausschnitten. Der einzige Eingriff innerhalb der Aufnahmen betrifft Ortsnamen und Dialektwörter, welche durch einen Ton der Frequenz 250 Hz und Amplitude 0.2 ersetzt wurden. Diese Eingriffe, sowie die Schnitte, wurden mit der Software Audacity27 vorgenommen. So entstanden 32 Sprachproben, vier pro Sprecher, jeweils die Hälfte auf Standarddeutsch bzw. Französisch, vorgelesen bzw. frei gesprochen. Die Länge dieser Ausschnitte liegt jeweils zwischen 21 s und 68 s, was die bei Bauvois (1996: 297) besprochene Mindestlänge von 10–15 s zur Erkennung regionaler Merkmale erfüllt.
Die Einstellung der Sprecherinnen dem Standarddeutschen und dem Französischen gegenüber wurde für die vorliegende Studie quantitativ erhoben, um eine möglichst hohe Vergleichbarkeit der Resultate zu erzielen; qualitative Interviews wurden keine geführt. Die Sprecher haben für beide Sprachen ein semantisches Differential nach Osgood/Suci/Tannenbaum (1975) beurteilt (vgl. Kapitel 3.3 und 6.1). Die elf Gegensatzpaare wurden eigens für die vorliegende Studie aufgestellt. Gemessen wurde damit v. a. die affektive Komponente der Einstellung, die kognitive Dimension ist nur durch das Begriffspaar "nützlich — nutzlos" vertreten.
| sehr | ziemlich | ein bisschen | weder – noch | ein bisschen | ziemlich |
sehr | ||
| schlecht | gut |
Die Skala, auf der die Gegensatzpaare bewertet werden sollten, ist in Tabelle 2 dargestellt. Es sollte genau ein Kreuz pro Zeile gesetzt werden, die Angaben zu jedem Begriffspaar wurden für die Auswertung in Werte von 1 (sehr negativ) bis 7 (sehr positiv) umgewandelt, so wie in Osgood/Suci/Tannenbaum (1975: 191) vorgeschlagen.
Bei der Anordnung der Begriffspaare wurde darauf geachtet, die positiven und negativen Pole zufällig anzuordnen, um ein systematisches Ankreuzen zu vermeiden; die Gewährspersonen sollten sich zu jedem Begriff überlegen, welche Ausprägung ihnen am meisten zuspricht (vgl. Osgood/Suci/Tannenbaum 1975: 191).
Auf demselben Fragebogen wurden nebst der Einstellung der Sprecher zu den jeweiligen Sprachen auch ihre persönlichen Angaben erhoben (vgl. Kapitel 5.1.1). Der Fragebogen wurde im Familien- und Freundeskreis getestet, danach stellenweise umformuliert und erweitert.
Im Test sowie auf den Aufgabenblättern wurde der Terminus "Hochdeutsch" statt "Standarddeutsch" verwendet, weil dieser ausserhalb des linguistischen Fachs geläufiger ist. "Standarddeutsch" ist der in der vorliegenden Arbeit verwendete Terminus für die deutsche Standardsprache – er wird hier und anderswo dem umgangssprachlichen Begriff "Hochdeutsch" vorgezogen, da letzterer nicht eindeutig ist: "Hochdeutsch" bezeichnet einerseits die deutsche "Gemeinsprache", ist andererseits aber auch ein Sammelbegriff für die mittel- und oberdeutschen Dialekte gegenüber den niederdeutschen. Des Weiteren wird das "hoch" in "Hochdeutsch" im Vergleich zu den Dialekten auch als Kennzeichen einer stilhöheren, "höher einzuschätzende[n]" (Schläpfer 2000: 13f.) Sprachform (miss)verstanden. Der seit den 1970er Jahren verwendete Begriff "Standardsprache" will Wertungen vermeiden und erlaubt eine sprachenübergreifende Bezeichnung der überregionalen und normierten Sprachform (vgl. Schläpfer 2000: 13f.).
Mit einem Perzeptionsexperiment konnte die Akzentstärke der Sprecher erhoben werden; da hier keine Sprachexperten im eigentlichen Sinne befragt wurden, objektiviert eine grosse Anzahl urteilender Personen das Resultat.
Da bei diesem Perzeptionsexperiment jedem Sprecher sowohl eine regionale Herkunft, als auch eine Akzentstärke zugeordnet werden sollte (vgl. Kolly im Druck), wurde die Probandenstichprobe zweifach erstellt: Grundsätzlich wurden Schweizer Dialektsprecher benötigt, um die Sprecherinnen zu verorten und deren Akzentstärke anzugeben; die Beurteilung der Akzentstärke im Französischen sollte zur zusätzlichen Legitimierung noch durch NaS des Französischen erfolgen, da L2-Sprecher Laute anders wahrnehmen als NaS derselben Sprache (vgl. Bohn 1998: 1). Im Ganzen nahmen 80 Studierende am Perzeptionsexperiment teil:
An den Universitäten Bern und Zürich wurde das Experiment jeweils in sprachwissenschaftlichen Veranstaltungen durchgeführt, an der HEG Fribourg in Deutschlektionen. Das Alter der Probanden entspricht grösstenteils grob dem der Sprecherinnen. Die frankophonen Probanden geben als L1 durchgehend Französisch an, zwei Personen nennen zusätzlich suisse-allemand, eine Albanisch. Von den deutschsprachigen Probanden wird als L1 Berndeutsch 26 mal genannt, Zürichdeutsch 9 mal, "Ostschweizerdeutsch" vier mal, St. Galler- und Thurgauerdeutsch je zwei mal und 14 mal werden andere oder Mischdialekte genannt; zwei Personen nennen Standarddeutsch als L1, eine Englisch.
Das Experiment wurde jeweils in Seminarräumen der jeweiligen Hochschule durchgeführt, dafür wurden die Lautsprecher vor Ort verwendet. Vor dem Abspielen der Aufnahmen wurde den Probanden sowohl mündlich als auch schriftlich mitgeteilt, dass Deutschschweizer Dialektsprecher bezüglich ihrer Akzentstärke und ihrer dialektalen Herkunft beurteilt werden sollten. Ebenso wurde ausdrücklich und mit Beispielen darauf hingewiesen, dass zur Beurteilung der Akzentstärke die Aussprache, nicht etwa das allgemeine Sprachniveau der jeweiligen Sprecherin Ausschlag geben sollte.
Den deutschsprachigen Probanden wurden jeweils alle 32 Ausschnitte vorgespielt, wobei die standarddeutschen vor den französischen präsentiert wurden. Zudem waren die Sprachproben innerhalb einer Sprache jeweils zufällig permutiert worden, so dass die beiden Ausschnitte desselben Sprechers nicht nacheinander auftraten. Den französischsprachigen Probanden wurden nur die 16 französischen Ausschnitte vorgespielt. Während dem Zuhören sollte für jede Sprachprobe die Akzentstärke des Sprechers auf einer Skala von 1 (kein Akzent) bis 5 (starker Akzent) beurteilt werden; möglich war jeweils auch die Antwort "ich weiss es nicht".
Zum Schluss wurden jeweils noch Angaben zur Person jedes Probanden erhoben. Das gesamte Experiment einschliesslich des Ausfüllens dieser Zusatzangaben dauerte für die deutschsprachigen Probanden gut 30 min, für die französischsprachigen etwa 20 min. Das Untersuchungsdesign sowie die im Experiment verwendeten Fragebögen waren im Bekanntenkreis auf ihre Anwendbarkeit geprüft und für angemessen befunden worden.
Die Erhebung der Sprachdaten ist im Hinblick auf das Beobachterparadoxon28 zwar problematisch, was jedoch dadurch entschärft wird, dass die Exploratorin Standarddeutsch ebenfalls mit dem Akzent einer Deutschschweizerin spricht,29 andererseits der Code Prestige/Stigma in der Schweizer Sprachsituation eine andere Rolle spielt als in Situationen, wie sie etwa für Labovs (2006) Kaufhausexperimente relevant waren oder in Deutschland die Verwendungen von Dialekt und Standardsprache bestimmen. Deshalb sollte die Problematik der Beobachtung, gerade im Bereich der Phonologie, die im Vergleich zum Lexikon oder der Syntax weniger bewusst prozessiert wird, nicht überschätzt werden.
Die Erhebung der Einstellung ist, da sie gezwungenermassen keine Anonymität garantieren konnte, nicht unproblematisch – hier muss auf die den Effekt der Beobachtung schwächende indirekte Befragung anhand des semantischen Differentials vertraut werden; eine gewisse Hemmung, negative Assoziationen anzukreuzen, kann nicht ausgeschlossen werden. Das Ausfüllen der Fragebögen während dem Perzeptionsexperiment ist im Hinblick auf die Beobachtung unproblematisch, da die Beantwortung der Fragen auf anonymer Basis erfolgte.
Für die Auswertung der erhobenen Daten und das Erstellen der Graphiken wurde mit der Programmiersprache R30 gearbeitet. Dieses Kapitel liefert eine Vorbereitung auf die Darstellung der Resultate, indem genau dargelegt wird, wie die erhobenen Daten sortiert, kategorisiert und ausgewertet wurden.
Für die zu prüfende Hypothese, die einen Zusammenhang zwischen Akzentstärke und Einstellung postuliert, wurde mit Korrelationskoeffizienten gearbeitet. Wegen der kleinen Stichprobe von nur acht Sprechern muss hier der Begriff der statistischen Signifikanz mit Vorsicht genossen werden; deshalb wurde auch auf Korrelationstests verzichtet, die Angabe und Diskussion der Korrelationskoeffizienten ist massgebend. Im Folgenden wird das genaue Vorgehen zur Berechnung der Einstellung und der Akzentstärke sowie die Ermittlung der Korrelationskoeffizienten detailliert beschrieben.
Für die semantischen Differentiale des Einstellungstests wurde einerseits zu jedem Assoziationspaar der Mittelwert über die Angaben (Skala von 1 bis 7) aller Sprecher gebildet, um ein Polaritätsprofil zum Standarddeutschen und zum Französischen über alle Sprecher erstellen zu können. Des Weiteren wurden für jeden Sprecher die Angaben zu jedem Assoziationspaar summiert, um einen Wert (potentielle Spannweite von 11 bis 77) für die Einstellung jedes einzelnen Sprechers zu erhalten, auch dies für die semantischen Differentiale zu beiden Sprachen (vgl. Osgood/Suci/Tannenbaum 1975: 191).
Die Akzentstärke der Sprecher wurde beim Perzeptionsexperiment erhoben. Für jeden Ausschnitt sollte auf einer Skala von 1 bis 5 die Stärke des Akzents des jeweiligen Sprechers angegeben werden; die Option "ich weiss es nicht" wird ausserhalb der Skala angesiedelt und deren (wenige) Ausprägungen für die Auswertung nicht berücksichtigt. Da für die Beurteilung des dialektalen Akzents im Standarddeutschen absichtlich keine Vergleichsgrösse (Binnenhochdeutsch, Standarddeutsch, Schweizerhochdeutsch usw.) angegeben wurde, haben manche Studentinnen offensichtlich das eine, andere das andere gewählt und so wurde hier ganz unterschiedlich streng bewertet. Das ist nicht weiter problematisch, da als Mass der zentralen Tendenz der Mittelwert über alle Probanden berechnet wurde. Die Antworten der französischsprachigen Probanden sind auch sehr differenziert; es wird, auch wenn hier die eigene L1 als Vergleichsgrösse dient, nicht pauschal "starker Akzent" angekreuzt. Für die Akzentstärke jedes Sprechers im Standarddeutschen wurden für beide Ausschnitte, die vorgelesenen und die frei gesprochenen, der Mittelwert und der Median über alle Probanden berechnet. Der globale31 Akzent im Standarddeutschen wurde je Sprecher durch den Mittelwert der beiden Mittelwerte (bzw. Mediane) für die jeweiligen Ausschnitte berechnet, um die beiden Konditionen gleich zu gewichten.32 Wegen der sehr geringen Differenziertheit und somit Aussagekräftigkeit der Mediane wurde für die Datenanalyse die Weiterarbeit mit Mittelwerten vorgezogen, obwohl Mediane im Allgemeinen robuster gegenüber Ausreissern sind. Auch für die Akzentstärke der Sprecher im Französischen wurden je für beide Ausschnitte sowohl der Mittelwert als auch der Median berechnet, danach ein Mittelwert der Mittelwerte über beide Konditionen gebildet, um eine globale Akzentstärke zu erhalten – hier wurde die Prozedur mit den Antworten der deutschsprachigen und denen der frankophonen Probanden je einzeln durchgeführt. Für die weitere Datenanalyse wurde auch hier mit den Mittelwerten gerechnet; zudem wurden, um für jeden Sprecher einen Wert der globalen Akzentstärke im Französischen zu erhalten, die Urteile der tendenziell etwas strengeren frankophonen Probanden mit denen der deutschsprachigen Probanden kombiniert. Es wurde hierfür der Mittelwert über die Mittelwerte der beiden Probandengruppen gebildet, was das Urteil jedes frankophonen Probanden aufgrund der jeweiligen Stichprobengrössen etwas stärker gewichtet33 — was durchaus im Sinne einer möglichst angemessenen Lösung ist, da den frankophonen Probanden ihre eigene L1 als Vergleichsgrösse dient. Für eine Gegenüberstellung der Urteile über die globale Akzentstärke im Französischen durch die deutschsprachigen und die frankophonen Probanden vgl. Abbildung 1. Die unterschiedliche Akzentbewertung durch deutschsprachige und frankophone Probanden ist nicht signifikant: Ein zweiseitiger Wilcoxon-Test ergibt einen p-Wert von 0.5469 (für Details zu diesem Test vgl. Kapitel 6.4).
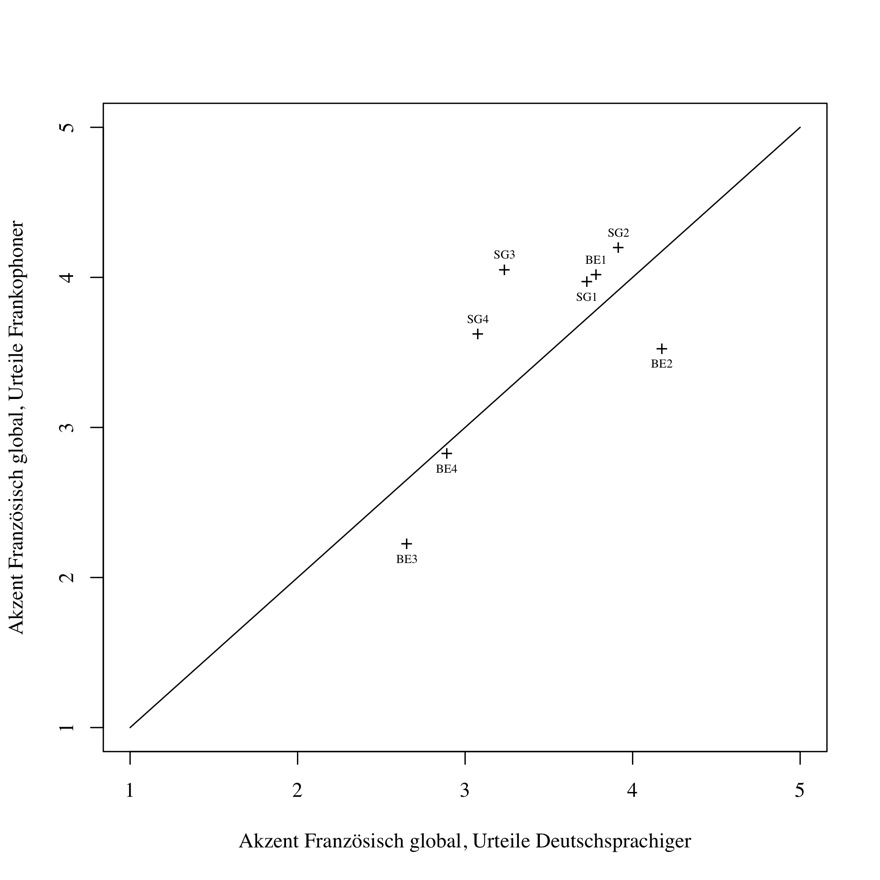 Abbildung 1: Akzent im Französischen, Urteile deutschsprachiger vs. frankophoner
Probanden: Streudiagramm
Abbildung 1: Akzent im Französischen, Urteile deutschsprachiger vs. frankophoner
Probanden: Streudiagramm
Da nicht von normalverteilten Variablen ausgegangen werden kann, wurde hier nicht mit dem (klassischen) Pearson-Korrelationskoeffizienten, sondern mit Spearmans Korrelationskoeffizienten gearbeitet, der keine Angaben an die Wahrscheinlichkeitsverteilungen der Variablen macht (vgl. Woods/Fletcher/Hughes 1986: 169f.). Zudem ist Spearmans Koeffizient als Rangkorrelationskoeffizient robuster gegenüber Ausreissern. Zur Interpretation der Korrelationskoeffizienten r werden hier die bei Gries (2009: 139) definierten Abstufungen übernommen:
Berechnet wurden die Korrelationskoeffizienten für die Einstellung zur jeweiligen Sprache und den Akzent in der jeweiligen Sprache beim Vorlesen, beim freien Sprechen sowie dem globalen Akzent über beide Konditionen.
Im Folgenden werden die Daten zur Hypothese, nach der die Akzentstärke eines Sprechers im Standarddeutschen oder im Französischen mit seiner Einstellung zur jeweiligen Sprache korreliert, präsentiert. Die Hypothese kann, wie im Weiteren gezeigt wird, für die Daten zum Standarddeutschen bestätigt werden, jedoch nicht für das Französische. Nebst der Korrelation zwischen Einstellung und Akzentstärke interessieren die Daten zur jeweiligen Variablen auch separat und, was die Akzentstärke angeht, im Zusammenhang mit der Identifizierbarkeit der Sprecher, wie sie in Kolly (im Druck) näher erläutert werden.
Die Einstellung der Sprecher zum Standarddeutschen ist durchgehend (und meist weit) negativer als ihre Einstellung zum Französischen,34 ein Resultat, das vor dem Hintergrund der Schweizer Sprachsituation und der Vorliebe der Deutschschweizer für französisches Wortgut gegenüber binnendeutschen Prägungen eigentlich nicht weiter erstaunt, jedoch aufgrund seiner Prägnanz überrascht (vgl. Tabelle 3, Abbildung 2, Hotzenköcherle (1961: 223) und das Kapitel 4 der vorliegenden Arbeit). Die eher negativen35 Einstellungen zum Standarddeutschen erklären sich nicht zuletzt dadurch, dass die "gesprochene Standardsprache in der Schweiz einen viel geringeren Stellenwert hat als in Deutschland" (Siebenhaar 1994: 33, Fussnote 3), was seinen Grund in der Diglossiesituation in der Schweiz im Gegensatz zum Kontinuum zwischen Dialekt und Standardsprache in Deutschland bzw. Österreich und die Verwendung der Dialekte "als Alltagssprache ohne soziale Stigmatisierung" hat (vgl. ebd.).
| Einstellung zum Französischen | Einstellung zum Standarddeutschen | |
| SG1 | 60 | 37 |
| SG2 | 60 | 57 |
| SG3 | 69 | 51 |
| SG4 | 65 | 43 |
| BE1 | 53 | 46 |
| BE2 | 66 | 38 |
| BE3 | 58 | 43 |
| BE4 | 60 | 36 |
Das Polaritätsprofil in Abbildung 2 illustriert die Ausprägungen der Assoziationspaare über alle Sprecher; auch hier fällt als Erstes der starke Unterschied in der affektiven Beurteilung der beiden Sprachen sowie die ähnliche Form der beiden Profile auf; bemerkenswerterweise ist das einzige Assoziationspaar, für welches das Französische und das Standarddeutsche genau gleich beurteilt wurden, auf der kognitiven Dimension angesiedelt und stellt eine instrumentale Wertung dar. Dieses gleichsam objektive Resultat bestätigt die Akkuratheit der Messmethode.
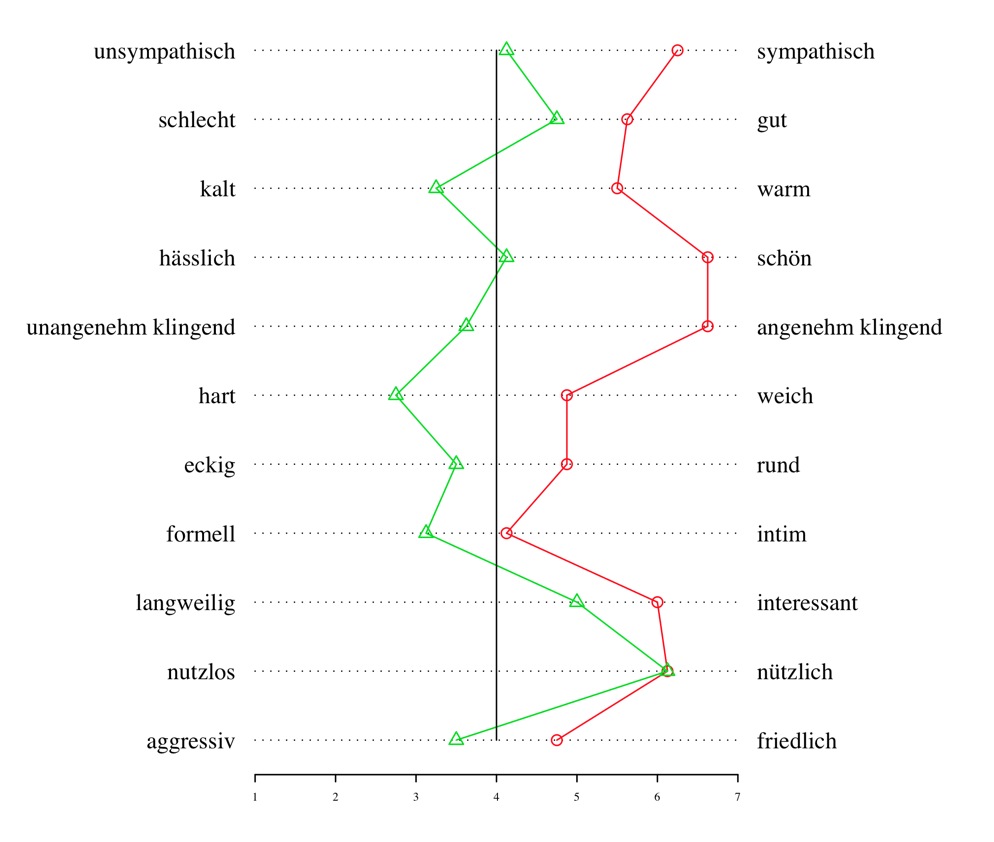 Abbildung 2: Einstellung zum Standarddeutschen (grün) und zum Französischen
(rot): Polaritätsprofile
Abbildung 2: Einstellung zum Standarddeutschen (grün) und zum Französischen
(rot): Polaritätsprofile
Es fällt auf, dass die Einstellungen der St. Galler Sprecher zu beiden Sprachen global betrachtet jeweils etwas positiver sind, als die der Berner; ebenso sind die globalen Werte zur Spracheinstellung der männlichen Sprecher leicht höher als die der weiblichen, was im Gegensatz zu den bei Baker (1992: 42–45) beobachteten Umständen steht (vgl. Kapitel 3.1). Solche Tendenzen bezüglich Geschlecht oder dialektaler Herkunft der Sprecherinnen, die sich aus den vorliegenden Daten ergeben, sollten aber wegen der kleinen Stichprobenzahl nicht überbewertet werden. Die Einstellung zum Standarddeutschen und die zum Französischen jedes Sprechers sind nicht korreliert (r = 0.0245), was auch in Abbildung 3 illustriert wird. Man muss also nicht von einer grundsätzlich eher positiven oder negativen Spracheinstellung einer Sprecherin ausgehen, sondern kann hier die Werte für beide Sprachen immer differenziert auffassen. Dies geht auch mit der Tatsache einher, dass, wenn ein Sprecher beim Französischsprechen aufgrund seines dialektalen Akzents gut regional identifiziert wurde, dies für seine standarddeutschen Ausschnitte nicht unbedingt auch gelten musste (vgl. Kolly im Druck). Dass die viel positivere Einstellung zum Französischen je Sprecher einen schwächeren Akzent im Französischen als im Standarddeutschen nach sich zieht, ist wegen der höheren Kompetenzen im Standarddeutschen nicht zu erwarten.
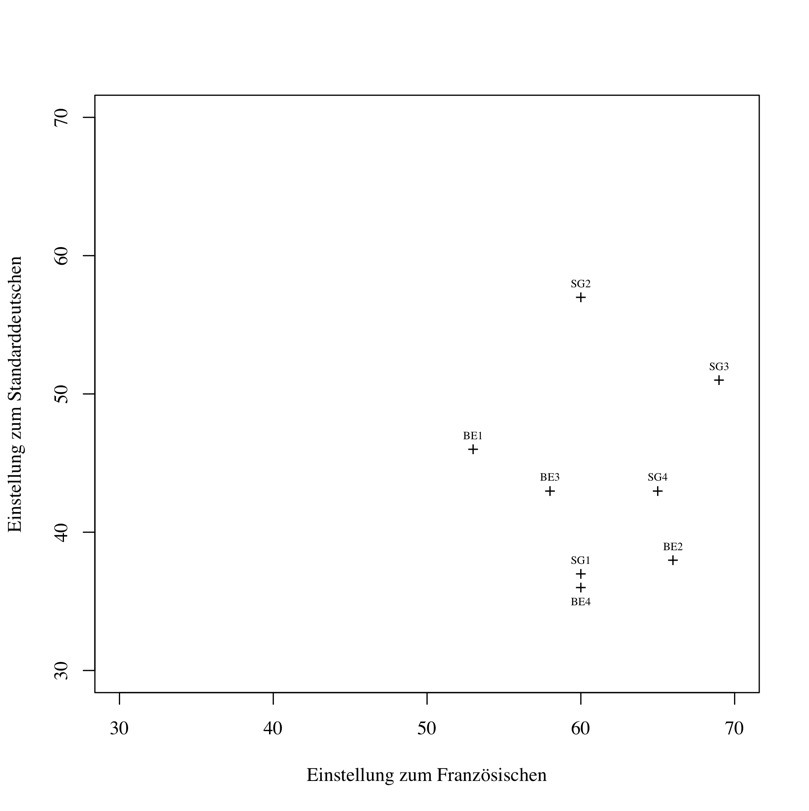 Abbildung 3: Einstellung zum Standarddeutschen und zum Französischen:
Streudiagramm
Abbildung 3: Einstellung zum Standarddeutschen und zum Französischen:
Streudiagramm
Die Mittelwerte der Akzentstärke über Vorlesen und freie Rede jedes Sprechers sind in Tabelle 4 dargestellt. Die unterschiedlich starken Akzente je Sprecher in beiden Sprachen können nicht ohne weiteres als absolute Werte verglichen werden, da die beiden Standardprachen als Vergleichsgrössen bei den Probandinnen unterschiedlich gehandhabt wurden: So wurde z. B. von den deutschsprachigen Probanden die Akzentstärke in der L2 Französisch tendenziell etwas weniger streng beurteilt als die im Standarddeutschen. Betrachtet man jedoch die relativen Akzentwerte zueinander, so kann mit Gries (2009: 139) (knapp) von einer hohen Korrelation (r = 0.5238) zwischen dem Akzent eines Sprechers im Standarddeutschen und seinem Akzent im Französischen gesprochen werden (vgl. auch Abbildung 4).
| Akzentstärke im Französischen | Akzentstärke im Standarddeutschen | |
| SG1 | 3.8499 | 3.8491 |
| SG2 | 4.0575 | 3.5656 |
| SG3 | 3.6445 | 2.7678 |
| SG4 | 3.3510 | 3.2043 |
| BE1 | 3.9017 | 3.2075 |
| BE2 | 3.8505 | 3.9221 |
| BE3 | 2.4391 | 3.1275 |
| BE4 | 2.8591 | 3.3959 |
Tabelle 4: Akzentstärke der Sprecher im Standarddeutschen und im Französischen;
kleinstmöglicher Wert: 1 (kein Akzent), grösstmöglicher Wert: 5 (starker Akzent);
Mittelwerte über beide Konditionen, gerundet auf 5 Stellen
Abbildung 4: Akzent im Standarddeutschen und im Französischen: Streudiagramm
Auffällig ist, dass der Akzent der St. Galler im Französischen global gesehen leicht höher ist, als der der Berner; für das Standarddeutsche ist keine solche Aussage möglich. Diese Beobachtung zum Akzent im Französischen widerspricht der Annahme, die sich aus Kolly (im Druck: Kapitel 3.2.2.2) ergibt: Aufgrund kontrastiver phonetischer Beobachtungen der beiden Dialekte und des Französischen würde man eher erwarten, dass St. Galler tendenziell einen schwächer wahrnehmbaren Akzent haben. Jedoch fehlen im Moment noch umfassende prosodische Untersuchungen zum St. Gallerdeutschen, die diese Erwartung untermauern oder ihr widersprechen könnten. Als weitere mögliche Gründe für die oben beschriebene Beobachtung kann die Stichprobengrösse und daraus folgende zufällige Konstellationen sowie die Überrepräsentation von Berner Dialektsprechern in der Stichprobe für das Perzeptionsexperiment genannt werden. Tendenziell ist der globale Akzent der männlichen Sprecher ein wenig stärker als der der Sprecherinnen, was mit den Forschungsergebnissen anderer phonetisch ausgerichteten Studien übereinstimmt (vgl. Labov 1972: 243; Thompson 1991: 195; Bauvois 1996: 304).
Die Akzentstärke der jeweiligen Sprecherinnen kann teilweise auch erklären, weshalb sie gut oder schlecht als St. Galler oder als Berner erkannt wurden. So ist eine hohe Akzentstärke generell ein Indikator für eine relativ gute Identifizierbarkeit, jedoch nicht zwingendermassen — manche Sprecher haben einen starken, von einem wie auch immer gearteten Standard abweichenden Akzent, deren prominenter Dialekt jedoch darin nicht sehr stark hervorzutreten scheint (vgl. Kolly im Druck).
Die Einstellungen der Sprecher zum Französischen und zum Standarddeutschen und ihr Akzent in der jeweiligen Sprache wurden, zum Testen der Hypothese, auf einen Zusammenhang geprüft. Die Frage ist, ob eine positive Einstellung zu einer Sprache mit einem schwächeren Akzent in dieser Sprache einhergeht und umgekehrt. Spearmans Korrelationskoeffizient für den Zusammenhang zwischen der Einstellung der Sprecher zum Standarddeutschen und deren globalen Akzentstärke beträgt r = -0.4192; es ist also von einem mittleren Zusammenhang auszugehen. Das Streudiagramm zu diesen Werten in Abbildung 5 illustriert diesen negativen Zusammenhang: Je tiefer der Wert zur Einstellung, desto höher ist tendenziell die Akzentstärke. Dabei fällt aber im Diagramm ein starker Ausreisser auf: Der Sprecher SG2 hat mit Abstand die positivste Einstellung zum Standarddeutschen und dafür einen relativ starken Akzent. Da dieser Sprecher auch im Bezug auf das Verhältnis seiner Einstellung zu den beiden Sprachen eine Ausnahme darstellt, indem sich bei ihm als einziger Sprecher die etwas höhere Einstellung zum Französischen nicht markant von der Einstellung zum Standarddeutschen unterscheidet, und er zum Zeitpunkt der Aufnahme verkältet war, was die angeschlagene Stimme und das langsame Sprechtempo erklärt, werden in der Tabelle 5 die Korrelationskoeffizienten für die Stichprobe mit und ohne den Ausreisser angegeben. Die Korrelation für den Datensatz ohne den Ausreisser ist jeweils sehr hoch, sowohl für den globalen Akzent als auch für die beiden Konditionen im Einzelnen. Dabei ist der Akzent beim Vorlesen mit der Einstellung stärker korreliert als der Akzent beim freien Sprechen.
Die Korrelation zwischen der Einstellung der Sprecher zum Französischen und deren globalen Akzentstärke beträgt nur r = -0.0244, es kann also nicht von einem Zusammenhang zwischen den beiden Variablen ausgegangen werden. Das Streudiagramm aus Abbildung 6 illustriert diese schwache Korrelation. Hier gibt es keinen offensichtlichen Ausreisser; BE3, die den schwächsten Akzent und den zweittiefsten Einstellungswert fürs Französische aufweist, als Ausreisser zu definieren kommt einem "fischen" nach Korrelationen (in diesem Fall auch nur mittlere Zusammenhänge) gleich. Deshalb sind die jeweiligen Werte in Tabelle 6 nur in Klammern aufgeführt.
| vollständiger Datensatz | Datensatz ohne Ausreisser SG2 | |
| Vorlesen | -0.4910 | -0.8469 |
| freie Rede | -0.4431 | -0.7748 |
| global | -0.4192 | -0.7388 |
| vollständiger Datensatz | Datensatz ohne "Ausreisser" BE3 | |
| Vorlesen | -0.0976 | (-0.4007) |
| freie Rede | -0.0244 | (-0.3336) |
| global | -0.0244 | (-0.3336) |
Relevante Korrelationswerte zwischen Einstellung und Akzentstärke sind also nur für das Standarddeutsche, nicht das Französische zu erhalten. Eine mögliche Erklärung dafür ist die Tatsache, dass das Standarddeutsche für die Deutschschweizer Sprecher eine "erweiterte" L1 darstellt und sie somit rein artikulatorisch und unbewusst eine gewisse Kontrolle darüber haben, wie stark sie ihren dialektalen Akzent dabei hervortreten lassen. Hier kommen affektive Variablen eher zum Tragen – die untersuchten Spracheinstellungen, aber auch subjektive Identität, Motivation usw. Beim Französischsprechen ist die Situation komplexer, da die L2 viel weniger gesprochen wurde; hier stossen die Deutschschweizer Sprecher zusätzlich an "natürliche Grenzen" wie Sprachkontakt, Unterrichtsfaktoren usw. Es muss aber auch im Auge behalten werden, dass nur eine kleine Stichprobe von acht Sprechern getestet wurde; der starke Unterschied zwischen den Korrelationswerten für beide Sprachen kann also auch dadurch bedingt sein.
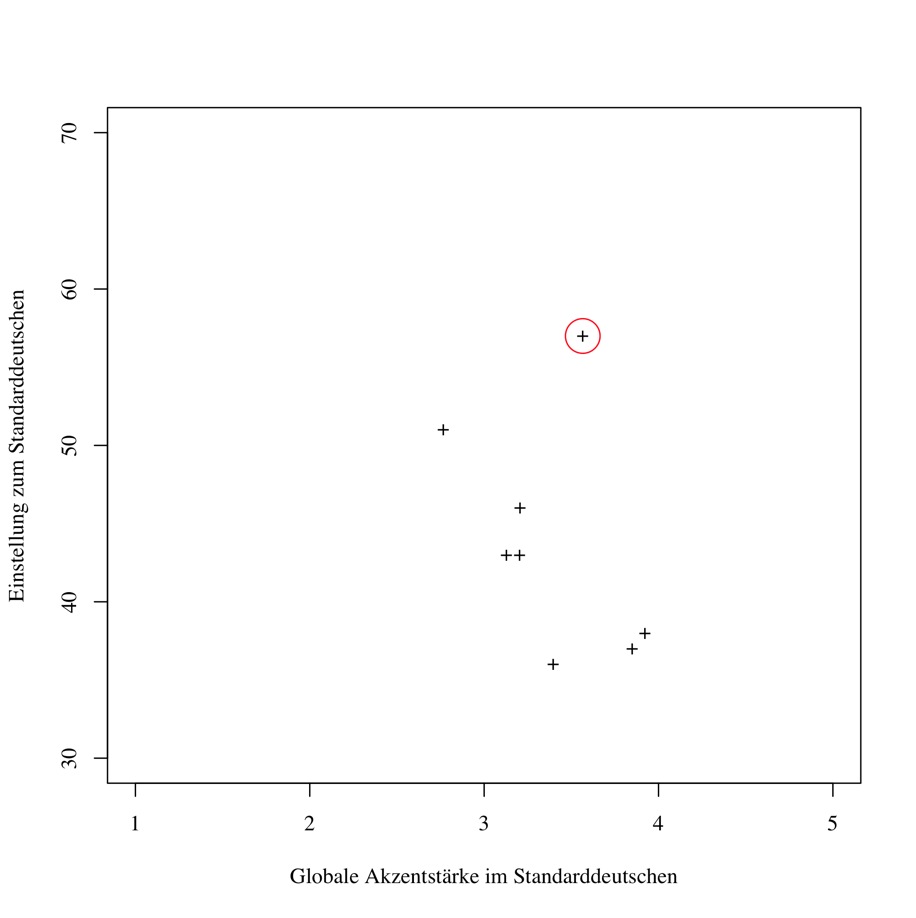 Abbildung 5: Einstellung zum und Akzent
im Standarddeutschen: Ausreisser (rot umkreist) im Streudiagramm
Abbildung 5: Einstellung zum und Akzent
im Standarddeutschen: Ausreisser (rot umkreist) im Streudiagramm
 Abbildung 6: Einstellung zum und Akzent im Französischen: Streudiagramm
Abbildung 6: Einstellung zum und Akzent im Französischen: Streudiagramm
Für den vorliegenden Zusammenhang ist im strengen, statistischen Sinne keine Aussage über die Kausalität erlaubt: Ob die Akzentstärke (teilweise) aus der Einstellung resultiert, die Einstellung aus der Akzentstärke oder ob beide Variablen von einem dritten Faktor (z. B. Identität, Empathie) abhängen, ist anhand der Korrelationskoeffizienten nicht auszumachen. Aufgrund der Ausführungen im theoretischen Teil dieses Artikels kann jedoch davon ausgegangen werden, dass sich zwar beide Konzepte gegenseitig durchdringen, insbesondere aber die Einstellung ziemlich sicher als Einflussfaktor für die Akzentstärke angenommen werden kann. Für das Standarddeutsche und die vorliegende Stichprobe kann die Hypothese 2 folglich bestätigt werden.
Für die Erhebung der Akzentstärke der Sprecher wurde jeweils vorgelesene von freier Rede unterschieden, um bei einem eventuellen Unterschied zwischen diesen beiden Konditionen so komplette Daten wie möglich zu erhalten. Bei Kolly (im Druck) zeichnet sich die allgemeine Tendenz ab, dass vorgelesene Sprache leichter regional identifizierbar ist als freie Rede. Die Akzentstärken in beiden Konditionen wurden zusätzlich auf einen Unterschied getestet.
Da die Annahme normalverteilter Daten etwas gewagt wäre, wurde hier statt eines t-Tests ein Wilcoxon-Vorzeichentest durchgeführt, der keinerlei Voraussetzungen an die Wahrscheinlichkeitsverteilung der Daten macht (vgl. auch Gries 2009: 199–205). Im Folgenden wird mit einem 95%-Signifikanzniveau gearbeitet: Alle Behauptungen, insbesondere das Verwerfen der Nullhypothese, können mit einer Sicherheit von 95% aufgestellt werden.
Als Nullhypothese H0 gilt die Annahme, dass zwischen freier Rede und vorgelesener Sprache kein signifikanter Unterschied in Akzentstärke vorliegt. Die Alternativhypothese H1 postuliert einen Unterschied in der Akzentstärke. Ein zweiseitiger Test ergibt für die Akzentunterschiede im Standarddeutschen einen p-Wert von 0.0234, also einen signifikanten Unterschied zwischen der Akzentstärke in den beiden Konditionen. Die Nullhypothese kann verworfen werden. Wird zusätzlich mit der Alternativhypothese H1, dass der Akzent beim Vorlesen stärker ist, einseitig getestet, so erhält man einen p-Wert von 0.0117. Somit gilt, zumindest für die vorliegende Stichprobe, dass der Akzent bei vorgelesener standarddeutscher Sprache grundsätzlich stärker hervortritt als beim freien Sprechen, was z. B. den Behauptungen bei Major (2001: 71f) und den Ergebnissen bei Hove (2002: 139), wo in der vorgelesenen Sprachprobe standardnähere Lautungen beobachtet wurden, widerspricht (vgl. auch Kapitel 2.1.1). Für die französischen Ausschnitte wurde genau gleich vorgegangen; hier ergibt der p-Wert bei zweiseitigem Testen 0.3828; bei einseitigem Testen mit der Alternativhypothese, dass der Akzent beim Vorlesen stärker hervortritt, erhält man einen p-Wert von 0.1914, also insbesondere keine statistisch signifikanten Resultate. Die Tendenz, dass auch beim Französischen die Akzentstärke in vorgelesener Sprache höher ist, kann also nicht statistisch untermauert werden; jedoch wird sie dadurch bestärkt, dass die Sprecher SG3 und SG4 von einigen Probanden (fälschlicherweise) für Romands gehalten wurden, dies aber nur beim freien Sprechen — was also darauf schliessen lässt, dass ihr dialektaler Akzent in dieser Kondition schwächer hervortritt (vgl. Kolly im Druck).
Als mögliche Erklärung dafür, dass hier die Akzentstärke beim Vorlesen, zumindest im Standarddeutschen, stärker hervortritt, kann die Fokussierung des Sprechers beim Vorlesen auf das Erkennen und das mündliche Umsetzen der Schriftsprache und eine daraus folgende Vernachlässigung der phonetischen Präzision in der Aussprache gegeben werden.
Akzentforschung ist keine ledigliche Spielerei, sie findet durchaus praktische Anwendungen – nicht zuletzt in forensischen Kontexten, wo L1- wie auch L2-Sprachmaterial mitunter authentifiziert oder (lokal) identifiziert werden muss.
Doch auch im didaktischen Kontext spielt Akzent eine grössere Rolle, als ihm allgemein zugesprochen wird: Ausspracheschwierigkeiten können das Erlernen der korrekten Morphologie einer Sprache beeinträchtigen. Den Zusammenhang zwischen Lauterwerb und dem Erwerb der Morphologie weisen sowohl Attaviriyanupap (2009: 336) als auch Werlen (1991) in empirischen Studien zum Deutscherwerb von thailändischen Immigrantinnen bzw. einer französischsprachigen Lernerin in der Schweiz nach. Tatsächlich scheint der Erwerb der verbalen Flexionsendungen für die untersuchten Personen dadurch, dass ihnen die Aussprache z. B. von Auslautkonsonanten und -konsonantenclustern Schwierigkeiten bereitet, erheblich erschwert. In einem stärkeren Fokus auf phonetische Merkmale einer Fremdsprache im didaktischen Kontext liegt deshalb auch Potential zur Verbesserung des Sprachniveaus auf anderen Ebenen des Sprachsystems.
Weiter ist bekannt, dass L2-Sprecher mit einem starken Akzent anders wahrgenommen werden als solche, welche die Zielaussprache besser beherrschen: Eine Abweichung von der erwarteten Aussprache bewirkt bei der Hörerin immer eine gewisse Irritation und dies proportional zur Stärke der Abweichung. Ein besseres Verständnis davon, wie das phonetisch-phonologische System einer L2 erworben wird, kann in didaktischen Implikationen resultieren, was wiederum auf die Kommunikationen der Lerner einwirkt. Gerade die Einstellung zur L2, deren Korrelation mit Akzentstärke in der vorliegenden Arbeit, zumindest für das Standarddeutsche, nachgewiesen wurde, kann durch eine verbesserte Aussprache und dadurch erleichterten Kontakt zu NaS beeinflusst werden. Einstellung wirkt sich wiederum auf die Intensität eines fremdsprachlichen Akzents aus; auch das ein wichtiger Befund für didaktische Richtlinien. So kann sich Akzentforschung längerfristig womöglich auch positiv auf interkulturelle Kommunikationen, gerade in der Schweiz, auswirken. Gegenwärtig scheint die Situation noch die im Zitat oben beschriebene zu sein. Denn das rire, das ist dort so zu intepretieren:
1 Im Gegensatz zum Wort- oder Satzakzent, die auf eine stärkere Betonung bestimmter Silben referieren, wird in dieser Studie Akzent definiert als "[t]he cumulative auditory effect of those features of pronunciation which identify where a person is from, regionally, or socially" (Crystal 2003: 3). zurück
2 Im Folgenden werden weibliche und männliche Formen abwechselnd verwendet; mit der Nennung der einen Form ist in den meisten Fällen auch die andere mitgemeint. zurück
3 Terminus in diesem Zusammenhang von Häcki Buhofer/Burger (1998: 137): "Der Typ von Spracherwerb [...] lässt sich am besten als erweiterter Erstspracherwerb mit einigen Zügen von Zweitspracherwerb charakterisieren"; im Folgenden wird deshalb auch für das Standarddeutsche die Abkürzung "L2" verwendet. zurück
4 Von Zweitspracherwerb wird meist dann gesprochen, wenn die Sprache in einem Kontext erworben wird, wo sie in der Umgebung der Lerner alltäglich vorkommt (vgl. Häcki Buhofer/Burger 1998: 14). zurück
5 Bei diesen Merkmalen waren die Ergebnisse der automatischen Messung mit denen der professionellen Bewerter korreliert. zurück
6 Laut Hirschfeld/Trouvain (2007: 173) verstanden über 50% deutscher native speakers (NaS) die Assertion es regnet nicht oder völlig falsch, wenn Lerner des Deutschen die Betonung auf die letzte Silbe net legten. Oft wurde das segmental “Verstandene” der suprasegmentalen Struktur angepasst und z. T. sogar als eine Frage interpretiert (es ist nett?). zurück
7 Im Gegensatz zur abstrakten phonologischen Ebene. zurück
8 “Voice onset time [is] the time lapse [...] between the release of a plosive sound and the onset of voicing” (Ashby/Maidment 2005: 200). zurück
9 Konkret stellt sich Flege (1992: 593f.) dabei den Vokaltrakt bzw. ein Vokalviereck oder den akustischen, durch die Formanten F1 und F2 definierten Vokalraum vor. zurück
10 Die beiden Gehirnhälften sind unterschiedlich spezialisiert; die Sprachfunktion scheint bei den meisten Menschen in der linken Hälfte angesiedelt zu sein (vgl. Major 2001: 7). zurück
11 So bei Lenneberg (1967: 168f.); vgl. Molnár (2010: 2) für eine Darstellung verschiedener Auffassungen im Bezug auf die obere Altersgrenze, wobei die Spannweite von einem bis zu grob zwölf Jahren reicht. zurück
12 In der L2 so hohe perzeptive und produktive Sprachkompetenz, dass sie sich nicht von der Kompetenz eines NaS unterscheiden lässt (vgl. Lightbown/Spada 2006: 202). zurück
13 Diese schliesst folgende Phänomene ein: Längenkontraste, Timing, Ton, Intonation, Rhythmus und lexikalischen sowie Satzakzent (“Akzent” hier im Sinne von “Betonung”). zurück
14 Zur Messung dieser Distanz schlägt Flege (1992: 573) verschiedene Methoden vor, so z. B. das Ansetzen oder nicht eines anderen IPA-Symbols für den L2-Laut oder die auditive Wahrnehmbarkeit eines Unterschieds durch NaS und NNaS. zurück
15 Es kommt vor, dass manche L2-Laute identisch zu L1-Lauten sind. Meist unterscheiden sie sich aber, wenn auch nur minim, in ihrer Qualität, Quantität, Amplitude oder in den phonotaktischen Regeln, die sie betreffen (vgl. Flege 1992: 572). zurück
16 Ein typisches Beispiel dafür sind sprachspezifische VOT-Werte bei plosiven Konsonanten (vgl. Flege 1992: 578). zurück
17 Kein oder ein schwacher Wortakzent, kaum Reduktionen (Vollvokale auch in Nebensilben), typologisch unmarkierte Silben, Vermeiden eines Aufeinandertreffens von Vokalen durch Konsonantenepenthesen, Vereinfachte Silbifizierung durch Geminaten usw. (vgl. Auer 2001: 1395–1398). zurück
18 Markierung der Wortgrenze (z. B. Glottisschlag, Auslautverhärtung im Standarddeutschen), Reduktion oder Komprimierung unbetonter Silben (z. B. zu Schwa im Standarddeutschen), distinktiver Wortakzent, Erlauben komplexer Silbenstrukturen wie Konsonantencluster und des Aufeinandertreffens von Vokalen usw. (vgl. Auer 2001: 1395–1398). zurück
19 Hier wurden Ausspracheübungen in Thai durchgeführt. zurück
21 Ein Experiment von LaPiere (1934: 231–234) hat z. B. ergeben, dass einem chinesischen Paar in einem von 251 Restaurants und Hotels in den USA die Bedienung verweigert wurde. Als man sich sechs Monate später bei diesen Restaurants schriftlich informierte, gaben 92% der Lokale an, einem chinesischen Paar würden sie den Eintritt verweigern. zurück
22 Gardner (1985: 153) nennt in einer der Versionen seines Modells die Einflussfaktoren integrativeness, motivation, attitudes toward the learning situation, alle resultierend aus kulturellen Überzeugungen, sowie language aptitude. zurück
23 Vgl. hierzu Kapitel 4.1. zurück
24 Zur Diskussion, Kritik und Verteidigung des Diglossie-Begriffs und den entsprechenden Varietäten vgl. Haas (2004). zurück
25 Zumindest in der Schweiz, wo die Dialekte mit keinerlei Stigma behaftet sind. zurück
26 SG3 ist nicht zweisprachig aufgewachsen, war aber durch ihre entferntere Verwandtschaft mit den beiden Sprachen schon früh in Kontakt. zurück
27 Version 1.3.11-beta, vgl. http://audacity.sourceforge.net/. zurück
28 "[...] that our goal is to observe the way people use language when they are not being observed" (Labov 1972: 61). zurück
29 Vgl. die Forderungen Hotzenköcherles (1962b: 127) zum sprachlichen Verhalten der Exploratoren bei der Erhebung von Dialektdaten im Feld. zurück
30 Version 2.11.1, vgl. R Development Core Team (2010). zurück
31 D. h. über Vorlesen und freie Rede. zurück
32 Durch die allfällige ungleiche Anzahl von Antworten "ich weiss es nicht" beim vorgelesenen und beim frei gesprochenen Ausschnitt sowie bei den verschiedenen Sprechern hätte der Mittelwert über alle Ausprägungen zu beiden standarddeutschen Ausschnitten je Sprecher eine jeweils ungleiche Gewichtung der beiden Konditionen zur Folge. zurück
33 Gewichtung der frankophonen Probanden = 0.75, Gewichtung der deutschsprachigen Probanden = 0.25 (vgl. Stichprobengrössen in Kapitel 5.2.1). zurück
34 Ein zweiseitiger Wilcoxon-Vorzeichentest ergibt für den Unterschied den hochsignifikanten p-Wert von 0.0078; für Details zum Test vgl. Kapitel 6.4. zurück
35 Bei fünf von acht Sprechern liegt der Wert unter der "neutralen Einstellung" von 44 (vgl. Tabelle 3 und deren Beschriftung). zurück
Kaiser, Renato (2011): "Je ne suis pas vraiment sûr". Text zum bilingualen Poetry Slam 07.04.2011 Centre Fries, Fribourg.
Wyss, Verena (1997): Verdecktes Spiel. Roman. Zürich/Frauenfeld: Nagel & Kimche.
Ajzen, Icek (1988): Attitudes, Personality and Behaviour. Milton Keynes: Open University Press.
Aliaga-García, Cristina (2007): "The Role of Phonetic Training in L2 Speech Learning". Proceedings of the Phonetics Teaching & Learning Conference UCL. http://www.phon.ucl.ac.uk/ptlc/proceedings/ptlcpaper_32e.pdf. Stand 5.9.2010.
Ashby, Michael/Maidment, John (2005): Introducing Phonetic Science. Cambridge: Cambridge University Press. (= Cambridge Introductions to Language and Linguistics).
Attaviriyanupap, Korakoch (2009): Hochdeutsch als Zweitsprache. Spracherwerb von thailändischen Immigrantinnen in der Schweiz. Bern: Lang.
Atterer, Michaela/Ladd, Robert (2004): "On the Phonetics and Phonology of 'Segmental Anchoring' of F0. Evidence from German". Journal of Phonetics 32/2: 177–197.
Auer, Peter (2001): "Silben- und akzentzählende Sprachen". In: Haspelmath, Martin/König, Ekkehard/Oesterreicher, Wulf (Hrsg.): Language typology and language universals. An international handbook. Sprachtypologie und sprachliche Universalien. Ein internationales Handbuch. Teilband 2. Berlin/New York, de Gruyter: 1391–1399. (= Handbücher zur Sprach- und Kommunikationswissenschaft 20).
Baker, Colin (1992): Attitudes and Language. Clevedon/Philadelphia/Adelaide: Multilingual Matters. (= Multilingual Matters 83).
Bauvois, Cécile (1996): "Parle-moi, et je te dirai peut-être d'où tu es". Revue de Phonétique Appliquée 121: 291–309.
Bellmann, Günter (1994): Einführung in den Mittelrheinischen Sprachatlas. Tübingen: Niemeyer.
Bohn, Ocke-Schwen (1998): "Wahrnehmung fremdsprachlicher Laute. Wo ist das Problem?". In: Wegener, Heide (Hrsg.): Eine zweite Sprache lernen. Empirische Untersuchungen zum Zweitspracherwerb. Tübingen, Narr: 1–20. (= Tübinger Beiträge zur Linguistik. Series A: Language Development 24).
Catford, John C./Pisoni, David B. (1970): "Auditory vs. Articulatory Training in Exotic Sounds". The Modern Language Journal 54/7: 477–482.
Christen, Helen (2010): "Was Dialektbezeichnungen und Dialektattribuierungen über alltagsweltliche Konzeptualisierungen sprachlicher Heterogenität verraten". In: Anders, Christina Ada/Hundt, Markus/Lasch, Alexander (Hrsg.): "Perceptual dialectology". Neue Wege der Dialektologie. Berlin/New York, de Gruyter: 269–290. (= Linguistik – Impulse und Tendenzen 38).
Crystal, David (2003): A Dictionary of Linguistics and Phonetics. 5. Auflage. Oxford: Blackwell.
Ehlich, Konrad (1986): "Xenismen und die bleibende Fremdheit des Fremdsprachensprechers". In: Hess-Lüttich, Ernest W. B. (Hrsg.): Integrität und Identität. Tübingen, Narr: 43–54. (= Forum angewandte Linguistik 8).
Fasold, Ralph (1987): The Sociolinguistics of Society. Introduction to Sociolinguistics, Volume I. Oxford/New York: Blackwell. (= Language in society 5).
Flege, James E. (1992): "Speech Learning in a Second Language". In: Ferguson, Charles A./Menn, Lise/Stoel-Gammon, Carol (Hrsg.): Phonological Development. Models, Research, Implications. Maryland, York Press: 565–604.
Flege, James E. (1995): "Second Language Speech Learning. Theory, Findings, and Problems". In: Strange, Winifred (Hrsg.): Speech Perception and Linguistic Experience. Issues in Cross-Language Research. Timonium, York Press: 233–277.
Fox, Annette V. (2006): "Evidence from German-Speaking Children". In: Hua, Zhu/Dodd, Barbara (Hrsg.): Phonological Development and Disorders in Children: A Multilingual Perspective. Cleveland/Buffalo/Tortonto: 56–80.
Gardner, Robert C. (1985): Social Psychology and Second Language Learning: The Role of Attitudes and Motivation. London: Arnold. (= Social Psychology of Language 4).
Gries, Stefan T. (2009): Statistics for Linguistics with R. A Practical Introduction. Berlin/New York: Mouton de Gruyter. (= Trends in Linguistics 208).
Guiora, Alexander Z. u. a. (1972): "The Effects of Experimentally Induced Changes in Ego States on Pronunciation Ability in a Second Language. An Exploratory Study". Comprehensive Psychiatry 13/5: 421–428.
Gut, Ulrike (2009): Non-Native Speech. A Corpus-Based Analysis of Phonological and Phonetic Properties of L2 English and German. Frankfurt: Peter Lang.
Haas, Walter (2004): "Die Sprachsituation der deutschen Schweiz und das Konzept der Diglossie". In: Christen, Helen (Hrsg.): Dialekt, Regiolekt und Standardsprache im sozialen und zeitlichen Raum. Beiträge zum 1. Kongress der Internationalen Gesellschaft für Dialektologie des Deutschen, Marburg/Lahn 5.–8. März 2003. Wien, Praesens: 81–110.
Häcki Buhofer, Annelies/Burger, Harald (1998): Wie Deutschschweizer Kinder Hochdeutsch lernen. Der ungesteuerte Erwerb des gesprochenen Hochdeutschen durch Deutschschweizer Kinder zwischen sechs und acht Jahren. Stuttgart: Steiner. (= Zeitschrift für Dialektologie und Linguistik; Beihefte 98).
Hentschel, Elke (2000): "Cold at Heart – some Personal Observations on Intercultural Misunderstandings". In: Harden, Theo/Witte, Arnd (Hrsg.): The Notion of Intercultural Understanding in the Context of German as a Foreign Language. Bern usw., Lang: 255–270. (= German Linguistic and Cultural Studies 7).
Hirschfeld, Ulla/Trouvain, J¨urgen (2007): "Teaching Prosody in German as a Foreign Language". In: ders./Gut, Ulrike (Hrsg.): Non-Native Prosody. Phonetic Description and Teaching Practice. Berlin/New York, de Gruyter: 171–187.
Hotzenköcherle, Rudolf (1961): "Zur Raumstruktur des Schweizerdeutschen". Zeitschrift für Mundartforschung 28/3: 207–227.
Hotzenköcherle, Rudolf (1984): Die Sprachlandschaften der deutschen Schweiz. Hrsg. von Niklaus Bigler und Robert Schläpfer. Aarau usw.: Sauerländer. (= Sprachlandschaft 1).
Hove, Ingrid (2002): Die Aussprache der Standardsprache in der deutschen Schweiz. Tübingen: Niemeyer. (= Phonai; Texte und Untersuchungen zum gesprochenen Deutsch 47).
Jilka, Matthias/Möhler, Gregor (1998): "Intonational Foreign Accent. Speech Technology and Foreign Language Teaching". In: Proceedings of Speech Technology in Language Learning, 25.–27.05.1998, Marholmen, Sweden: 113–116.
Kolde, Gottfried (1981): Sprachkontakte in gemischtsprachigen Städten. Vergleichende Untersuchungen über Voraussetzungen und Formen sprachlicher Interaktion verschiedensprachiger Jugendlicher in den Schweizer Städten Biel/Bienne und Fribourg/Freiburg i. Ue. Wiesbaden: Steiner. (= Zeitschrift für Dialektologie und Linguistik; Beihefte 37).
Kolly, Marie-José (im Druck): "Akzent auf die Standardsprachen: Regionale Spuren in "Schweizerhochdeutsch" und "Français fédéral".
Labov, William (1972): Sociolinguistic Patterns. Oxford.
Labov, William (2006): The Social Stratification of English in New York City. 2nd edition. New York.
Lambert,Wallace (1967): "A Social Psychology of Bilingualism". Journal of Social Issues 23/2: 91–109.
Lameli, Alfred (2004): Standard und Substandard. Regionalismen im diachronen Längsschnitt. Stuttgart. (= ZDL-Beiheft 128).
LaPiere (1934): "Attitudes vs. Actions". Journal of Social Forces 13/2: 230–237.
Lasagabaster, David (2004): "Attitude/Einstellung". In: Ammon, Ulrich u. a. (Hrsg.): Sociolinguistics. An International Handbook of the Science of Language and Society. Soziolinguistik. Ein internationales Handbuch zur Wissenschaft von Sprache und Gesellschaft. Bd. 1. 2., vollst. neu bearb. und erw. Aufl. Berlin/New York, de Gruyter: 399–405. (= Handbücher zur Sprach- und Kommunikationswissenschaft 3)
Leather, Jonathan/James, Allan (1996): "Second Language Speech". In: Ritchie, William C./Bhatia, Tej K. (Hrsg.): Handbook of Second Language Acquisition. San Diego usw.: Academic Press: 269–316.
Leemann, Adrian (2006): Acoustic Analysis of Swiss English Vowel Quality. Bern, Universität Bern. (= Arbeitspapiere des Instituts für Sprachwissenschaft 42).
Lenneberg, Eric H.: Biological Foundations of Language. New York usw.: Wiley.
Lightbown, Patsy M./Spada, Nina (2006): How Languages are Learned. 3. Aufl. Oxford: Oxford University Press.
Likert, Rensis (1932): "A Technique for the Measurement of Attitudes". Archives of Psychology 140: 1–55.
Major, Roy C. (2001): Foreign Accent. The Ontogeny and Phylogeny of Second Language Phonology. Mahwah NJ/London: Erlbaum.
Missaglia, Federica (2007) : "Prosodic Training for Adult Italian Learners of German. The Contrastive Prosody Method". In : Trouvain, Jürgen/Gut, Ulrike (Hrsg.): Non-Native Prosody. Phonetic Description and Teaching Practice. Berlin/New York : 236–258.
Molnár, Heike (2010): "Der Einfluss des Alters auf die Aussprachekompetenz in der L2. Ergebnisse einer Pilotstudie mit DaZ-Lernern". Zeitschrift für interkulturellen Fremdsprachenunterricht 15/1: 1–21. http://zif.spz.tu-darmstadt.de/jg-15-1/beitrag/Molnar1.htm. Stand: 6.8.2010.
Moyer, Alene (2004): Age, Accent and Experience in Second Language Acquisition. An Integrated Approach to Critical Period Inquiry. Buffalo NY: Multilingual Matters. (= Second Language Acquisition 7).
Osgood, Charles E./Suci, George J./Tannenbaum, Percy H. (1975): The Measurment of Meaning. Urbana/Chicago/London: University of Illinois Press.
Pedretti, Bruno (2000): "Die Beziehung zwischen den schweizerischen Sprachregionen". In: Bickel, Hans/Schläpfer, Robert (Hrsg.): Die viersprachige Schweiz. Aarau/Frankfurt am Main/Salzburg, Sauerländer: 269–307. (= Sprachlandschaft 25).
R Development Core Team (2010): R. A Language and Environment for Statistical Computing. Wien: R Foundation for Statistical Computing. http://www.R-project.org. Stand: 1.6.2010.
Rost-Roth, Martina (2001): "Zweitsprachenerwerb als individueller Prozess IV: Affektive Variablen". In: Helbig, Gerhard u. a.: Deutsch als Fremdsprache. Ein internationales Handbuch. Teilband 1. Berlin/New York, de Gruyter: 714–722. (= Handbücher zur Sprach- und Kommunikationswissenschaft 19).
Schläpfer, Robert (2000): "Einleitung". In: Bickel, Hans/Schläpfer, Robert (Hrsg.): Die viersprachige Schweiz. Aarau/Frankfurt am Main/Salzburg, Sauerländer: 11–15. (= Sprachlandschaft 25).
Siebenhaar, Beat (1994): "Regionale Varianten des Schweizerhochdeutschen. Zur Aussprache des Schweizerhochdeutschen in Bern, Zürich und St. Gallen". Zeitschrift für Dialektologie und Linguistik 61: 31–65.
Siebenhaar, Beat (2000): Sprachvariation, Sprachwandel und Einstellung: Der Dialekt der Stadt Aarau in der Labilitätszone zwischen Zürcher und Berner Mundart. Stuttgart: Steiner. (= Zeitschrift für Dialektologie und Linguistik. Beihefte 108).
Siebenhaar, Beat/Wyler, Alfred (1997): Dialekt und Hochsprache in der deutschsprachigen Schweiz. 5., vollst. überarb. Aufl. Zürich: Pro Helvetia.
Strik, Helmer/Cucchiarini, Catia/Binnenpoorte, Diana (2000): "L2 Pronunciation Quality in Read and Spontaneous Speech". In: Proceedings of the 6th International Conference on Spoken Language Processing, Beijing, China, 16-20 October 2000: 582-585.
The International Phonetic Association (1999/2003): Handbook of the International Phonetic Association. A Guide to the Use of the International Phonetic Alphabet. Cambridge: Cambridge University Press.
Thompson, Irene (1991): "Foreign Accents Revisited. The English Pronunciation of Russian Immigrants". Language Learning 41/2: 177–204.
Werlen, Iwar (1985): "Zur Einschätzung von schweizerdeutschen Dialekten". In: Werlen, Iwar (Hrsg.): Probleme der schweizerischen Dialektologie. 2. Kolloquium der Schweiz. Geisteswissenschaftlichen Gesellschaft. Problèmes de la dialectologie suisse. 2e Colloque de la Société suisse des sciences humaines. Fribourg, Editions Universitaires Fribourg: 195–266.
Werlen, Iwar (1991): Mit französischem Akzent sprechen. Analyse eines Beispiels. Neuchâtel: Comm. Interuniversitaire Suisse de Linguistique Appliquée. (= CILA 54). Sonderdruck aus: René Jeanneret (Hrsg.)(1991): 700 ans de contacts linguistiques en Suisse.
Werlen, Iwar (Hrsg.)(2000): Der zweisprachige Kanton Bern. Bern/Stuttgart/Wien: Haupt.
Woods, Anthony/Fletcher, Paul/Hughes, Arthur (1986): Statistics in Language Studies. Cambridge: Cambridge University Press.