Dass die Sprachenvielfalt in Europa gleichzeitig einen kulturellen Reichtum und ein praktisches Problem darstellt, ist kaum zu bestreiten. In dem Maße, in dem dieser Reichtum allgemein als erhaltenswert anerkannt wird, müssen – bei zunehmender Verdichtung sprachraumübergreifender Kontakte – daher auch entsprechende Lösungen der praktischen Schwierigkeiten gesucht werden, wenn es nicht zu der paradoxen Haltung kommen soll, die vielfach gegenüber Dialekten eingenommen wird: erhalten: ja – verwenden: nein. Eine Option, die immer noch vernachlässigt wird, aber in jüngerer Zeit zunehmend auf Interesse stößt, ist rezeptive Mehrsprachigkeit (vgl. z. B. Arntz 1997; Lüdi 2007). Die Erleichterung des Erwerbs bei einer Konzentration auf die passive Kompetenz ist besonders in einem Zusammenhang augenfällig, der die europäische Sprachenvielfalt charakterisiert: Die vielen Einzelsprachen gliedern sich in eine überschaubarere Zahl von Sprachfamilien, innerhalb derer eine relativ enge Verwandtschaft besteht, was den rezeptiven Zugang stark erleichtert, sobald jemand eine Sprache aus einer Familie beherrscht. Vergleichsweise leicht ist das Verstehen einer nicht gelernten Fremdsprache auf der Basis von Verwandtschaft zwischen der betreffenden Fremdsprache und der L1 bzw. einer gut beherrschten Lx insbesondere bei geschriebener Sprache – hierfür wird im Folgenden der Terminus Interkomprehension verwendet1.
Die Möglichkeit der Interkomprehension beruht grundsätzlich darauf, dass innerhalb von Sprachfamilien wie der romanischen, der slawischen oder der germanischen aufgrund der historischen Verwandtschaft weitreichende Gemeinsamkeiten bestehen, in der Grammatik und vor allem im Lexikon. Wesentlich dabei sind allerdings eben nicht die historischen Beziehungen, sondern deren Reflexe in den modernen Sprachen, die nicht immer auf Anhieb zu erkennen sind. Das betrifft bei den germanischen Sprachen vor allem den Wortschatz22: Ob germanische Interkomprehension eine realistische Option nicht nur für Linguisten ist, entscheidet sich in erster Linie damit, ob die etymologischen Beziehungen in der modernen Gestalt der Wörter noch erkannt werden können. Durch unterschiedlichen Lautwandel in den germanischen Einzelsprachen wird dies oft erheblich behindert. So sind z. B. nl. duif und dt. Taube zwar kognat und haben sich beide lautgesetzlich entwickelt, haben aber graphemisch und phonemisch überhaupt kein gemeinsames Segment mehr.
Die Eurocom-Methode 3 setzt hier auf eine systematische Darstellung der (orthographisch erfassten) phonologischen Korrespondenzen (vgl. Lutjeharms/Möller 2007 für die germanischen Sprachen oder Klein/Stegmann 2000: 61–97 für die romanischen, vgl. a. Tafel et al. 2009: 93–122 für die slawischen). Im Unterschied zu den traditionellen Darstellungen von Lautgesetzen in der historischen Phonologie muss dabei allerdings auf den Rückgriff auf ein historisches Bezugssystem verzichtet werden, sodass ein relativ hoher Anteil von in beiden Richtungen uneindeutigen Korrespondenzen 4 in Kauf genommen werden muss, vgl. etwa Tab. 1 für die dentalen Plosive:
| andere germ. Sprachen | Deutsch | ||
| t | nl. zout, kat schwed. tunga |
z, tz | Salz, Katze Zunge |
| nl. bont, rat schwed. mitt |
t, tt | bunt, Ratte Mitte | |
| nl. toch schwed. tak |
d | doch Dach | |
| nl. uit, vat, voet schwed. ut, fat, fot |
s, ss, ß | aus, Fass, Fuß | |
| nl. hert schwed. hjort |
sch | Hirsch | |
| d | nl. dwingen dän. hede |
z, tz | zwingen Hitze |
| nl. doof, dadel schwed. mod, väder |
t, tt | taub, Dattel Mut, Wetter | |
| nl. dief schwed. siden |
d | Dieb Seide | |
| nl. ud, vide; dän./no. flid | s, ss, ß | aus, wissen, Fleiß | |
| nl. donder dän. mand; dän./no. kilde |
– | Donner Mann, Quelle | |
Tab. 1: Differenziertheit der germanischen Lautentsprechungen am Beispiel t und d
Die statistische Relevanz dieser Lautentsprechungen ist zwar sehr unterschiedlich (vgl. Möller 2007: 289f. zu nl.-dt. Entsprechungen), aber eine Grenzziehung zwischen relevant und irrelevant ist oft schwierig und wird durch die Tatsache erschwert, dass Korrespondenzen mit geringer Typefrequenz z. T. in Wörtern mit hoher Tokenfrequenz auftreten. Als erhebliches Problem für eine didaktisch orientierte Darstellung kommt hinzu, dass derartige Zusammenstellungen einen demotivierenden Umfang annehmen, wenn Vollständigkeit angestrebt wird (vgl. Berthele et al. 2011), aber auch nicht überzeugend sein können, wenn sie sich als zu lückenhaft erweisen. Gleichzeitig zeigt die Erfahrung aus Interkomprehensions-Übungen aber, dass auch das weitgehende Ignorieren derartiger Listen von Entsprechungsregeln erfolgreiche Kognatenerkennung nicht ausschließt. Schon aus Gründen der Ökonomie und der Motivation ist es also von wesentlichem Interesse, herauszufinden, welche Beziehungen spontan durchsichtig sind und welche nicht, und die explizite Vermittlung auf letztere zu konzentrieren. Hierfür sind empirische Untersuchungen unerlässlich. Eine intuitive Beurteilung der Erkennbarkeit von Kognaten durch Linguisten bzw. Lehrwerk-Autoren ist demgegenüber sehr fragwürdig, da die Erkennbarkeit einmal bekannter Zusammenhänge im Nachhinein kaum noch eingeschätzt werden kann – der Zustand der "Unschuld" ist nicht wieder herzustellen.
Im Folgenden steht also diese Frage im Zentrum: Welche phonologischen Beziehungen erlauben auch Nicht-Fachleuten das Erkennen von (geschriebenen) Kognaten, d. h. das Herstellen der Verbindung zwischen einem Wort einer unbekannten Sprache und einem damit verwandten Wort einer bekannten Sprache, und welche Unterschiede verhindern, dass dies gelingt? Die hier vorgestellten Ergebnisse können dabei erste Anhaltspunkte sein, für eine zuverlässige Antwort sind allerdings noch ausgiebige weitere Untersuchungen erforderlich.
Das Interesse richtet sich zunächst einmal auf die Erkennung isolierter Wörter, um den Einfluss ko(n)textbasierter semantischer Vorannahmen auszuschalten. Da sich dies weit von der realen Situation der Kognatenerkennung beim Lesen entfernt und das Inferieren auf der Basis ko(n)textbedingter Vorannahmen häufig gerade als zentrale Technik bei der Interkomprehension eingestuft wird (vgl. z. B. Berthele 2007; Castagne 2004: 96), ist diese Entscheidung rechtfertigungsbedürftig. Abgesehen von untersuchungsmethodischen Problemen (vor allem mangelnde Kontrollierbarkeit solcher Inferenzen) sind hier vor allem zwei Aspekte anzuführen, die sich auf die besonderen Bedingungen interkomprehensiven Lesens im Vergleich zum Lesen in bekannten Fremdsprachen bzw. zum Lesen in der L1 beziehen. Zum einen ist die Strategie des Überbrückens unbekannter Elemente über Inferieren nur dann brauchbar, wenn der Kotext verstanden wurde. In der Interkomprehension besteht jedoch auch der Kotext aus zu erschließenden Wörtern, die Inferenzbrücke würde also nicht auf Ufergelände, sondern ihrerseits auf Wasser aufsetzen müssen, wenn keine anderen Anhaltspunkte zur Verfügung stünden. Ohne die Bedeutung der Semantik beim realen Texterschließen in Frage zu stellen, muss also konstatiert werden, dass Inferieren als einzige Strategie in diesem Fall nicht ausreicht. Zum anderen beinhaltet Inferieren natürlich ein gewisses Risiko. Wie Berthele (2007) unterstreicht, umfasst Lesen in der Interkomprehension, wie in der L1, immer ein Zusammenwirken von Bottom-Up- und Top-Down-Prozessen. Auch beim muttersprachlichen Lesen (oder Lesen in einer gut beherrschten Fremdsprache) wirken nach verbreiteter Auffassung immer kon- und kotextbasierte Inferenzen bei der Informationsverarbeitung mit (vgl. Rickheit/Strohner 2003: 567). Ein entscheidender Unterschied zur Interkomprehension besteht allerdings darin, dass beim (genauen) Lesen in einer bekannten Sprache angestrebt wird, die Ergebnisse von Top-Down- und Bottom-Up-Prozessen in Einklang zu bringen, sodass Unstimmigkeiten zwischen inferenzbasierter Wortselektion und visuellem Input normalerweise auffallen. Nur dadurch sind überhaupt Überraschungen beim Lesen möglich. In der Interkomprehension existiert jedoch in der Bottom-Up-Verarbeitung zumindest ein unsicherer Schritt, wenn nicht gar eine Lücke zwischen der Wahrnehmung der Zeichenkette und der Wortselektion – die ja in einer anderen als der gelesenen Sprache stattfinden muss. Wenn dies allein durch verstärkte Nutzung der Top-Down-Prozesse ausgeglichen wird und Unstimmigkeiten also nicht mehr wahrgenommen werden, ist das Erkennen überraschender Textinhalte ausgeschlossen und die Gewissheit eines richtigen Verstehens ist stark beeinträchtigt. Anzustreben wäre daher, soweit möglich auch hier die Ansätze einer Bottom-Up-Verarbeitung zu stärken und zumindest eine Art Plausibilitätskontrolle (vgl. dazu u.) hinsichtlich der Relation zwischen selektiertem Wort und Zeichenkette zu ermöglichen, um die Texterschließung besser abzusichern und von reinem Raten abzuheben.
Die Frage, ob/in welcher Weise eine "Interkomprehensions-Kompetenz" schrittweise erworben bzw. vermittelt werden kann (s.a. Meißner 2004), bedarf zumindest für die germanischen Sprachen noch ausgiebiger weiterer Forschung und Diskussion. Einige rudimentäre Überlegungen dazu, worin Interkomprehensions-Kompetenz eigentlich bestehen kann, sind jedoch notwendig, um im Rahmen einer empirischen Untersuchung von Kognatenerkennung überhaupt Erfolg und Misserfolg definieren zu können. Letztendlich ist das Ziel eine echte Lesekompetenz in bestimmten Sprachen bzw. im Idealfall in allen Sprachen einer Familie, was auch die Kenntnis spezifischer grammatischer Strukturen und "normalen" Wortschatzerwerb umfasst. Auf dem Weg dorthin müsste jedoch die maximale Nutzung der Familien-Gemeinsamkeiten im Zentrum stehen, also in erster Linie der Erwerb von Techniken, die deren Erkennung und einen sinnvollen Umgang damit erlauben und andererseits (soweit wie möglich) falsche Annahmen auszuschließen helfen. Das betrifft z. B. die Erkennung (und Beachtung) syntaktischer und morphologischer wie auch semantischer Hinweise und die Koordination der Schlüsse aus verschiedenartigen Anhaltspunkten. Im lexikalischen Bereich müsste das spezifische Ziel einer Interkomprehensions-Kompetenz m. E. im Erwerb von Techniken der Kognatenerkennung bestehen, die in möglichst vielen Fällen zum Erfolg führen und möglichst viele Fehler vermeiden helfen – und nicht darin, dass im konkreten Fall jedes Wort richtig erkannt wird (was einen Erwerb der Sprachen voraussetzen würde). Wenn ein Kognatenverhältnis angenommen wird, das, synchron gesehen, phonologisch durchaus möglich wäre und nur zufällig nicht zutrifft, ist dies insofern zunächst einmal positiv zu beurteilen, während das richtige Erkennen bei einem lautlich irregulären Kognatenverhältnis oder einem bedeutungsäquivalenten Wort, das eigentlich nicht kognat ist, unter Umständen einen eher fragwürdigen Erfolg darstellt, nämlich wenn es ein Hinwegsehen über Differenzen voraussetzt, die zu ignorieren normalerweise in die Irre führt (z. B. bei nl. tijd und engl. time, nl. tegen und dt. gegen oder schwed. små und engl. small5). Das impliziert natürlich, dass eine eindeutige Identifikation der richtigen Kognaten unter mehreren lautlich plausiblen Kandidaten auf der Wortebene in sehr vielen Fällen nicht gelingen kann – was jedoch beim Texterschließen zumeist kein Problem darstellt, weil die Auswahl unter den alternativen Möglichkeiten in der Regel durch den semantischen und syntaktischen Kontext gestützt wird. Zu erwerben wäre also die Fähigkeit, lautlich sinnvolle Kognaten-Hypothesen aufzustellen und diese am Kontext zu überprüfen. Für die Verfolgung derartiger didaktischer Ziele ist jedoch zunächst einmal zu klären, von welchen Voraussetzungen dabei ausgegangen werden kann, d. h. worauf sich die spontane Kognatenerkennung stützt.
Der Schwerpunkt wird im Folgenden auf die Durchsichtigkeit der phonologischen Beziehungen zwischen Kognaten gelegt. Das bedeutet nicht, dass graphische Aspekte (wie charakteristische Graphemkombinationen) keine Rolle bei der Erkennung spielen – deren Bedeutung ist in weiteren Untersuchungen ebenfalls zu verfolgen. Zunächst soll aber der Fokus auf dem phonetisch-phonologischen Aspekt liegen, der für eine erfolgreiche Kognatenerkennung erheblich relevanter ist – auch wenn es sich um geschriebene Sprache handelt – und tatsächlich auch bei den Erschließungsversuchen von Laien im Zentrum zu stehen scheint. Die Leseforschung hat gezeigt, dass die Umsetzung des Schriftbilds in eine phonologische Repräsentation eine wesentliche Rolle schon bei der Worterkennung im muttersprachlichen Lesen spielt (vgl. z. B. Rastle/Brysbaert 2006). Bei Kognatenerkennung ist darüber hinaus zu beobachten, dass die Suche nach einer L1-Entsprechung oft von wiederholtem lautem Aussprechen des fremden Worts begleitet wird, dass mit der Suche also mehr oder weniger bewusst bei der Lautgestalt angesetzt wird (vgl. Möller/Zeevaert 2010: 228–230). Diese Strategie ist sinnvoll, sinnvoller als eine Orientierung an den Graphien, schon weil die Orthographie einzelsprachlichen, teilweise willkürlich festgelegten Konventionen folgt (vgl. etwa nl. kwaal und dt. Qual), aber auch, weil auf phonetischer Ebene auch bei Auseinanderentwicklungen noch eher Gemeinsamkeiten zu erkennen sind (vgl. u.) – und schließlich eventuell auch deswegen, weil wegen der in gesprochener Sprache immer anzutreffenden Varianz die Toleranz gegenüber Abweichungen und die Flexibilität im Umgang damit beim Klangbild größer sein dürfte als beim Schriftbild.
Festzuhalten ist allerdings, dass es hier immer um eine Phonologisierung der graphischen Repräsentation geht und nicht um die korrekte Aussprache, die ja oftmals gar nicht bekannt ist und sich gegenüber der oft konservativeren Orthographie z. T. erheblich mehr in Richtung einzelsprachlicher Besonderheiten entwickelt hat (besonders deutlich etwa im Dänischen). Daraus ergibt sich die Frage, nach welchen Graphem-Phonem-Korrespondenzregeln sich die vermutete Aussprache der fremden Wörter richtet. Die nächstliegende Annahme dürfte sein, dass die Regeln der L1 zugrundegelegt werden (zumindest dann, wenn diese mit der Fremdsprache enger verwandt ist). Tonaufnahmen von Erschließungstests mit deutschsprachigen Probanden bestätigen dies, selbst für Grapheme wie <oo>, die im Deutschen selten sind und im Englischen, das den Probanden auch geläufig war, erheblich häufiger vorkommen (vgl. Möller/Zeevaert ebd.). Für die Erkennung von Wörtern in anderen germanischen Sprachen durch deutschsprachige Erschließer wird hier also davon ausgegangen, dass die deutschen Graphem-Phonem-Korrespondenzregeln verwendet werden, zumindest, soweit die entsprechenden Graphien im Deutschen existieren.
Für eine Untersuchung von Intuitionen hinsichtlich der Beziehungen zwischen Kognaten müssen die Ähnlichkeiten zwischen Wortpaaren beschreibbar bzw. kategorisierbar sein. Dafür wird im Folgenden das Verfahren verwendet, das der Berechnung der Levenshtein-Distanz zugrundeliegt (vgl. z. B. Heeringa 2004: 121–135): Zwei Zeichen- oder Lautketten werden segmentweise verglichen und der unaufwändigste Weg wird ermittelt, auf dem über Substitution, Einfügung und Tilgung von Segmenten die eine Kette in die andere überführt werden kann. Das hat im vorliegenden Zusammenhang den Vorteil, dass synchrone Ähnlichkeit unter gänzlicher Ausblendung der historischen Entwicklung erfasst werden kann (anders als z. B. in dem Verfahren von Heggarty/McMahon/McMahon 2005, vgl. ebd.: 56ff.). Als unterschiedliche Segmente werden hier – im Sinne der vorausgehenden Überlegungen zur Rolle der phonologischen Repräsentation – Grapheme eingestuft, denen im Deutschen unterschiedliche Phoneme zugeordnet sind.
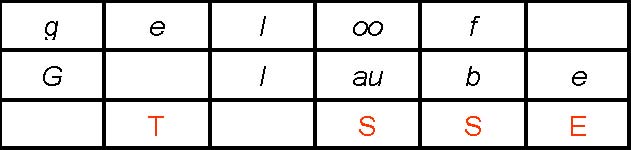
Abb. 1: Transformation nach dem Levenshtein-Verfahren
(4 nötige Operationen: 1 Tilgung, 2 Substitutionen, 1 Einfügung)
Bei der einfachsten (= ungewichteten) Version derLevenshtein-Distanz wird die Distanz zwischen zwei Wörtern nach der (relativen oder absoluten6) Anzahl solcher Operationen bemessen. Dieses Maß wird teilweise auch in der Forschung zur Interkomprehension verwendet, um die Ähnlichkeit zwischen Kognaten zu quantifizieren. Ob dies tatsächlich dem Empfinden von Laien entspricht, ist allerdings fraglich (das würde bedeuten, dass der Unterschied von Taube zu duif als genauso groß empfunden würde wie der zu mees oder kat). Nach den Ergebnissen von Heeringa (2004) kommt zwar die ungewichtete Levenshtein-Distanz dem Empfinden von Laien tatsächlich näher als verfeinerte Verfahren. Seine Überlegung "Perhaps [...] for dialect speakers all distances between different segments are the same" (ebd.: 185) – die sich auf den Höreindruck bezieht – ist allerdings zumindest nicht auf die Erkennung geschriebener Kognaten durch Deutschsprachige zu übertragen, wie zu zeigen sein wird7.
Auch wenn das ungewichtete Levenshtein-Verfahren für eine Messung der Durchsichtigkeit von Kognatenbeziehungen sicherlich zu undifferenziert ist, eignet es sich jedoch, um zunächst einmal eine grobe Kategorisierung der Übereinstimmungen und Unterschiede zwischen Wörtern vorzunehmen, anhand derer die Intuitionen von Laien detaillierter untersucht werden können. Ob eine segmentbezogene Betrachtung dem Ähnlichkeitsempfinden im Bezug auf gedruckte Wörter überhaupt angemessen ist, bliebe zwar noch weiter zu überprüfen 8. Für eine erste Annäherung erscheint es jedoch sinnvoll, die synchronen Beziehungen zwischen Kognaten in dieser Weise genauer zu erfassen und die Schwierigkeiten bei der Erkennung dazu in Beziehung zu setzen, welche Substitutionen, Insertionen und Tilgungen jeweils nötig sind, um von dem unbekannten zu dem vertrauten Wort zu gelangen. Für eine weitere Beschreibung und Klassifizierung solcher Modifikationen werden dann phonetische bzw. artikulatorische Kategorien herangezogen, um genauere Erkenntnisse hinsichtlich der tatsächlichen Schwierigkeit verschiedener Operationen zu gewinnen, die u.a. auch für das Einführen einer sinnvollen Gewichtung in das Messverfahren nötig sind9.
In den im Folgenden beschriebenen Tests wurde versucht, die Intuitionen von Studierenden hinsichtlich der Ähnlichkeit zwischen Kognaten mit unterschiedlichen phonologischen Divergenzen bzw. Korrespondenzen im Rahmen "echter" Kognatenerkennungs-Aufgaben zu prüfen. (Eine Abfrage von Einschätzungen zu Beziehungen zwischen isolierten Phonemen bzw. den entsprechenden Graphemen oder zwischen isolierten Silben erscheint schon aus Gründen der Motivation wenig erfolgversprechend. Eine Abfrage zur Ähnlichkeit zwischen Phantasiewörtern dürfte ebenfalls zu Motivationsproblemen führen und brächte darüber hinaus über die Assoziationen zu existierenden Wörtern auch schon wieder weitere Schwierigkeiten in Spiel). Das größte Problem bei Aufgaben dieser Art liegt darin, dass es nicht genügt, den Probanden Testitems mit unterschiedlichen Lautentsprechungen zwischen den Items und den entsprechenden deutschen Kognaten vorzulegen und dann pro Testitem (bzw. pro Lautentsprechungstyp) den Anteil richtiger Lösungen zu ermitteln: Es gibt meistens andere Lösungsmöglichkeiten, die zwar de facto nicht richtig sind, aber richtig sein könnten – zumindest ohne historisches Zusatzwissen (synchron ist kein Hinweis darauf zu erkennen, dass nl. been – dt. Bein – nicht dt. Biene entspricht, vgl. nl. veel – dt. viel, nl. mijn – dt. Mine). Die Wahrscheinlichkeit, dass die richtige Lösung gefunden wird, hängt also immer auch von der Existenz und relativen Wahrscheinlichkeit (Ähnlichkeit usw.10) solcher Alternativen ab, die im Sinne der oben angestellten Überlegungen auch unter "erfolgreiche Kognatenerkennung" verbucht werden müssten, bei denen aber das phonologische Verhältnis zum Testitem anders ist als bei den richtigen deutschen Kognaten. Daher wurde hier versucht, diesen Faktor bewusst mit einzuplanen: Die Testitems sind mit wenigen Ausnahmen so gewählt, dass sie mit der gleichen Zahl von Änderungen (vorwiegend Substitutionen) in unterschiedliche deutsche Wörter transformiert werden könnten11, z. B. lof in Lob, Hof oder Lauf, oder kand in Kind, Hand oder Rand. Es gibt also fast immer mehrere Lösungen, die eine gleich niedrige ungewichtete Levenshtein-Distanz zum Testitem aufweisen. Dies erinnert an das Konzept der phonologischen oder orthographischen "Nachbarn" (so verwenden Kürschner/Gooskens/van Bezooien 2008: 90f. denn auch diesen Terminus), der Sachverhalt unterscheidet sich allerdings doch: Zum einen handelt es sich um "Nachbarn" in einer andern Sprache, und im vorliegenden Fall stellen weder Orthographie noch tatsächliche phonologische Gestalt des Testitems den Bezugspunkt dar, sondern eine Phonologisierung der orthographischen Form nach den Regeln einer anderen Sprache. Zum anderen ist die Beschränkung der Betrachtung auf potentielle Lösungen mit nur einem abweichenden Segment zu eng, wie sich zeigen wird (vgl. u.). Teilweise erfordert die richtige Lösung auch mehr Änderungen als andere mögliche. Die Frage ist immer, welche dieser möglichen Änderungen die Probanden vorziehen, also für die näherliegenden Entsprechungen halten. Hierbei sind noch weitere Faktoren zu beachten: Die Wahrscheinlichkeit, dass eine mögliche Lösung gewählt wird, hängt vermutlich auch von der Frequenz dieses deutschen Worts ab, nicht nur von der angenommenen Wahrscheinlichkeit der phonologischen Beziehungen. Die möglichen Lösungen sollten also möglichst geläufige Wörter sein, was allerdings nicht immer ganz realisierbar ist. Ein noch wichtigerer Faktor bei deutschen Probanden, die alle über gewisse Englischkenntnisse verfügen, ist die Existenz und Frequenz von entsprechenden Kognaten im Englischen. Um diesen Faktor auszuschalten, wurden hier nur Testitems gewählt, zu denen es im (nicht-peripheren) englischen Wortschatz keine Kognaten gibt12. Schließlich war auch noch darauf zu achten, dass möglichst keine Analogie-Beziehungen zwischen verschiedenen Items bzw. deren Lösungen herzustellen waren bzw. im Lauf des Tests möglichst keine Entsprechungsregeln erschlossen werden konnten.
Diese Kumulation von Anforderungen an die Testitems führte zu gewissen Problemen bei der Auswahl, sodass in einigen Fällen existierende Wörter leicht modifiziert wurden, um die Abweichungen von den deutschen Kognaten zu verringern, und die Liste außerdem um einige gemäß existierenden Lautentsprechungsregeln konstruierte Wörter ergänzt wurde. Am Ende stand eine Liste von 38 Testitems (s. Anhang). Die Vielzahl zu berücksichtigender Aspekte allein auf phonologischer Seite führt dabei dazu, dass die Zahl miteinander vergleichbarer Items jeweils noch zu klein ist und die Unsicherheit bleibt, ob sich nicht bei den untersuchten Einzelbeispielen noch andere Faktoren entscheidend auswirken (vgl. a. Möller/Zeevaert 2010). Insofern erlauben die hier vorgestellten Ergebnisse nur erste Einblicke und müssen weiter verfolgt und überprüft werden.
In einem ersten Test wurde 75 Studierenden der Universitäten Bonn und Münster die Liste von Testitems – in unterschiedlicher Reihenfolge – vorgelegt13, mit der Angabe, dass es sich durchgehend um Substantive handele, die aus verschiedenen germanischen Sprachen stammen (sodass eine Suche nach einer Systematik bzw. nach spezifischen Lautentsprechungsregeln erfolglos bleiben müsse). Die Antwort war frei zu geben – zu einem zweiten Test mit Multiple-Choice-Design s. u. –, die Aufforderung war, möglichst spontan zu antworten, jedenfalls pro Item nicht länger als ca. 30 Sekunden zu überlegen. Die Vorgabe der Wortart Substantiv erscheint insofern nicht ganz unrealistisch, als Merkmale wie Wortlänge, -stellung und Vorangehen hochfrequenter Artikelwörter auch beim echten Texterschließen gerade im Fall von Substantiven oft ein Erschließen der Wortart ermöglichen.
Bei den Probanden handelt es sich um Studierende der Germanistik; alle hatten zum Zeitpunkt des Tests im Rahmen von linguistischen Einführungsveranstaltungen schon phonetisch-phonologische Grundkenntnisse erworben und ebenfalls gewisse Kenntnisse über die deutsche Lautgeschichte (v. a. neuhochdeutsche Diphthongierung14, evtl. auch 2. Lautverschiebung). Es handelt sich insofern nicht um reine Laien; die Erfahrung zeigt allerdings nachdrücklich, dass der erfolgreiche Besuch solcher Kurse keineswegs bedeutet, dass das entsprechende Wissen abrufbar vorhanden wäre und bliebe (vgl. z. B. Berthele 2008: 104; Wenzel 2007: 199f.; Möller/Zeevaert 2010: 231–233)15. Gleichwohl mögen durchaus Reste solchen Wissens unterbewusst die Intuitionen beeinflussen. Wieweit dies der Fall ist, müssen weitere Untersuchungen mit anderen Personengruppen zeigen. Es wurde allerdings darauf geachtet, dass die Lautentsprechungen zwischen den Testitems und den richtigen Lösungen vielfältig sind und erheblich über die Folgen der 2. Lautverschiebung und nhd. Diphthongierung hinausgehen.
Vorab erfragt wurden passive Kenntnisse anderer germanischer Sprachen und deutscher Dialekte (gefragt wurde nach "(einigermaßen) verstehen bzw. lesen" können). Außer Englisch wurden hier von einigen Teilnehmern Niederländisch und Niederdeutsch und in Einzelfällen auch skandinavische Sprachen angegeben, aber im Vergleich der Ergebnisse erschien es nicht nötig, diese Teilnehmer aus der Auswertung auszuschließen16.
Für die 28 "echten" (oder nur leicht modifizierten) Kognaten17 sieht die gemittelte Erfolgsquote folgendermaßen aus: Bei 26% der Antworten wurden die richtigen deutschen Kognaten angegeben (etwa eek ⇒ Eiche, lof ⇒ Lob), bei 18% immerhin deutsche Wörter, die nach geläufigen Lautkorrespondenzen – ohne Beachtung lautkombinatorischer Details – deutsche Kognaten des Testitems sein könnten (Ecke, Lauf18). Immerhin 44% der spontan gefundenen Lösungen könnte man also im oben beschriebenen Sinn einer am Vorgehen, nicht an der tatsächlichen Richtigkeit des Ergebnisses orientierten Interkomprehensiondidaktik als "erfolgreich" verbuchen. Dazu kommen noch 12% Antworten, bei denen die Annahme eines Kognatenverhältnisses von den entsprechenden Lautkorrespondenzen (bzw. deren Geläufigkeit bei germanischen Kognatenverhältnissen) her weniger wahrscheinlich, aber nicht ganz abwegig wäre (Auge, Luft19), wenngleich in diesen Fällen wahrscheinlichere Lösungsmöglichkeiten nicht gefunden wurden. Nur 13% der vorgeschlagenen Lösungen sind dagegen wirklich sehr unwahrscheinlich (eek ⇒ Tee, lof ⇒ Hof). Allerdings wird die positive Bilanz dadurch relativiert, dass in knapp einem Drittel der Fälle (31%) gar keine Lösung gefunden wurde.
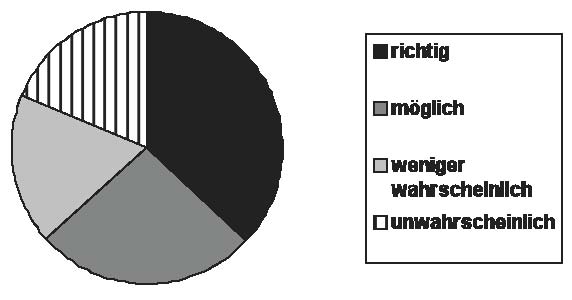
Abb. 2: Angenommene deutsche Kognaten insgesamt
(Test 1, freie Antworten) 75 Probanden, 28 existierende Substantive aus germanischen Sprachen
Nimmt man die fehlenden Lösungen aus der Rechnung aus (bei 13 von 28 Items ist "keine Lösung" insgesamt am häufigsten), verteilen sich die pro Item am häufigsten genannten Lösungen wie folgt auf diese Kategorien: 37% richtige, 26% mögliche, 18% weniger wahrscheinliche, 19% unwahrscheinliche.

Abb. 3: Jeweils am häufigsten genannte Lösung (abgesehen von "keine Lösung")
(Test 1, freie Antworten) 75 Probanden, 28 existierende Substantive aus germanischen Sprachen
Richtige bzw. sinnvolle Vermutungen überwiegen also bei weitem gegenüber den falschen bzw. abwegigen. Diese Ergebnisse sprechen dafür, dass Ähnlichkeits-Intuitionen existieren, die oftmals schon ausreichen, um auch ohne Kontext eine Erkennung kognater Wörter zu ermöglichen.
Versucht man, diese Intuitionen anhand der angegebenen Lösungen genauer zu erfassen, zeigt sich Folgendes: Zunächst einmal bestätigt sich die Annahme, dass in erster Linie Lösungen gesucht werden, die sich nur in wenigen (nicht-identischen oder hinzukommenden/fehlenden) Segmenten vom Testitem unterscheiden. Die mittlere ungewichtete Levenshtein-Distanz20 zwischen Item und Antwort beträgt 1,46. Dies liegt allerdings noch leicht über der mittleren Distanz der richtigen (bzw. bei den erfundenen Items: wahrscheinlichsten) Lösungen (1,34), was mehrere Gründe zu haben scheint. Z. T. wurde an diese Lösungen wohl einfach nicht gedacht, z. T. wird jedoch auch deutlich, dass die einfache Zählung abweichender Segmente nicht den Grad des "Naheliegens" einer Lösung für die Probanden erfasst: So entfallen bei dem Item bech 22% der Antworten auf die Lösung Becher, gegenüber 2–4% für Buch, Bett oder Blech (aber 42% für Bach), bei baune sind es 19% für Baum gegenüber 2% für Laune, und bei kand 42% für Kante21 gegenüber 9% für Kind. Vor allem das Anhängen mehrerer Segmente ist nicht selten anzutreffen, insbesondere dann, wenn es sich um Affixe oder "morphologische Reste" handelt.
Insgesamt scheinen die Probanden allerdings eher damit zu rechnen, dass Kognaten die gleiche Anzahl von Segmenten haben und sich einzelne dieser Segmente voneinander unterscheiden, als damit, dass Segmente wegfallen oder hinzukommen. So wurde im freien Test bei den 19 Items, bei denen sowohl Substitution als auch Deletion oder Insertion eines Segments ein deutsches Substantiv ergibt, im Mittel zu 62% Substitution vorgezogen. Bei genauerem Hinsehen erweist sich diese Rechnung jedoch als zu pauschal: Entscheidend ist offenbar, welche Segmente substituiert oder eingefügt bzw. getilgt werden (und wo). So wird die Hinzufügung oder Tilgung von Schwa am Wortende meistens den möglichen Substitutionen vorgezogen (vgl. u.), auch Lösungen, die eine Assimilation von d an vorangehendes n annehmen (s. u.), wurden häufig gewählt, während andere mögliche Hinzufügungen und Tilgungen meistens – wenn auch nicht immer – zugunsten von Substitution vernachlässigt werden. Ohne die beiden Ausnahmen Schwa und nd-Assimilation ergibt sich ein Mittelwert von 77% Substitution (12 Items mit entsprechenden Alternativen).
Bei den Substitutionen ist grundsätzlich eine Bevorzugung vokalischer Substitutionen zu erwarten, da aufgrund der allgemein größeren Variabilität von Vokalen (vgl. Gooskens/Heeringa/Beijering 2008: 64, Ashby/Maidment 2005: 80–82 – vgl. z. B. auch die Existenz von Spielliedern mit Austausch der Vokale als Variationsprinzip22) sowie auch der Rolle vokalischer Alternationen in der deutschen Sprache hier eine größere Toleranz gegenüber Unterschieden anzunehmen ist. Die Ergebnisse sprechen jedoch zunächst nicht dafür, jedenfalls nicht ohne Berücksichtigung anderer Faktoren: Bei den 13 Items, bei denen alternativ Lösungsmöglichkeiten mit einer konsonantischen oder einer vokalischen Substitution existieren, wurden im freien Test im Mittel nur zu 53% die Lösungen mit vokalischer Substitution angegeben. Differenziert man wieder genauer zwischen verschiedenen Substitutionen und vergleicht die Toleranz gegenüber ungewöhnlichen Korrespondenzen im vokalischen und im konsonantischen Bereich, ergibt sich allerdings ein anderes Bild (s. u.).
Schließlich ist auch damit zu rechnen, dass die Position des ggf. zu substituierenden Segments im Wort eine Rolle spielt, insbesondere damit, dass dem Wortanfang, insbesondere dem Anlaut, größeres Gewicht zugemessen wird (vgl. Lutjeharms 1997: 156f.; 2006: 209f.). Die Prominenz des Anlauts könnte sich allerdings in verschiedenen Richtungen auswirken: Einerseits in einer Bevorzugung von Lösungen, bei denen der Anlaut unverändert bleibt, andererseits in einer Neigung, bei der Kognatensuche besonders Variation des Anlauts auszuprobieren. Ein Vergleich der Ergebnisse nur für die acht Items, bei denen sowohl im Anlaut als auch nach dem Tonvokal eine konsonantische Substitution möglich wäre, ergibt eher eine Präferenz für Invarianz des Anlauts (67%). Auch hier ist – wie bei Vokal vs. Konsonant oder Substitution vs. Einfügung/Tilgung – jedoch zu berücksichtigen, dass unterschiedliche konsonantische Substitutionen offenbar sehr unterschiedlich beurteilt werden. Eine separate Auswertung des Faktors Position ist mit dem vorliegenden Material insofern nicht möglich, da nur gleiche Substitutionen in unterschiedlicher Position wirklich miteinander verglichen werden können. Dass umgekehrt unterschiedliche Lautkorrespondenzen auch bei gleicher Position als unterschiedlich wahrscheinlich eingestuft werden, ist dagegen unzweifelhaft (vgl. a. u. zum Multiple-Choice-Test). Im Folgenden geht es daher um die Frage, welche Korrespondenzen die Probanden gegenüber anderen präferieren.
Bei den einhelligsten Antworten (mehr als 40% Übereinstimmung) liegen (ohne klare Rangfolge) folgende Modifikationen zugrunde:
| a) | Anfügung eines auslautenden Schwa (nier ⇒ Niere). Dies liegt vor dem Hintergrund der umgangssprachlich (und dialektal) im Deutschen weit verbreiteten e-Apokope (heute > heut) nahe. |
| b) | verschiedene vokalische Substitutionen, bei denen sich ebenfalls eine Erklärung aus im Deutschen vorkommenden Varianten/Alternanzen finden lässt. Dies gilt jedenfalls für die Substitution von e durch a (bech ⇒ Bach) und umgekehrt, die phonologisch dem Verhältnis von Plural- und Singular-Stamm bei vielen deutschen Substantiven entspricht. Weniger evident, aber eventuell auch noch auf Erscheinungen im Deutschen zu beziehen sind die anderen häufig vorgenommenen vokalischen Substitutionen: o ⇒ u (hommel ⇒ Hummel) könnte mit Hinweis auf regionale Varianten erklärt werden, e ⇒ i (wend – Wind) ebenfalls23 – oder beides wie u ⇒ i (lucht – Licht) und u ⇒ a (urm – Arm) mit bestimmten Alternanzmustern, die auf germanischen Umlaut oder auf Ablaut zurückgehen (wurden – geworden, helfen – hilft, sinken – senken; finden – gefunden, bricht – Bruch; tragen – trug). Selbst die Korrespondenz a–ö (etwas seltener vorgeschlagen) findet sich im Deutschen als Alternanz etwa bei mag–mögen. |
Zu bemerken ist allerdings, dass die selteneren und artikulatorisch distanteren Beziehungen u ⇒ i, u ⇒ a und a ⇒ ö nur bei solchen Items angenommen wurden, bei denen die alternativ möglichen konsonantischen Substitutionen ebenfalls wenig wahrscheinlich sind (obwohl diese Korrespondenzen – f ⇒ ch und v ⇒ g – hier tatsächlich richtig sind, es handelt sich dabei um Ausnahme-Erscheinungen, vgl. u. 5). Es wird aber deutlich, dass unter diesen Bedingungen dann eher eine wenig geläufige vokalische Entsprechung angenommen wird als eine ungewöhnliche konsonantische (lucht: Licht 73%, Luft 4%; maven: Möwe(n) 24%, Magen 9%). Die Annahme einer allgemein größeren Toleranz gegenüber vokalischen Unterschieden bzw. einer stärkeren Fixierung auf die Konsonanten bestätigt sich insofern dann doch, sei es, dass dies einer universalen Gewichtung entspricht, oder sei es, dass die vokalischen Alternanzen in der Morphologie des Deutschen dahinter stehen, oder beides.
| c) | Substitution von s vor n oder l durch sch (slugt ⇒ Schlucht). Die Tatsache, dass s vor Konsonanten in indigenen deutschen Wörtern systematisch zu /ʃ/geworden ist, spielt hier in verschiedener Hinsicht eine Rolle: Zum einen ergibt sich daraus eine phonotaktische Beschränkung im Deutschen. So ist auch eine entsprechende Substitution bei Lehnwörtern anzutreffen24. Zum anderen sehen bei den graphisch erhaltenen Kombinationen <sp> und <st> auch die Graphem-Phonem-Korrespondenz-Regeln des Deutschen die Aussprache /ʃ/ für <s> vor. |
| d) | Substitution von auslautendem <g> bzw. <d> durch <(c)k> bzw. <t>. Hierbei wirkt wahrscheinlich die Auslautverhärtung mit, infolge derer die entsprechenden Segmente in den Testitems bei deutscher Aussprache schon stimmlos sind. (Eine Anfügung von Schwa – die die Auslautverhärtung verhindert – steht dieser Substitution jedoch nicht entgegen, vgl. kand – Kante). Auch von der großräumig verbreiteten Lenisierung von p t k in deutschen Dialekten und Regiolekten her könnte diese Korrespondenz geläufig sein. Die Substitution von anlautendem und intervokalischem d durch t tritt allerdings erst deutlich später in der Rangliste auf, ebenso wie die von anlautendem t durch d. |
Weniger Einhelligkeit als bei den bisher aufgelisteteten Korrespondenzen, aber immer noch über 20% Übereinstimmung in den Antworten, ist hinsichtlich folgender weiterer Modifikationen zu beobachten:
| e) | Tilgung von d nach n (spinde ⇒ Spinne) und Einfügung von d nach n. Ersteres entspricht einer in im nieder- und mitteldeutschen Raum weit verbreiteten und geläufigen Assimilation (Kinner(s)) (vgl. Guentherodt 1983: 1142), letzteres umgekehrt der Annahme, in dem fremden Wort liege eine solche Assimilation vor. In die Kategorie "Assimilation" lässt sich auch die Substitution von auslautendem ss durch tz (plass ⇒ Platz) einordnen, die ebenfalls häufig vorgenommen wurde, allerdings aus deutschen Varietäten weniger vertraut ist. |
| f) | Substitutionen von ei und au für e(e) und o(o), z. B. ben ⇒ Bein oder soom ⇒ Saum. Auch diese Korrespondenzen sind wiederum vor dem Hintergrund geläufiger regionaler Formen mit Monophthongierung (vgl. etwa berlinisch detweeß ick ooch nich) als vertraut einzustufen. |
| g) | Substitution von g vor Konsonant durch ch (slugt ⇒ Schlucht). Die frikative Aussprache von g im Silbenauslaut und vor Konsonant (Zuch 'Zug', fracht 'fragt') ist in weiten Teilen Deutschlands noch sehr gebräuchlich25, die Substitution gibt hier also einfach eine verbreitete Aussprachevariante wieder. |
| h) | Substitutionen entsprechend der 2. Lautverschiebung: postvokalisches k ⇒ ch, t ⇒ ss, (zu d‑t s. o.), anlautendes t ⇒ z (sikt ⇒ Sicht, slut ⇒ Schluss, telt ⇒ Zelt26) |
| i) | Anfügung von Segmenten und Silben am Wortende: Hier handelt es sich offenbar um die Annahme morphologisch begründeter Unterschiede (bech ⇒ Becher, vgl. etwa Wurz – Wurzel, Weck – Wecken, Beck – Bäcker, Kassier – Kassierer). |
Insgesamt lässt sich konstatieren, dass die Lösungen mit vergleichsweise hoher Übereinstimmung sich fast durchgehend dadurch auszeichnen, dass sie auf der Annahme von Lautkorrespondenzen und Tilgungs- bzw. Assimilationserscheinungen basieren, die im Deutschen im Rahmen von regionaler (bzw. soziosituativer) Variation oder auch morphologischer Alternanz vorkommen. Eine mögliche Erklärung für die Entscheidungen der Probanden wäre also, dass sie mit diesen Korrespondenzen – weniger im Sinne von "Regeln" als im Sinne einer bewussten oder unbewussten Wahrnehmung eines wiederkehrenden Musters bei alternierenden Formen27 – vertraut sind. Es gibt allerdings auch noch eine andere mögliche Erklärung: Die Intuitionen könnten sich auch unmittelbar auf phonetische/artikulatorische Ähnlichkeit (mehr dazu s. u.) bzw. auf die Natürlichkeit bestimmter Prozesse wie Assimilation, Tilgung von Schwa etc. beziehen. Beides hängt natürlich insofern zusammen, als die von großräumig verbreiteten regionalen Varianten her (oder auch aus nachlässiger Artikulation) bekannten Erscheinungen weitgehend auch solche sind, die phonetisch/artikulatorisch nahe liegen. Umgekehrt sind die sonstigen Korrespondenzen, die sich aus anderen theoretisch möglichen Substitutionen eines Segments ergeben würden, sowohl artikulatorisch weniger ähnlich als auch nicht als Variations- oder Alternanzerscheinung vertraut. In jedem Fall werden solche Substitutionen deutlich seltener angesetzt (etwa l ⇒ h bei lof: 4%, k ⇒ r bei kand: 4%, ch ⇒ t(t) bei bech: 2%, d ⇒ (c)k bei dadel 2%, m ⇒ w bei mand 2%, s ⇒ b oder s ⇒ g bei slut 1% usw.). Das gilt ebenso im Bereich der Einfügungen und Tilgungen: Anders als die unter e) erwähnten Einfügungen und Tilgungen (= Assimilationen) werden weniger "natürliche" Operationen wie etwa die Einfügung von l in bech ⇒ Blech (4%) oder die Tilgung vor r vor dem Tonvokal in struk ⇒ Stuck (1%) kaum vorgeschlagen.
Die Intuitionen der Probanden scheinen insofern prinzipiell sehr brauchbar zu sein (und einer rein quantitativen Orientierung an Zahl oder Anteil unterschiedlicher Segmente – wie ihn die ungewichtete Levenshtein-Distanz erfasst – weit überlegen). Allerdings lassen die vorliegenden Ergebnisse nicht den umgekehrten Schluss zu, dass diese "naheliegenden" Korrespondenzen unter allen Umständen zu Durchsichtigkeit der Kognatenbeziehung führen: Nicht alle Lösungen, die sich aus entsprechenden Korrespondenzen ergeben würden, wurden von vielen Probanden gefunden. Zum Teil erklärt sich das einfach mit einer Konkurrenz zwischen mehreren naheliegenden Lösungsmöglichkeiten (z. B. wend: e ⇒ i oder e ⇒a oder Anfügung von Schwa) und ist insofern zu vernachlässigen, häufiger aber dürfte der Grund die Kumulation mehrerer – für sich genommen jeweils naheliegender – Korrespondenzen (z. B. deeg – Teig) sein. In welcher Weise sich die Kumulation von Unterschieden verglichen mit Abweichungen einzelner Segmente auf die Erkennung auswirkt (vgl. a. Gooskens/Heeringa/ Beijering 2008: 78), müsste also – insbesondere für realistische Ähnlichkeitsmessungen – noch weiter geklärt werden.
Um zunächst einmal nur die Beurteilung lautlicher Ähnlichkeit weiter untersuchen zu können, unter Ausschaltung des Problems der "fehlenden Idee", und sie mit dem freie Finden von Kognaten vergleichen zu können, wurde mit denselben Items und einer vergleichbaren Gruppe von Probanden (84 andere Germanistik-Studierende der Universitäten Bonn und Münster, Vorkenntnisse ebenso wie im ersten Test) ein Multiple-Choice-Test durchgeführt. Als Antwort-Optionen wurden die von Anfang an erwarteten Lösungsmöglichkeiten sowie weitere, im freien Test als Lösungen genannte deutsche Wörter angegeben, und zwar in zwei Versionen mit z. T. unterschiedlicher Auswahl von Optionen28. Zusätzlich wurde immer die Option "anders (_________)" angeboten: "Wenn keines der vorgeschlagenen Wörter passt, kreuzen Sie 'anders' an und fügen Sie eine bessere Lösung ein, wenn Ihnen eine einfällt.".
Der Anteil der richtigen Lösungen liegt in diesem Material um 50%, der Anteil der richtigen plus möglichen bei ca. 70–80%, wobei berücksichtigt werden muss, dass nicht in beiden Versionen in jedem Fall alle Lösungstypen unter den vorgegebenen Optionen waren. Trotz der immer vorhandenen Option "anders" suchten die Probanden sich in der Regel eine der vorgegebenen Möglichkeiten aus – ggf. auch unter Inkaufnahme von Lautkorrespondenzen, die bei den sonstigen Entscheidungen gemieden werden. Dies zeigt sich besonders deutlich bei den 6 Items, bei denen die richtige Lösung in der Testversion A weggelassen wurde.
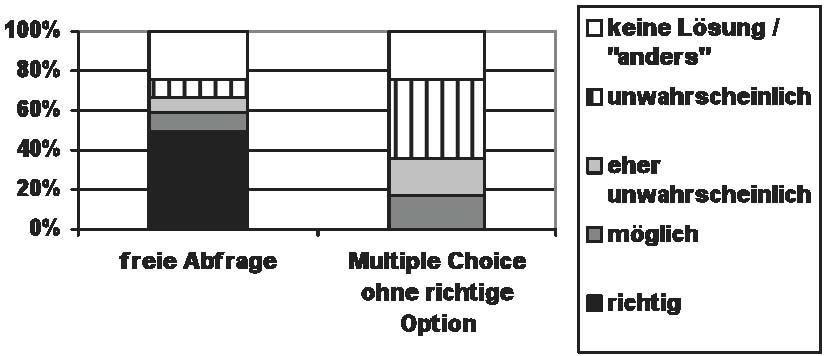
Abb. 4: 6 Items, bei denen im Multiple-Choice-Test (Version A) die richtige Lösung fehlt
Es handelt sich hier weitgehend um Items, die im freien Test vergleichsweise gut erkannt wurden, bei denen also eigentlich spontan die richtige Lösung gefunden werden konnte. Im Multiple-Choice-Test wurde bei diesen Items zwar häufiger "anders" angekreuzt als bei den anderen, aber die Mehrheit der Probanden entscheidet sich nicht für "anders", sondern für eine (phonetisch und von den existierenden Korrespondenzen her) unwahrscheinliche Lösung. Beim Item nafel (in freier Abfrage schlechter erkannt: 43% keine Lösung, 19% Nabel, 15% Tafel, 14% Nadel, 3% Nagel) ist der Unterschied zwischen den beiden Versionen im Multiple-Choice-Test ganz auffällig:
| Version B | 58% Nabel | 7% Nadel | 19% Nagel | 7% Tafel | 9% anders |
| Version A | 47% Nadel | 44% Nagel | 5% Tafel | 9% anders |
Eventuell ist diese Erscheinung allein mit der Situation des Multiple-Choice-Tests zu erklären und für die reale Worterkennung irrelevant. Möglicherweise ist diese Situation jedoch auch ansatzweise mit der realen Lesesituation zu vergleichen: Beobachtungen aus Übungen und Tests zur Interkomprehension weisen darauf hin, dass die Wahrscheinlichkeit eines Kognatenverhältnisses weniger kritisch beurteilt wird, wenn die Suche dadurch eingeschränkt wird, dass der semantische Kontext eine bestimmte Lösung nahezulegen scheint (vgl. Zeevaert/Möller i. Dr.).
Wie in der freien Abfrage erweisen sich die Faktoren "Art der Differenz" (Substitution, Tilgung, Einfügung), "konsonantische vs. vokalische Substitution" und "Position des Unterschieds" auch im Multiple-Choice-Test nicht als klar ausschlaggebend. Die sich ergebenden Tendenzen sind dieselben29. Noch besser als in der freien Abfrage wird indessen sichtbar, dass die Beurteilung von Substitutionsoperationen stark von der konkreten Konstellation der korrespondierenden Segmente abhängt. So ergeben sich z. T. massive Unterschiede zwischen alternativen Optionen mit konsonantischen (oder auch vokalischen) Substitutionen in gleicher Position, vgl. die klare Bevorzugung der Substitution f–b gegenüber f–d und f–g bei dem schon erwähnten Item nafel (Testversion B) oder von d–ß gegenüber d–l bei spied (Spieß: 64% der Antworten, Spiel: 14%). Die Probanden halten also eindeutig – bei ansonsten gleichen Bedingungen – unterschiedliche Korrespondenzen für unterschiedlich wahrscheinlich; die Entscheidung kann sich dabei nur auf phonetische Aspekte oder auf Vertrautheit der Entsprechung stützen, denn auch graphische Anhaltspunkte scheiden bei diesen Beispielen aus (ein Vorteil von <b> gegenüber <d> bzw. von <ß> gegenüber <l> hinsichtlich des Wortumrisses ist jedenfalls nicht zu erkennen), und die Frequenz spräche hier wohl eher gegen die bevorzugten Lösungen.
Anders als in der freien Abfrage wird im Multiple-Choice-Test auch eine Rangfolge innerhalb der angenommenen vokalischen Entsprechungen sichtbar: Die Substitutionen e(e) ⇒ ei und oo ⇔ au sowie u ⇒ au und o ⇒ u rangieren hier um 25% bzw. 30% weiter oben im Konsensgrad als u ⇒ i und u ⇒ a. Zumindest die Tatsache, dass nicht nur oo ⇒ au als wahrscheinlich eingeschätzt wird, sondern auch au ⇒ oo30, spricht hier eher dafür, dass die artikulatorische Nähe ausschlaggebend ist und nicht die Bekanntheit, denn eine Korrespondenz au (andere Varietät) ⇒ o: (Standarddt.) ist den meisten Sprechern wohl kaum geläufig31. Bei den 4 Items mit alternativen Möglichkeiten vokalischer Substitutionen (bech: Bach oder Buch, hommel: hummel, hammel oder himmel etc.) werden jeweils klar die Lösungsmöglichkeiten präferiert, die nur einen Schritt im Vokaltrapez erfordern (im Mittel 76% der Antworten; ohne das Item mand, wo ein quantitativer Unterschied hinzukommt – Mond vs. Mund – sogar 88%32). Die deutliche Bevorzugung der Lösung Hummel gegenüber dem artikulatorisch gleich distanten Hammel beim Testwort hommel (65% vs. 20%) lässt sich allerdings so nicht erklären; sie spricht eher wieder dafür, dass es bestimmte vertraute Beziehungen sind, die für wahrscheinlich gehalten werden, und die Präferenz für artikulatorisch ähnliche Korrespondenzen sich indirekt hieraus ergibt – sofern speziell in diesem Fall nicht ganz andere Faktoren, nämlich semantische Bezüge zu weiter ähnlichen Wörtern (vgl. Möller/Zeevaert 2010), ausschlaggebend sind.
Im Bereich konsonantischer Substitutionen zeigt sich eine hohe Übereinstimmung hinsichtlich der Präferenz für eine (tatsächlich richtige bzw. theoretisch mögliche) Lösung im Multiple-Choice-Test auch bei Items, bei denen in freier Abfrage von zahlreichen Probanden gar keine Lösung gefunden wurde (z. B. struk ⇒ Strauch oder spied ⇒ Spieß). Bei 26 (Version A) bzw. 27 (Version B) Items von 38 waren sich über 50% der Probanden einig in der Auswahl einer bestimmten Lösung. Diese Lösungen zeichnen sich alle durch tatsächlich zwischen germanischen Sprachen vorkommende Lautkorrespondenzen aus, diese Korrespondenzen sind jedoch nicht mehr durchgängig auch aus Variation/Alternation innerhalb des Deutschen bekannt: Im Multiple-Choice-Test finden Lösungen mit konsonantischen Modifikationen wie k ⇒ ch oder d ⇒ t (2. Lautverschiebung), aber auch t ⇒ d und d ⇒ ss im Verhältnis größeren Konsens als im freien Test. Diese Ergebnisse weisen auch wieder eher darauf hin, dass die Entscheidung aufgrund phonetischer Ähnlichkeit getroffen wird (vgl. a. oben zu nafel und spied – im ersteren Fall könnte ggf. noch auf bekannte engl.-dt. Kognatenpaare verwiesen werden, bei d-ss jedoch auch das nicht).
Phonetische Ähnlichkeit zwischen Einzellauten wird in der Literatur normalerweise an gemeinsamen phonetischen Merkmalen bzw. Übereinstimmung hinsichtlich artikulatorischer Kategorien festgemacht (vgl. z. B. Heeringa 2004: 29–45). Welche Merkmale dabei welche Relevanz haben, ist bislang nicht wirklich klar und dürfte variieren – zum einen spielt die Phonologie der L1 mit Sicherheit eine Rolle für die Beurteilung der Ähnlichkeit zwischen zwei Lauten (vgl. etwa Flege 1995: 238), zum anderen muss "Ähnlichkeit" unter artikulatorischem, akustischem und perzeptivem Aspekt nicht dasselbe sein (vgl. a. Heeringa 2004: 184–193, 281). Für die vorliegende Aufgabenstellung ist in jedem Fall der artikulatorische Aspekt primär, weil ja die Phonologisierung von Buchstabenfolgen durch den Leser die Grundlage ist und nicht gehörte Sprache.
Als gemeinsames Charakteristikum fast aller konsonantischen Modifikationen bei den Lösungen mit "absoluter Mehrheit" im Multiple-Choice-Test kann man Konstanz des Artikulationsorts und der Sonoranz festhalten (f ⇒ b; t ⇒ z; t ⇒ ss; t ⇒ d; d ⇒ t; d ⇒ s; ss ⇒ tz; k ⇒ ch; g ⇒ ch; g ⇒ ck). Die zahlreichen Lösungsmöglichkeiten, die ebenfalls nur in einem Segment vom Testitem abweichen, jedoch Substitutionen wie f ⇒ g, k ⇒ r, sch ⇒ k, p ⇒ g, h ⇒ b, b ⇒ g usw. (mit Wechsel des Artikulationsorts) oder auch n ⇒ t (Beibehaltung des Artikulationsorts unter Änderung der Sonoranz) voraussetzen, wurden dagegen von der – zumeist großen – Mehrheit der Probanden nicht für mögliche Kognaten gehalten. Beschränkt man die Betrachtung gezielt auf die Items, bei denen alternativ konsonantische Substitutionen mit gleichem und mit unterschiedlichem Artikulationsort existierende deutsche Wörter ergeben, und vergleicht die Anteile der jeweiligen Lösungen miteinander, bestätigt sich eine klare Präferenz für die Substitutionen mit gleichem Artikulationsort (8 Items, 81% der gewählten Lösungen sind diejenigen mit gleichem Artikulationsort). Auch in der freien Abfrage zeigt sich dies schon (933 Items, 72% gleicher Artikulationsort); der Unterschied zwischen den Zahlen für die beiden Tests reflektiert die Tatsache, dass bestimmte Korrespondenzen (insbesondere die Fälle, die auf die Frikativierung stimmloser Plosive in der 2. Lautverschiebung zurückgehen) im Multiple-Choice-Test besser erkannt werden als in der freien Abfrage – diese Korrespondenzen scheinen zwar "einzuleuchten", aber spontan weniger "suggestiv" zu sein (vgl. a. 6.).
In Distanzmessungen mit Gewichtung nach phonetischer Ähnlichkeit substituierter Segmente wird Übereinstimmung in Artikulationsort oder -art in der Regel gleich gewichtet (vgl. Herrgen et al. 2001: 4f., Heggarty/McMahon/McMahon 2005: 52f. oder – mit jeweils stärkerer Ausdifferenzierung – Heeringa 2004: 29–45). In den Intuitionen der Probanden scheint beides jedoch von sehr unterschiedlicher Bedeutung zu sein.34 Bei den 5 Items, bei denen alternativ konsonantische Substitutionen mit gleicher und mit unterschiedlicher Artikulationsart existierende deutsche Wörter ergeben, sieht das Ergebnis zumindest deutlich anders aus als beim Artikulationsort: Hier werden im Vergleich nur zu 35% (freie Abfrage: 29%) die Lösungen mit gleicher Artikulationsart gegenüber anderen konsonantischen Substitutionen präferiert. Bei slut besteht beim gleichen Item die Alternative; die Lösung Schluss (Artikulationsort gleich, -art verschieden) liegt dabei für die Probanden offensichtlich deutlich näher als die Lösungen Schluck oder Flut (Artikulationsart gleich, -ort verschieden): Im Multiple-Choice-Test entfallen hier 52% aller gegebenen Antworten auf Schluss, gegenüber 24% Schluck und 11% Flut, in der freien Abfrage sind es 24% (sowie 13% Schloss) gegenüber 0% bzw. 6%. Meistens führt diese Präferenz für Konstanz des Artikulationsorts bei Konsonanten – wie hier – zu richtigen bzw. möglichen Lösungen, im Fall des nl. Worts lucht erklärt sie dagegen das schlechte Ergebnis für die richtige Lösung Luft (Multiple Choice: 23%, freie Abfrage 4%).
Tatsächlich ist die Korrespondenz nl.-dt. ch–f (vor t)35 gegenüber den anderen Korrespondenzen eine Ausnahme, die auch nicht viele Wörter betrifft (vgl. Möller 2007: 289). Nach Hock/Joseph (1996: 133f.) erklärt sie sich mit der auditiven Verwechselbarkeit, also auf dem Weg über die Rezeption – was gegenüber artikulatorisch begründetem Lautwandel, vor allem Lenisierungen der Artikulationsart bei (fast oder ganz) konstantem Artikulationsort – ein eher seltener Fall zu sein scheint (vgl. etwa die bei Back 1991 dargestellten Lautwandeltypen). In der Regel sind die Ähnlichkeits-Intuitionen der Probanden, die in diesem Fall kontraproduktiv sind, für die germanische Interkomprehension durchaus zutreffend: Die germanischen Lautkorrespondenzen, die in der Orthographie greifbar werden (vgl. Lutjeharms/Möller 2007), betreffen bei den Konsonanten weitestgehend Obstruenten und zeichnen sich mit wenigen Ausnahmen durch (Fast-)Übereinstimmung des Artikulationsorts aus. Dies gilt vor allem für alle Korrespondenzen, die auf die 2. Lautverschiebung zurückgehen (inklusive der weiteren Unterschiede infolge von Gemination oder infolge der dänischen Klusilschwächung), auch für die Korrespondenzen zwischen Plosiven und Frikativen bei germ. *ƀ *đ *g̲ und schließlich auch für die teils graphischen, teils auch Phonations-Unterschiede im Bereich der bilabialen/labiodentalen Frikative (<w>, <v>, <f>) sowie für diverse andere kombinatorische Entwicklungen und Einzelfälle.
Nur die Palatalisierung von germ. *k im Englischen und Friesischen fällt hier aus dem Rahmen – wobei beide Sprachen aus verschiedenen Gründen für die germanische Interkomprehension weniger relevant sind –, außerdem die gelegentlich anzutreffenden Korrespondenzen zwischen g und v/w/u (germ. *magōn > dän. mave / dt. Magen,germ. *breww-a- > dän. brygge / dt. brauen)und eben die Entwicklung von ft zu cht im Niederländischen, wobei diese alle qualitativ nur eine geringe Rolle spielen, und schließlich die ebenfalls nicht häufigen Metathesen (nl. borst – dt. Brust) und Vokalisierungen (nl. oud – dt. alt).
Im Bereich von "Tilgungen" und "Einfügung" sind bei germanischen Kognaten vor allem Assimilationen relevant, die für die Probanden offenbar auch besonders naheliegen, zumindest im häufigen Fall von d bzw. t nach n. Intuitiv relativ unzugänglich sind auch im Fall von "Tilgung"/"Einfügung" anscheinend nur wenige und nicht sehr frequente Erscheinungen wie der Wegfall von anlautendem j und w in bestimmten Wörtern der skandinavischen Sprachen (vgl. schwed. ung – dt. jung); das Auftreten von j infolge der Brechung in skandinavischen Sprachen ist dagegen nach den Testergebnissen nur dann ein Problem, wenn es im Anlaut steht (vgl. schwed. jord – dt. Erde), andernfalls führt die Verletzung von phonotaktischen Regeln des Deutschen (etwa schwed. hjälm – dt. Helm) offenbar automatisch zur Tilgung36. Bei den Vokalen decken sich die Präferenzen der Probanden ebenfalls mit qualitativ dominierenden Korrespondenzen: Es geht dabei um die Folgen von Hebungen und Senkungen um eine Stufe im Vokaltrapez bzw. Monophthongierungen und Diphthongierungen, bei denen der Monophthong Teil des Diphthongs ist oder artikulatorisch eine Zwischenposition zwischen dessen erstem und zweitem Teil einnimmt.
Die angetroffenen Präferenzen in der spontanen Erkennung bzw. Beurteilung von Kognatenbeziehungen sind also, bezogen auf die tatsächlich existierenden Lautentsprechungen zwischen germanischen Kognaten, im Prinzip sehr zutreffend bzw. hilfreich. Da nach den Ergebnissen (wie auch nach Kommentaren von vergleichbaren Probanden, vgl. Möller/Zeevaert 2010) konkrete Kenntnis germanischer Kognatenbeziehungen keine Rolle zu spielen scheint, gibt es zwei mögliche Erklärungen hierfür: Entweder steht hinter diesen Intuitionen vor allem die Bekanntheit von bestimmten Varianz- und Alternanzmustern in der L1 und deren Varietäten (bei der getesteten Personengruppe außerdem eventuell mehr oder weniger unterbewusst bewahrtes Studienwissen, vgl. o.). Dies kann teilweise auch über Stereotype und ähnliches Wissen vermittelt sein; so gibt es z. B. nach Primus (2002) auch eine spezifische Tradition hinsichtlich der Duldung bestimmter "unreiner" Reime, die von der weiten Verbreitung gewisser regionaler Merkmale und deren Vorhandensein im Gebrauch tonangebender Gesellschaftsgruppen und angesehener Dichter herrührt. Oder es existiert schon von der aktiven und passiven Sprechpraxis her ein Bewusstsein für phonetische Ähnlichkeit bzw. artikulatorisch naheliegende Variationsmöglichkeiten, die sich ständig im Sprechen finden (vgl. z. B. die bei Krech et al. 2009: 103–109 angeführten Lenisierungserscheinungen), aber eben auch in Lautwandel niederschlagen können. Diese Frage bleibt genauer zu untersuchen – interessant sind jedenfalls Unterschiede zwischen den Ergebnissen in der freien Abfrage und im Multiple-Choice-Test, die in die Richtung deuten, dass für die spontane Aktivierung der richtigen Kognaten die Vertrautheit der Lautkorrespondenzen wichtiger ist als für die "passive" Beurteilung von Substitutionen, für die der Eindruck phonetischer Ähnlichkeit ausschlaggebend ist. Dies zeigt sich insbesondere im Zusammenhang mit den Folgen der 2. Lautverschiebung, die für die Auswahl zwischen gegebenen Optionen ein geringeres Hemmnis darzustellen scheinen als für die spontane Erkennung.
In einer realen Lesesituation ist allerdings damit zu rechnen, dass es schon durch den Ko(n)text zu einer erhöhten Aktivierung von semantisch passenden Wörtern kommt und die Erkennung dadurch erleichtert wird. Das kann jedoch ggf. auch ein erhöhtes Risiko bedeuten: Die Leser sind zwar in der Lage, wahrscheinlichere von weniger wahrscheinlichen Korrespondenzen zu unterscheiden – sie akzeptieren jedoch auch weniger wahrscheinliche, wenn die Umstände dies nahelegen (vgl. Zeevaert/Möller i. Dr.). Das zeigt sich deutlich im Multiple-Choice-Test in den Fällen, in denen in einer von den zwei Testversionen die richtige Lösung ausgelassen wurde: Damit steigt die Akzeptanz der unwahrscheinlichen deutlich an, die "Wahrnehmungstoleranz" wird zu groß (vgl. Berthele 2008: 92). Dies wäre möglicherweise eine Stelle, an der mit Gewinn didaktisch angesetzt werden kann: Unter Bezugnahme auf die zumindest "passiv" offenbar vorhandenen Ähnlichkeitsintuitionen müsste es möglich sein, festzulegen und auch für Laien nachvollziehbar zu machen, wann genau die Toleranz zu groß wird (und zwar ohne Rückgriff auf "richtig" und "falsch", d. h. auf Kenntnisse der zu erschließenden Sprache).
Eine stärkere Berücksichtigung dieser phonetischen Intuitionen im Sinne eines Filters zur Plausibilitätsprüfung der spontanen Assoziationen dürfte einen der Punkte ausmachen, an denen der Erfolg bei der Kognatenerkennung in der Interkomprehension durch gezieltes Training verbessert werden könnte. (Dabei muss nicht unbedingt theoretisch mit phonetischen Kategorien umgegangen werden, sondern auch ein vorwiegend sensomotorischer Zugang ist durchaus möglich). Wie weit derartiges Training tatsächlich zur Verbesserung der Erschließungsleistungen führen kann, bleibt empirisch zu prüfen, das Vorhandensein richtiger Intuitionen spricht jedenfalls für eine gute Ausgangslage. Die wenigen existierenden Lautkorrespondenzen, die gegen diese Intuitionen "verstoßen", wären dann gesondert zu thematisieren. Darüber hinaus weisen die vorliegenden – noch durch weitere Untersuchungen zu bestätigenden – Ergebnisse allerdings darauf hin, dass der intuitive Sinn für phonetische Ähnlichkeit für ein spontanes Erkennen von Kognaten nicht unbedingt ausreicht, wenn die entsprechenden Lautkorrespondenzen nicht auch aus der eigenen sprachlichen Erfahrung als Korrespondenzen vertraut sind. Angesichts der quantitativen Bedeutung vor allem der Folgen der 2. Lautverschiebung könnte speziell hier also auch das besondere Trainieren einer "aktiven" Anwendung von Entsprechungsregeln sinnvoll sein. Der Umfang zu vermittelnder Spezialkenntnisse für die Kognatenerkennung in der germanischen Interkomprehension bliebe damit aber insgesamt relativ überschaubar.
1 Vgl. zur Definition z. B. Doyé (2006), Meißner (2004: 42ff.). Teilweise wird der Terminus Interkomprehension auch allgemein für rezeptive Mehrsprachigkeit innerhalb von Sprachfamilien (oder sogar darüber hinaus) verwendet; für eine präzisere Auseinandersetzung mit spezifischen Aspekten erscheint es jedoch sinnvoll, die Einschränkung auf das Leseverstehen beizubehalten. zurück
2 Die syntaktischen und morphologischen Entwicklungen sind zumeist durch eine größere Parallelität gekennzeichnet und selbst bei Divergenzen relativ leicht zugänglich, wenn sich die zu verstehende Sprache durch analytischere Strukturen bzw. morphologischen Abbau von der bekannten Sprache unterscheidet (wie es – außer beim Isländischen – in der Regel der Fall ist, wenn die bekannte Sprache das Deutsche ist). zurück
3 Vgl. Klein/Stegmann (2000), Hufeisen/Marx (eds.) (2007). zurück
4 Die Verteilung von eindeutigen und uneindeutigen Korrespondenzen wäre dabei noch näher zu untersuchen. Nach Moberg/Gooskens (2007) ist die unterschiedliche konditionelle Entropie bzw. die Asymmetrie hinsichtlich der Eindeutigkeit der Entsprechungen ein wichtiger Faktor für die Erklärung der Asymmetrie in der gegenseitigen Verstehbarkeit zwischen Dänisch und Schwedisch. Diese Untersuchung bezieht sich allerdings auf die gesprochene Sprache, bei der Reduktionserscheinungen eine erheblich größere Rolle spielen als bei der geschriebenen, und auf zwei Sprachen, deren Gemeinsamkeiten – verglichen mit dem Verhältnis zwischen Deutsch und anderen germanischen Sprachen – sehr groß sind. zurück
5 Time und tijd, small und små sind nicht kognat, nl. tegen geht auf te jeghen ("zu gegen") zurück (De Vries/De Tollenaere 1997: 727f.). Der mnemotechnische Effekt derartiger Verknüpfungen steht auf einem anderen Blatt, es erscheint jedoch sinnvoller, solche Verbindungen unter diesem Aspekt auf eine Ebene mit anderen "Eselsbrücken" zu stellen, als sie unter "gemeinsamer Wortschatz" zu verbuchen. zurück
6 Nach Beijering/Gooskens/Heeringa (2008) ist die relative Distanz (Summe der Abweichungen geteilt durch Anzahl der alignments – d. h. der Spalten in einer Darstellung wie Abb.1) vorzuziehen. Der Unterschied dürfte jedoch vor allem dann zum Tragen kommen, wenn Wörter mit deutlich unterschiedlicher Länge beteiligt sind (z. B. dann, wenn die mittlere Distanz für alle Wörter eines Textes ermittelt wird). zurück
7 Zum Glück, denn andernfalls wäre germanische Interkomprehension kaum möglich, jedenfalls nicht ohne Erwerb einer großen Zahl von Entsprechungsregeln. zurück
8 Dabei könnten z. B. auch verschiedene Methode des schulischen Leseunterrichts – segment- oder wortbezogen – eine Rolle spielen (Hinweis von Nicole Marx). zurück
9 Vgl. Möller (2007) zu einem derartigen Versuch, wobei die Gewichtung jedoch auf reinen Annahmen beruht (vgl. ebd: 291f.); vgl. zu verschiedenen gewichteten Levenshtein-Distanzen auch Heeringa (2004) sowie zu einem ählichen Verfahren zur Dialektalitätsmessung Herrgen et al. (2001). Welche Gewichtung vorzunehmen ist, ist auf jeden Fall abhängig von der konkreten Fragestellung, zum einen natürlich von der Frage, ob gesprochene oder geschriebene Sprache vorliegt, aber auch davon, ob es darum geht, die Wahrscheinlichkeit einer Kognatenbeziehung zu beurteilen, den Grad der Verwandtschaft zwischen zwei Dialekten zu ermitteln (wie bei Heeringa) oder den Grad der Abweichung einer Sprachprobe vom Standard (wofür z. B. auch Bewertungen von Merkmalen eine Rolle spielen). Das Verfahren zur Dialektalitätsmessung von Herrgen/Schmidt (s. Herrgen et al. 2001) ist als Ganzes verschiedenlich empirisch bestätigt worden (vgl. ebd.: 1); ob die rechnerische Gewichtung der einzelnen Operationen in allen Details realistisch ist oder nicht, kommt dabei jedoch nur eingeschränkt zum Tragen, da im Bereich der Dialekt-Standard-Variation nur ein beschränkter Teil der theoretisch möglichen Substitutionen und Kombinationen von Substitutionen tatsächlich vorkommt und die richtige Zuordnung von regionaler und Standardvariante bei dieser Fragestellung von vorn herein als gegeben vorausgesetzt wird. zurück
10 Vgl. a. Kürschner/Gooskens/van Bezooien (2008: 97) zu der Beobachtung, dass die Ähnlichkeit hierbei relevanter zu sein scheint als die reine Anzahl der Alternativmöglichkeiten bzw. "Nachbarn". zurück
11 Die Berechnung bezieht sich auf Phoneme, auf der Basis der deutschen Graphem-Phonem-Korrespondenzegeln. Quantitätsunterschiede bei Vokalen werden nur berücksichtigt, wenn sie nach diesen Regeln eindeutig sind, was oft nicht der Fall ist. Diphthonge und Affrikaten werden jeweils als ein Segment gerechnet. zurück
12 Wie die Untersuchung isolierter Wörter ist auch dies unrealistisch – der Rückgriff auf Englischkenntnisse spielt zweifellos eine große Rolle – aber für die Untersuchung der Ähnlichkeit-Intuitionen unerlässlich. Und letztere sind insofern relevanter, als phonetische Ähnlichkeit eine recht brauchbare Basis für die Kognatenerkennung zu sein scheint (s. u. 5), während der Rückgriff auf das Englische, zumal angesichts der heterogenen Zusammensetzung des englischen Wortschatzes, nur in Grenzen hilfreich sein kann. zurück
13 Mein herzlicher Dank gilt Nicole Marx und Tobias Vogelfänger, die die beiden Tests mit ihren Studierenden durchgeführt haben. zurück
14 Wegen einer von den meisten bereits besuchten Einführung in das Mittelhochdeutsche. zurück
15 Ein deutlicher Zusammenhang zwischen dem Besuch der in Bonn obligatorischen Einführungsveranstaltungen und dem Erkennungserfolg ist jedenfalls bei den 57 Bonner Teilnehmenden nicht zu beobachten. Die Erfolgsquote (richtige und mögliche Antworten, vgl. u.) für die 28 echten Kognaten liegt hier im Gesamtmittel bei 42,3%; im Einzelnen sieht sie (bei sehr ungleicher Verteilung der Teilnehmer auf die Untergruppen) folgendermaßen aus:
| Kurs | noch nicht besucht | gerade besucht | schon besucht |
| Einf. synchroneSprachwissenschaft | – | 40,7% | 43,9% |
| Einf. Mittelhochdeutsch | 48,2% | 38,4% | 40,75% |
| Einf. diachrone Sprachwissenschaft | 41,1% | 42,9% | 37,5% |
16 Erwartungsgemäß hatten alle 75 Teilnehmenden Englischkenntnisse, 47 gaben auch an, rheinischen Dialekt bzw. Kölsch zu verstehen. Niederländisch bzw. Niederdeutsch zu verstehen erklärten 18 bzw. 15; dies scheint sich allerdings eher auf den subjektiven Eindruck des Verstehen-Könnens zu stützen als auf tatsächliche Sprachkenntnisse: Für das geläufige nl. Wort lucht 'Luft' gaben 16 der 18 Teilnehmer, die "Nl. verstehen" bejahten, falsche Lösungen an, und aus den – durchweg falschen – Angaben für deeg 'Teig' wird auch deutlich, dass keine Vertrautheit mit den geläufigsten nl.-dt. Lautentsprechungen besteht. Ebenso gehen auch die angegebenen Niederdeutsch-Kenntnisse kaum mit besseren Erschließungserfolgen bei eek 'Eiche' oder struk 'Strauch' einher (13 bzw. 11 von 15 falsch). Luxemburgisch zu verstehen bejahten sechs Personen, davon erkannten aber nur zwei lux. kand 'Kind'. Verstehen skandinavischer Sprachen wurde noch seltener angegeben (viermal Schwedisch, einmal davon außerdem Isländisch), wobei die Trefferquoten bei skandinavischen Items und einschlägigen Lautentsprechungen zumindest bei zwei dieser Teilnehmer für tatsächlich vorhandene (Grund-)Kenntnisse sprechen. Hier ist die subjektive Einschätzung "das versteht man irgendwie" angesichts der größeren Distanz vermutlich weniger verbreitet als beim Niederländischen. Die Gesamt-Erkennungsquote (richtige + mögliche Antworten) für die 28 echten Kognaten liegt jedoch für die vier Teilnehmer mit Kenntnissen skandinavischer Sprachen sogar leicht unter dem Gesamtmittel (42,9% gegenüber 43,6%). zurück
17 Die konstruierten können hier nicht einbezogen werden, weil die Kategorien "richtig" und "möglich" dabei nicht unterschieden werden können. zurück
18 Vgl. etwa nl. hek ⇒ dt. Hecke, nl. haat ⇒ dt. Hass (Vokalquantität); bzw. nl. stof ⇒ dt. Staub. zurück
19 Vgl. engl. eye, kölnisch Luff – die Tilgung von finalem t nach Konsonant ist zwar zumindest in frequenten Wörtern eine geläufig (vgl. dt. is(t), jetz(t)); im Rahmen der graphisch fixierten Korrespondenzen zwischen anderen germanischen Sprachen und dem Deutschen spielt diese Erscheinung jedoch keine Rolle, und für den Erfolg von Interkomprehension ist es eher gefährlich, finales t "beliebig" wegzulassen oder hinzuzusetzen. zurück
20 Absolut gerechnet (= Zahl der abweichenden Segmente), nicht relativ bezogen auf die Wortlänge, die bei den Testitems nur geringfügig variiert. zurück
21 Hier wäre zu überlegen, ob d im Auslaut und t als unterschiedliche Segmente zu werten sind – dafür spricht aber, dass bei Anhängen von Schwa die Auslautverhärtung entfällt (obwohl sie sicherlich eine Rolle für dieses Ergebnis spielt, s. a. u.). zurück
22 Vgl. de.wikipedia.org/wiki/Drei_Chinesen_mit_dem_Kontrabass, Stand 23.9.2010. zurück
23 Die Senkung von i, ü und u wird auch als stereotypes Kennzeichen für affektiertes Sprechen benutzt, vgl. etwa "Met der Schole est es wie met einer Medizin – sä moß better schmecken, sonst nötzt sä nechts" (Spoerl 1981: 13) oder "Ich wörde die ganze Zockerböchse nehmen" (Mann 1960: 86). zurück
24 Vgl. "Also weil ich Spaß an einer Uhr habe, die ich täglich trage und die nun leider mehr kostet, als der geneigte Leser für eine Uhr aufbringen will/kann, bin ich ein Schnob?" (vgl. Taucher.net 2009), oder "bekomme ich von der ehemaligen Dispatcherin der Kleiderkammer, die nun das Lifestyle-Ressort leitet und sich 'Karen' nennt (früher hieß sie Svetlana), zu hören: 'Wat denn, Männeken, wenn Se sich keen Schmoking (sic!) leistn könn , müssn Se sich een leihn.'" (Scheel 2001). zurück
25 Vgl. Elspaß/Möller (2003ff.), Atlas zur deutschen Alltagssprache, erste Runde: 'Tag', siehe www.philhist.uni-augsburg.de/lehrstuehle/germanistik/sprachwissenschaft/ada/runde_1/f15a-b/. zurück
26 Diese Substitution fällt nur bei dem Item telt ⇒ Zelt durch eine besonders hohe Übereinstimmung auf, was sich allerdings wohl eher mit einem Einfluss von engl. tent erklärt als mit einer besonderen Durchsichtigkeit dieser Korrespondenz (vgl. Möller/Zeevaert 2010: 236). zurück
27 Vgl. (bezogen auf Dialekt-Standard-Beziehungen) a. den Begriff der "Tendenzen" bei Auer (1990: 278 u. ö.). Das Phänomen der Übergeneralisierung solcher Muster (Hyperkorrektismen – Hyperdialektismen) weist darauf hin, dass aus solchen "Tendenzen" häufig aktiv verwendete Korrespondenzregeln entwickelt werden (vgl. ebd.: 274). zurück
28 Außerdem wurden beide Versionen noch einmal in sich in zwei Varianten mit unterschiedlicher Reihenfolge der Items vergeben. zurück
29 58% Substitution statt Tilgung/Einfügung, ohne die Ausnahmen Schwa und nd-Assimilation 66,11% (11 Items); 53% vokalische statt konsonantischer Substitution (bei 10 Items alternativ möglich). Stärker als in der freien Abfrage zeigt sich eine Präferenz für Invarianz des Anlauts (72,42%), wobei die Aussagekraft dieser Zahl allerdings auch hier durch die Kreuzung des Faktors Position mit dem Faktor Ähnlichkeit/Vertrautheit der Korrespondenz stark beeinträchtigt wird. Beim Item dadel, wo die Substitution d => t im Anlaut (Tadel) oder im Inlaut (Dattel) vorgenommen werden kann, ist wiederum gerade in der freien Abfrage zu erkennen, dass die Lösung mit Beibehaltung des Anlauts trotz der hierbei nötigen zusätzlichen Modifikation der Vokalquantität relativ häufig gewählt wird (noch 15% Dattel, gegenüber 23% Tadel), während im Multiple-Choice-Test die Präferenz für die insgesamt weniger abweichende Lösung klarer ist (28% Dattel gegenüber 72% Tadel). zurück
30 baune: 62% bzw. 83% Bohne (Vers. A bzw. Vers. B) – soom: 86% bzw. 83% Saum. zurück
31 Kenntnisse niederdeutscher Dialekte, in denen au einem standarddt. o: entsprechen kann, waren bei der Mehrheit der Probanden jedenfalls nicht vorhanden. zurück
32 Dies gilt ebenso für die freie Abfrage (75% bzw. 86%). zurück
33 Ein Item wurde im Multiple-Choice-Test nicht mit diesen beiden Lösungsoptionen geprüft. Für die unterschiedlichen Ergebnisse ist dieses Item aber nicht ausschlaggebend. zurück
34 Vgl. a. Archibald (1998: 102) zur selben Beobachtung bei Fremdsprachenakzent. zurück
35 Die umgekehrte Entwicklung /x/ > /f/ im Englischen (vgl. laugh u. ä.) hat sich dagegen nicht in der Orthographie niedergeschlagen. zurück
36 Vgl. die Ergebnisse für die Items urm (freie Abfrage: 10% Wurm), jerz (freie Abfrage: 3% Erz) und kjern (freie Abfrage: 64% Kern). zurück
Archibald, John (1998): Second Language Phonology. Amsterdam/Philadelphia.
Arntz, Reiner (1997): "Passive Mehrsprachigkeit – eine Chance für die "kleinen" Sprachen Europas". In: Ammon, Ulrich/Mattheier, Klaus J./Nelde, Peter H. (eds.): Einsprachigkeit ist heilbar – Überlegungen zur neuen Mehrsprachigkeit Europas. Tübingen: 166–183. (= Sociolinguistica 11).
Ashby, Michael/Maidment, John (2005): Introducing phonetic science. Cambridge.
Auer, Peter (1990): Phonologie der Alltagssprache. Eine Untersuchung zur Standard/Dialekt-Variation am Beispiel der Konstanzer Stadtsprache. Berlin/New York.
Back, Michal (1991): Die synchrone Prozessbasis des natürlichen Lautwandels. Stuttgart. (= Zeitschrift für Dialektologie und Linguistik, Beiheft 71).
Beijering, Karin/Gooskens, Charlotte/Heeringa, Wilbert (2008): "Predicting intelligibility and perceived linguistic distance by means of the Levenshtein algorithm". Linguistics in the Netherlands: 13–24.
Berthele, Raphael (2007): "Zum Prozess des Verstehens und Erschließens". In: Hufeisen/Marx (eds.) (2007): 15–26.
Berthele, Raphael (2008): "Dialekt-Standard Situationen als embryonale Mehrsprachigkeit. Erkenntnisse zum interlingualen Potenzial des Provinzlerdaseins". In: Mattheier, Klaus J./Lenz, Alexandra (eds.): Dialektsoziologie. Tübingen: 87–107. (= Sociolinguistica 22).
Berthele, Raphael et al. (im Druck): "Zu den Grenzen des EuroCom-Konzeptes für EuroComGerm – Zwischenfazit". In: Ohnheiser, Ingeborg/Pöckl, Wolfgang/Sandrini, Peter (eds.): Translation – Sprachvariation – Mehrsprachigkeit.
Castagne, Eric (2004): "Intercompréhension européenne et plurilinguisme ... aménagements linguistiques favorisant la communication plurilingue". In: Klein, Horst G./Rutke, Dorothea (eds.): Neuere Forschungen zur Europäischen Interkomprehension. Aachen: 95–108. (= Editiones EuroCom 21).
De Vries, Jan/De Tollenaere, F. (1997): Nederlands etymologisch woordenboek. 4. Aufl. Leiden.
Doyé, Peter (2006): "Interkomprehension – Versuch einer Begriffsklärung". Zeitschrift für Fremdsprachenforschung 2006/2: 245–256.
Elspaß, Stephan/Möller, Robert (2003ff.): Atlas zur deutschen Alltagssprache. Online unter www.philhist.uni-augsburg.de/ada.
Flege, James Emil (1995): "Second Language Speech Learning. Theory, Findings, and Problems". In: Strange,Winifred (ed.): Speech perception and linguistic experience: issues in cross-language research. Baltimore: 233–277.
Gooskens, Charlotte/Heeringa, Wilbert/Beijering, Karin (2008): "Phonetic and lexical predictors of intelligibility". International Journal of Humanities and Arts Computing 2: 63–81.
Guentherodt, Ingrid (1983): "Assimilation und Dissimilation in den deutschen Dialekten". In: Besch, Werner et al. (eds.) (1983): Dialektologie. Ein Handbuch zur deutschen und allgemeinen Dialektforschung. 2. Halbbd. Berlin/New York: 1139–1147.
Heeringa, Wilbert (2004): Measuring Dialect Pronunciation Differences using Levenshtein Distance. Groningen. (= Groningen dissertations in linguistics 46).
Heggarty, Paul/McMahon, April/McMahon, Robert (2005): "From phonetic similarity to dialect classification: A principled approach". In: Delbecque, Nicole/var der Auwera, Johan/Geeraerts, Dirk (eds.): Perspectives on variation: sociolinguistic, historical, comparative. Berlin/New York: 43–91.
Herrgen, Joachim et al. (2001): Dialektalität als phonetische Distanz. Ein Verfahren zur Messung standarddivergenter Sprechformen. Online unter www.sprachatlas.de, Stand 10.11.2008.
Hock, Hans Henrich/Joseph, Brian D. (1996): Language History, Language Change and Language Relationship. An Introduction to Historical und Comparative Linguistics. Berlin/New York.
Hufeisen, Britta/Marx, Nicole (eds.) (2007): EuroComGerm – Die sieben Siebe: Germanische Sprachen lesen lernen. Aachen.
Klein, Horst G./Stegmann, Tilbert D. (2000): EuroComRom – Die sieben Siebe: Romanische Sprachen sofort lesen können. 3. Aufl. Aachen.
Krech, Eva-Maria et al. (2009): Deutsches Aussprachewörterbuch. Berlin/New York.
Kürschner, Sebastian/Gooskens, Charlotte/van Bezooien, Renée (2008): "Linguistic determinants of the intelligibility of Swedish words among Danes". International Journal of Humanities and Arts Computing 2: 83–100.
Lüdi, Georges (2007): "The Swiss model of plurilingual communication". In: ten Thije, Jan D./Zeevaert, Ludger (eds.): Receptive Multilingualism. Linguistic analyses, language policies and didactic concepts. Amsterdam, Philadelphia. (= Hamburg Studies on Multilingualism 6).
Lutjeharms, Madeline (1997): "Worterkennen". In: Börner, Wolfgang/Vogel, Klaus (eds.): Kognitive Linguistik und Fremdsprachenerwerb: Das mentale Lexikon. 2. überarb. Aufl. Tübingen: 149–165.
Lutjeharms, Madeline (2006): "Worterkennung und syntaktische Analyse beim Lesen. Ein Forschungsüberblick". Muttersprache 116/3: 204–215.
Lutjeharms, Madeline/Möller, Robert (2007): "Sieb 3: Laut- und Graphementsprechungen". In: Hufeisen/Marx (eds.) (2007): 87–144.
Mann, Thomas (1960): Buddenbrooks. In: Ders., Gesammelte Werke Bd. 1.1. Frankfurt/Main.
Meißner (2004): "Transfer und Transferieren. Anleitungen zum Interkomprehensionsunterricht". In: Klein, Horst G./Rutke, Dorothea (eds.): Neuere Forschungen zur Europäischen Interkomprehension. Aachen, Shaker: 39–66. (= Editiones EuroCom 21).
Moberg, Jens/Gooskens, Charlotte (2007): "Konditionell entropi som mått på lingvistiskt avstånd mellan danska och svenska". In: Widell, Peter/Berthelsen, Ulf Dalvad (eds.): 11. Møde om Udforskningen af Dansk Sprog, Aarhus Universitet 12.–13. oktober 2006. Århus: 101–110.
Möller, Robert (2007): "A computer-based exploration of the lexical possibilities of intercomprehension: Finding German cognates of Dutch words". In: ten Thije, Jan D./Zeevaert, Ludger (eds.): Receptive Multilingualism. Linguistic analyses, language policies and didactic concepts. Amsterdam/Philadelphia: 285–305. (= Hamburg Studies on Multilingualism 6).
Möller, Robert/Zeevaert, Ludger (im Druck): "'Da denke ich spontan an Tafel' –
Zur Worterkennung in verwandten germanischen Sprachen". Zeitschrift für Fremdsprachenforschung.
Primus, Beatrice (2002): "Unreine Reime und phonologische Theorie". In: Rastle, David/Zaefferer, Dietmar (eds.): Sounds and Systems. Studies in Structure and Change. A Festschrift for Theo Vennemann. Berlin/New York: 269–298. (= Trends in Linguistics. Studies and Monographs 141).
Rastle, Kathy/Brysbaert, Marc (2006): "Masked phonological priming effects in English: Are they real? Do they matter?" Cognitive Psychology 53: 97–145.
Rickheit, Gert/Strohner, Hans (2003): "Inferenzen". In: Rickheit, Gert/Herrmann, Theo/Deutsch, Werner (eds.): Psycholinguistik – Psycholinguistics. Ein internationales Handbuch. Berlin/New York: 566–577.
Scheel, Kurt (2001): "No Smoking!" Berliner Zeitung 12.02.2001. Online unter http://www.berlinonline.de/berliner-zeitung/archiv/.bin/dump.fcgi/2001/0212/feuilleton/0026/index.html, Stand 31.03.2010.
Spoerl, Heinrich (101981): Die Feuerzangenbowle. München.
Tafel, Karin et al. (2009): Slavische Interkomprehension. Eine Einführung. Tübingen.
Taucher.net Forum Tauchausrüstung: "Poseidon Taucheruhr P10032-BK". www.taucher.net/forum/Poseidon_Taucheruhr_P10032-BK_equip17151.html, Stand 30.5.2009.
Wenzel, Veronika (2007): "Rezeptive Mehrsprachigkeit und Sprachdistanz deutsch-niederländisch". Zeitschrift für Fremdsprachenforschung 18/2: 183–208.
baune: isl. baun ⇒ Bohne
bech: konstr. (⇒Bach/Pech)
ben: skand. ⇒ Bein
blekk: konstr. (⇒ Blech/Blick)
dadel: nl. ⇒ Dattel, dän. ⇒ Tadel
deeg: nl. ⇒ Teig
eek: nd. ⇒ Eiche
fag: dän. ⇒ Fach
hommel: nl. ⇒ Hummel
jerz: konstr. (⇒ Erz)
kand: lux. ⇒ Kind
kaut: konstr.,(⇒ Kauz)
kjern: norw. kjerne ⇒ Kern
lof: nl. ⇒ Lob
lucht: nl., Luft
mand: dän. ⇒ Mann
maven: dän. mave ⇒ Magen
munn: fries. mûn ⇒ Mund
nafel: isl. nafli ⇒ Nabel
nier: nl. ⇒ Niere
plass: norw. ⇒ Platz
schanne: konstr.(⇒ Schande)
sikt: skand. ⇒ Sicht
skell: konstr. (⇒ Schelle)
slugt: dän. ⇒ Schlucht
slut: skand. ⇒ Schluss
snegg: konstr. (⇒ Schnecke)
soom: nl. zoom ⇒ Saum
spied: dän. ⇒ Spieß
spinde: dän. Verb ⇒ spinnen [→ Spinne]
steren: konstr. (⇒ Stern)
stort: nl. stort- , (Verb storten) ⇒ Sturz
struk: nd. ⇒ Strauch
tarm: skand. ⇒ Darm
telt: skand. ⇒ Zelt
urm: skand. orm ⇒ Wurm
wend: konstr. (⇒ Wind/Wand/Wende)
wrinde: konstr. (⇒ Winde/Rinde)