http://dx.doi.org/10.13092/lo.88.4189
In the case of written language, the nature of the linguistic units ranking above word level is clear. Although it can be analyzed at different levels (e. g. argument structures, sentences or clauses, head dependent structures (cf. Abeillé 2003: xvi–xviii; Montemagni et al. 2003), written language may be properly segmented according to syntactic and semantic principles. However, the identification of reference units in speech is very unlikely via the same syntactic and semantic devices (cf. Biber et al. 1999: 50–51; Miller/Weinert 1998: 28–71; Izre’el 2005: 2–5).
There is a tradition of studies in which the reference unit for speech is identified by the term “utterance”. However, the utterance may also be anchored to syntactic and/or semantic properties. For instance, it may be evaluated as a syntactic clause (cf. Miller/Weinert 1998: 76–77), or, as in The Longman Grammar, as a C-Unit with or without a clause structure (cf. Biber et al. 1999: 245–246). Claire Blanche-Benveniste proposed the identification of the nucleus of an utterance in a macro-syntactic domain, named noyau, which would bear a modal value (cf. Blanche-Benveniste 2003: 56–57). The definition of such an entity is a complex matter, especially when its annotation in speech flow is required; the main problem is that in spontaneous spoken language many chunks which are not clauses may turn out to be autonomous entities from a communicative point of view.1
Austin (1962) defines the utterance as the linguistic counterpart to a speech act and consequently it can be considered the minimal linguistic entity such as can be pragmatically interpreted. It must be remembered that one of the most important English grammars such as the Spoken and written grammar of English (Biber et al. 1999: 1072) take the utterance as the reference unit for speech, giving it an illocutionary definition and considering it as a linguistic entity that is concluded and autonomous from a pragmatic point of view.2 In accordance with this, the pragmatically defined utterance is proposed as the reference unit for the analysis of speech.
However, if the systematic tagging of large spontaneous corpora is the task which speech analysis is faced with, utilizing a pragmatic definition of the utterance may not be enough. Pragmatics is unlikely to benefit from corpus data if the object carrying the pragmatic qualities, i. e. the utterance, is not identifiable within the corpus, and the task may be a difficult undertaking given the underdetermined nature of speech acts (Searle 1966; Kempson 1977: 42–43, 50–57; Searle/Vanderveken 1985; Sbisà/Turner 2013: 1–5).
Our assumption is that within spontaneous speech the formal identification of utterances can be achieved by prosodic means. Specifically, through prosodic breaks which are highly detectable in speech flow and which we call “terminal prosodic breaks”. This viewpoint is the result of a long analysis carried out by the LABLITA team over the last thirty years, in which we verified the systematic correspondence between the prosodic part of a stretch of speech and the accomplishment of an illocutionary force in Austin’s terms.
LABLITA archives an important corpus of spontaneous spoken Italian (600 h., recordings from 1965 [Stammerjohann Corpus, Moneglia/Scarano 2006] to the present day), containing a large variety of spoken typologies (spontaneous speech; Radio-TV; movies; telephone; early acquisition; impaired language). The transcriptions correspond to nearly 1 million and half tokens in the LABLITA-CHAT format (MacWhinney 2000; Moneglia/Cresti 1997), which are lemmatized and PoS tagged. All files are classified according to IMDI Metadata and the recordings comply with privacy and ethical requirements. What is most innovative in the LABLITA Corpus is the per utterance text/sound alignment (nearly 800’000 tokens, 92’000 terminated units), which is based on the perceptual identification of utterances through terminal prosodic breaks (cf. Cresti et al. forthcoming).
LABLITA was the coordinator of a European Project which collected and analyzed the C-ORAL-ROM resource, the latter being a multilingual corpus of spontaneous speech for the main Romance languages (French, Italian, Portuguese, Spanish) with around 300’000 words for each language, 123:27:35 hours of speech, and 1426 recorded speakers. The transcriptions follow the LABLITA-CHAT format and the per utterance text/sound alignment is extended to the whole Romance resource (cf. C-ORAL-ROM, Cresti/Moneglia 2005).3 The C-ORAL-ROM DVD is bundled with tools for the exploitation of the linguistic data at the textual and acoustic levels.
LABLITA developed a web resource for the segmentation and tagging of utterances based on L-AcT, which is now online. It contains multiple databases for Information Patterning Interlinguistic Comparison (IPIC; cf. Panunzi/Gregori 2012; Panunzi/Mittmann 2014) the first being the informal Italian part of C-ORAL-ROM (74 texts, 124’735 words, 21’007 terminated units). There are, furthermore, 2 comparable mini-corpora: the Brazilian IPIC DB (20 texts; 29’909 words; 5’511 terminated units), which is derived from the informal part of C-ORAL-BRAZIL (cf. Raso/Mello 2012)4 and the Italian IPIC DB which is a selection from the larger Italian corpus (20 texts; 32’589 words; 5’663 terminated units). Currently undergoing completion is an IPIC database for a comparable mini-corpus of about 5’000 utterances (cf. Cavalcante/Ramos 2016) taken from the American-English informal part of the S. Barbara Corpus (cf. Du Bois 2004) and an IPIC database for a comparable mini-corpus derived from the Spanish C-ORdiAL (cf. Nicolas 2012).
LABLITA’s lengthy work on text/sound alignment and the comparative analyses carried out on Romance and English corpora allowed the verification of the L-AcT hypothesis of the correspondence between terminal prosodic breaks and the illocutionary accomplishments of utterances.
Classic studies on prosody have always highlighted the fact that utterances end with a terminal profile (cf. Karcevsky 1931: 89; Crystal 1975: 21, passim); this characteristic is used in L-AcT as a heuristic for determining the utterance boundaries in speech flow and is based on perception, tracing back to the IPO (Institute for Perception Research) tradition which is based on the perceptual relevance of intentionally performed prosodic cues (cf. Hart et al. 1990: 69–70). These demarcative cues are so prominent that they require little training to be recognized. Indeed, competent speakers perceive them easily and can also distinguish between boundary types:
| 1. | boundaries with a terminal value (terminal breaks); |
| 2. | boundaries which indicate the utterance continues (non-terminal breaks) |
The most relevant acoustic features correlating with the perception of prosodic breaks are generally considered to be the following:
| a) | f0 reset (accomplishment of a Prosodic Pattern); |
| b) | final lengthening; |
| c) | drop in intensity; |
| d) | pause; |
| e) | initial rush of the next prosodic unit5 |
(cf. Cruttenden 1997: 29–37; Hirst/Di Cristo 1998: 35–36; Izre’el 2005: 2–5; Sorianello 2006)
The perceptual detection of these features can be analyzed in the laboratory with software such as PRAAT and WinPitch, however the practice of identifying utterance boundaries on a perceptual basis has been successful in transcribing large corpora (cf. Du Bois 1992; Du Bois 2004; Cheng/Greaves/Warren 2005; Izre’el 2005) beyond the C-ORAL corpora approach.6
The perceptual criterion grounding the annotation of the prosodic breaks has been validated in the C-ORAL-ROM Project and in the C-ORAL-BRAZIL project. The prosodic tagging of the multilingual Romance corpus C-ORAL-ROM was verified by a third party in a large-scale evaluation performed by mother tongue non-expert annotators (cf. Danieli et al. 2004). The data shows strong agreement at the cross-linguistic level between the Romance languages for the terminal break annotation. The terminal breaks have been confirmed by evaluators more than 94 % of the time for all languages and the K value (Cohen realistic) is also high in all resources (> 8 in all Romance languages, except French).
The inter-annotator agreement test on the C-ORAL-BRAZIL corpus replicated this overall result and was performed by experts and non-experts (cf. Moneglia et al. 2010). Where agreement on the presence of a break is concerned there is little difference between the K scores reached by the two groups of annotators. K is around or over 0.8, confirming that the detection of prosodic boundaries is a primary aspect of language perception. However, considering the realistic K score for terminal breaks, specifically, the group of expert annotators achieved better results (0.76) than the non-experts (0.67) and both groups recorded a K value of under 0.50 where consensus on non-terminal breaks was concerned.
Beyond the resources grounding the L-AcT approach, a validation of the prosodic tagging of the Dutch Corpus has also been performed with similar results (cf. Buhmann et al. 2002) and important studies have been accomplished during the preparatory studies of the CoSIH corpus of spoken Hebrew (cf. Izre’el et al. 2001; Amir al. 2004). Data shows that the break positions of short spontaneous speech narratives have been agreed upon by all annotators in 80 % of cases.
The different scores correlate with the types of prosodic breaks (terminal vs. non-terminal). Their identification is a function of judgment which requires direct perception of prosody, but is not limited to it, as it occurs in parallel with the recognition of the speech act accomplishment. In the L-AcT framework the terminated sequences are seen to coincide with the assignment of an illocutionary value to the stretch of speech identified by the prosody. For this reason, the consensus is stronger with respect to the identification of terminated sequences on the basis of individual perception, while the annotation of non-terminal breaks may require subsequent reanalysis by experts at a different level of annotation in connection with the analysis of the information structure of the utterance.
In conclusion, considering both the pragmatic value and the prosodic termination together ensures the recognition of an utterance. However, it must also be noted that one can count speech acts without clear agreement on their illocutionary value. In other words, the labelling of utterance limits is a matter of direct perception, while the assignment of specific values to speech acts is a categorization issue, requiring knowledge of linguistic types.7
The Language into Act Theory (L-AcT) has already been described in books and articles (cf. Cresti 2000, 2006, 2010, 2012a, 2014; Cresti/Moneglia 2005, 2010; Cresti et al. 2011; Moneglia 2006, 2011; Moneglia/Cresti 2006, 2015; Moneglia/Raso 2014; Firenzuoli 2000, 2003; Raso/Mello 2012; Scarano 2003, 2009).
The approach can be summarized as follows: within the Austinian tradition, the simultaneous accomplishment of three acts which compose the speech act (locution, illocution, perlocution) corresponds to an organic and ruled system. The speech activity originates in an ideational/affective mental representation as a reaction to external input, which often has its origins in human relational dynamics, and is manifested linguistically in an affective manner toward the addressee (perlocutionary act). In order to be performed the mental representation must be manifested in terms of a specific linguistic action schema, conventionally codified as a pragmatic issuance (illocutionary act). Furthermore, the internal action schema is transmitted in its turn by phonetic and prosodic means in the form of linguistic islands. These latter components are the end-production, which is directed toward the addressee, and the pragmatically packaged mental content is organized according to specific language competence (locutionary act).
Thus, in the L-AcT perspective the syntax is conceived as a combination of islands demarcated by prosodic units.8 Given that prosody achieves the necessary interface between the illocutionary and the locutionary act, its role is fundamental, although in this regard it presents a point of divergence from the Austinian tradition.
With respect to the deepest and most unconscious bases of its conception, the L-AcT approach traces back to philosophical assumptions in the Human Birth Theory by Fagioli (cf. Fagioli 2010, 2011, 2012; Gatti et al. 2012; Maccari et al. 2016). The involvement of pragmatic aspects in speech activation has confirmation in recent lines of research regarding the “embodiment of cognition” (Arbib 2012: 275). This is further supported by neurobiological research that grounds human cognition in a sensory-motor system which is shared with motion and perception and for speech also foresees a complex system of motor activation similar to and depending on that of non-linguistic actions (cf. Mollo et al. 2016). More generally, neuroscientists investigated the systems which underlie both language and sensorimotor faculties, and developed models in which linguistic, cognitive and motor abilities closely interact. For example, the processing of action related utterances involves the activation of the motor system in the brain, leading to an embodied representation of the linguistic meaning.9 Quite recent investigations are developing research on the initial and parallel processing stages of pragmatic and semantic information in speech acts, specifically naming and requesting, showing their neurophysiological evidence through Event Related Potential (ERP) characterization (cf. Egorova et al. 2013; Egorova et al. 2015).
L-AcT’s primary aim is to ground the analysis of spoken texts in the examination of the spoken activity. The assumption of a pragmatic level as a mandatory stage in the activation of speech seems to constitute a marked divergence from other research on spoken language. For instance, one of the most well-known models, that of Chafe (1970), does not consider the necessity of this step in passing from thought to speech and foresees a direct correspondence between ideas and prosodic/linguistic units.
Furthermore, the information structure has its center, from the L-AcT perspective, in the pragmatic accomplishment achieved by a requisite information unit (comment), which is the component dedicated to expressing the illocution (and the illocution only). The Comment unit may be accompanied by optional components within a given information structure, i. e. information pattern, resulting in this structure being composed of many information units which develop different functions (topic, parenthesis, discourse markers, etc.; cf. Moneglia/Raso 2014).10 This approach to information structure departs from one of the most appreciated traditions of current times, that of Krifka (cf. Krikfa 2007; Krifka/Musan 2012), which derives from natural logics and finds in the context (common ground) the conditional origin of the information structure and, ultimately, of speech. Conversely, at the core of its conception L-AcT focuses on the subjective initiative of the speaker toward the addressee, reacting freely to the context instead of depending on it. The new information contained in the utterance is always an affective/pragmatic response by the speaker, expressed by the Comment, and is unpredictable.
In conclusion, L-AcT focuses on the pragmatic aspect of the reference units and on their information patterning – performed by the prosody – as a whole within an organic framework for speech analysis.
Our approach may be illustrated by looking at some simple examples taken from our Romance corpora and from the Santa Barbara Corpus.11 Let us consider the basic, unannotated transcriptions of the following dialogic turns from (1a) to (5a)12 as linear word sequences:
| (1a) | I don’t care that was the ugliest shoes I ever saw in my life |
| (2a) | surtout maintenant c’est de plus en plus |
| ‘especially now it is more and more’ | |
| (3a) | ça c’est clair de plus en plus |
| ‘this is clear more and more’ | |
| (4a) | lei gliene serve una anch’a lei una in più o no no lei ha questa |
| ‘you you need one more too one more or not no you have this one’ | |
| (5a) | c’est la carotte quoi carotte devant le nez du lapin |
| ‘that’s the carrot what the carrot before the rabbit nose’ |
No pragmatic values or syntactic configurations can be intelligibly assigned in the examples as we lack sufficient data for their processing and understanding. Syntactic configurations assigned to the previous examples would not provide enough evidence for a clear interpretation and misleading implications would occur as a result. Only access to the acoustic information and specifically the examination of the occurrence of terminal prosodic breaks within the sound sequence allows the demarcation of the utterances. Only after the identification of the reference units does it become possible both to assign the proper illocutionary force to each utterance and to correctly interpret their syntactic structures; we look at examples (1), (2), and (3) in particular.
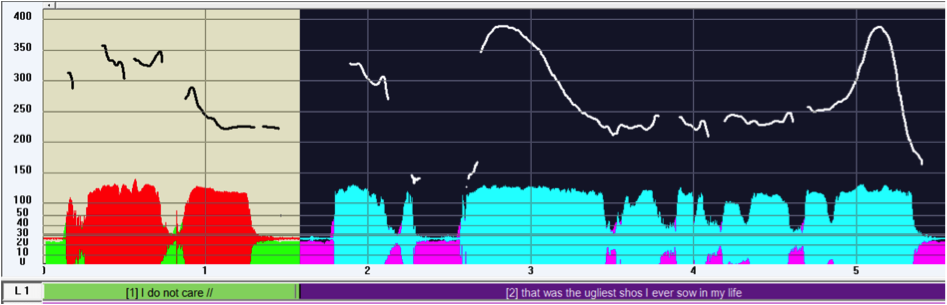
| (1) | *ALI: I don’t care //COMthat was the ugliest shoes /SCA ever saw in my life //COM13 |
| %ill: [1] disagreement; [2] %ill: contrast [afammn 03] |
Figure 1: F0 track of (1)
Listening to the entire audio-file of (1) and to the audio-file corresponding to the first and second prosodic units, which is confirmed by the F0 tracks in figure 1, it becomes clear that they demarcate two independent utterances, each accomplishing a different illocution (a disagreement and a contrast, respectively). Thus it’s possible to see that in the first utterance the sentence I don’t care must be interpreted on its own and it is not a main clause to be completed by a subordinate one. The second utterance in turn corresponds to an independent sentence and not to a subordinate clause introduced by the complementizer that, since the latter is a pronoun developing a subject function.14
If you can imagine that (2) and (3) have the same syntactic structure, by listening to their audio-files and looking at their f0 tracks in figures 2 and 3 we can see that they are, in fact, different.
| (2) | EMA: surtout maintenant c’est de plus en plus //COM |
| ‘especially now it is more and more’ | |
| %ill: assertion [fpubdl03- Obséques] |
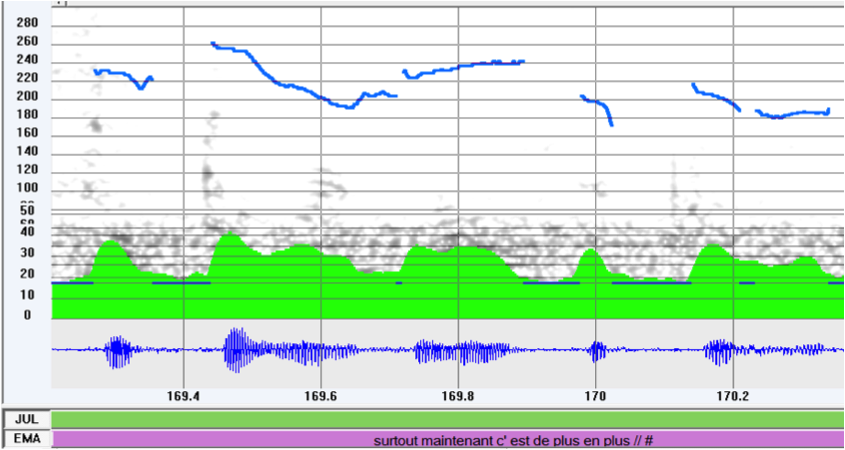
Figure 2: F0 track of (2)
| (3) | *EMA: ça c’est clair //COM de plus en plus //COM |
| ‘this is clear // more and more’ | |
| %ill: [1] assertion; [2] conclusion |
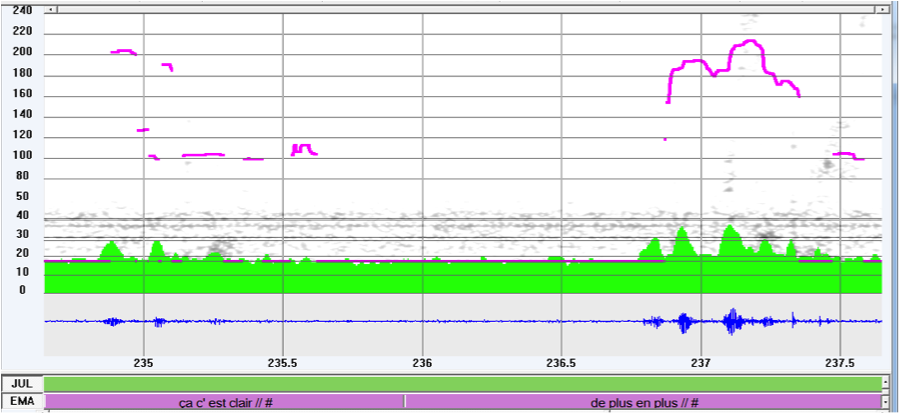
Figure 3: F0 track of (3)
Indeed (2) corresponds to a single prosodic unit, demarcating one utterance, which accomplishes a simple assertion and corresponds syntactically to a sentence, while (3) corresponds to two prosodic units and two utterances, the first accomplishing an assertion and the second a conclusion. Thus the adverbial PP de plus en plus in (2) is the nominal part of the copular predicate, while (3) develops, in isolation, a kind of verbless sentence which are frequent in spontaneous speech.15 The assignment of the syntactic structure to the speech flow can be performed only after evaluating how it has been performed prosodically and not vice-versa.
In fact, the problematic interpretations for (4a) and (5a), if they were based on their mere transcriptions, would be resolved through considering their audio-files and f0 tracks. Figure 4 shows four utterances within the continuous sound sequence, and (5) is found to be composed of two utterances, each developing a specific illocution.
| (4) | *SUS: lei /TOP gliene serve una anch’a lei ?COM una in più / o no ?COM no //COM lei ha questa //COM |
| ‘you / (do) you need one also for you ? one more / or not ? no / you have this one’ [LAB-01] | |
| %ill: [1] yes-no question; [2] alternative question; [3] self-answer; [4] ascertainment |
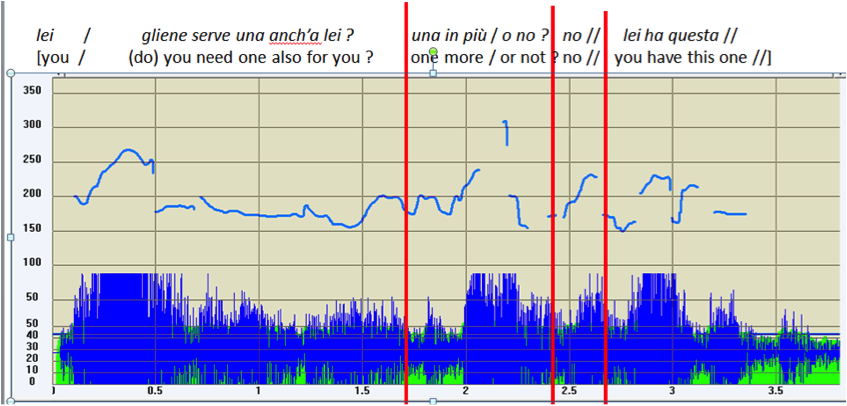
Figure 4: F0 track of (4)
| (5) | *JEA: c’est la carotte quoi //COM carotte devant le nez du lapin //COM |
| ‘it is the carrot in effect // the carrot in front of the nose of the rabbit’ [ffamdl08] | |
| %ill: [1] explication; [2] conclusion |
Let us look at two excerpts of continuous speech from the Santa Barbara Corpus and the LABLITA Corpus, which are composed of multiple dialogic turns and of roughly the same number of utterances. While the English text in (6) considers dialogue between a man and a girl explaining how to play the card game Hearts on the computer, the Italian text in (7) concerns dialogue between a Vespa seller and a customer.
| (6) | Hearts [afamdl05] |
| *DAN: neat //COM wait //COM play novice //COM I’ve never played Hearts before /COM <in my life> //APC | |
| %ill: [1] move (assent); [2] move (waiting request); [3] assertion (self-conclusion); [4] assertion (admission) | |
| *JEN: <you’ve never> played hearts //COM | |
| %ill: acknowledgment (with tired or sufficiency attitude) | |
| *DAN: no /CMM I don’t know how to play it //CMM16 | |
| %ill: [1] assertion + assertion explication, CMM reinforcement pattern | |
| *JEN: oh //COM okay /CMM I’ll teach you //CMM | |
| %ill: [1] expression of surrender; [2] conclusion + conclusion, CMM reinforcement pattern | |
| *DAN: passing disabled //COM <that’s you> //COM | |
| %ill: [1] citation (reading on the video); [2] directive (agreement) | |
| (7) | Vespa [ipbdl11] |
| *ALE: sera //COM arrivo /COM eh //PHA finisco di mettere /SCA # in esposizione <i veicoli> //COM | |
| ‘evening // I’m coming eh // I’m just displaying / the vehicles //’ | |
| %ill: [1] ritual, welcome; [2] direction, request for waiting; [3] assertion, explanation | |
| *GAB: <faccia> /CMM faccia pure //CMM (per)ché tanto (ho) tempo //COM non c’è premura //COM sabato sera…COM | |
| ‘let’s go / let’s go // ‘cause anyway I have time // there is no rush // Saturday evening …’ | |
| %ill: [1]direction + direction agreement, CMM reinforcement; [3] assertion, explanation; [4] assertion, explanation; [5] interrupted, (expression of obviousness) | |
| *ALE: yyyy # ecco qua //COM mettiamo a posto <questi> //COM | |
| ‘yyy here it is // we put these in their place //’ | |
| %ill: [1] assertion, conclusion; [2] overlapping, (commentary) | |
| *GAB: <io cer> [/]EMP cercavo una vespa // COM | |
| ‘I was / was looking for a Vespa //’ | |
| %ill: [1] assertion taken for granted | |
| *ALE: sì //COM | |
| ‘yeah //’ | |
| %ill: [1] ritual, conversation move, assent | |
| *GAB: cinquanta //COM non so se usata /CMM nuova /CMM ha qualche cosa ?CMM | |
| ‘fifty // I don’t know if second hand / new / have you anything?’ | |
| %ill: [1] direction, instruction; [2] direction + direction + direction yes/no question, CMM list |
Then the access to acoustic information is a basic requirement for the exploitation of spoken corpora and it must put at disposal at least some kind of text/sound alignment. More specifically it’s better that the parsing of the speech flow is done with terminal prosodic breaks, thus allowing the identification of reference units and, consequently, of both their pragmatic values and their syntactic structures.
In conclusion, according to L-AcT the reference unit for spoken language is the utterance and it is not underdetermined if its prosodic and pragmatic features are taken into account.17
The segmentation of speech does not end with the speech flow demarcation of the terminated sequences; an utterance’s text can be further prosodically segmented into its component entities. This kind of “packaging” of the spoken text has been interpreted as expressing a functional correlation with the information structure (cf. Chafe 1970: 210–233). In L-AcT terms, it is called the “information pattern”. Every utterance necessarily corresponds to an Information Pattern, which may be composed of many information units systematically demarcated by non-terminal prosodic breaks (Swerts/Geluykens 1993; Swerts 1997: 517–520; Moneglia/Cresti 2006: 94, passim; Moneglia/Cresti 2015: 117, 121–124). The internal cues used to identify information units participating in the Information Pattern are the same ones used for demarcating the utterance’s speech flow; the range of values are simply lower and weaker. Each prosodic unit belongs to a prosodic type characterized by perceptively relevant prosodic parameters, which are named in accordance with the IPO tradition (cf. Hart et al. 1990) and LABLITA’s research; i. e prefix, root, suffix, introducer, parenthetical (cf. Firenzuoli 2003). Moreover, there is a principle regulating the overall internal prosodic “harmony”: the well-known declination line (Cruttenden 1997: 162; Wichmann 2000: 103–109; Fox 2000: 307–310; Sorianello 2006a: 44–46).
An Information Pattern may be simple, which is to say composed of one only information unit. In C-ORAL-ROM these make up a high percentage of the utterances: nearly 35 %. According to the L-AcT point of view, this single unit is the comment, which is devoted to the accomplishment of the illocution, and presents sufficient and necessary conditions for performing an utterance.
Let’s look at some Italian examples (8–10) along with their f0 tracks (figures 5–7). Their utterances correspond to a simple Information Pattern composed of a single Comment unit, having illocutionary characterization and being sufficient so as to be pragmatically interpretable.
| (8) | *EST: quando parte ?COM |
| ‘when does he leave?’ | |
| %ill: partial question [ifamdl15] |
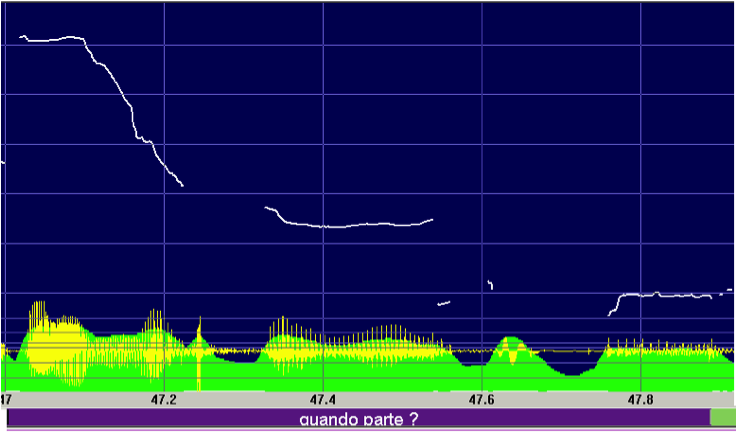
Figure 5: F0 track of (8)
| (9) | *LAB: Sabrina //COM |
| %ill: call to [visible] far away person [LAB-55] |
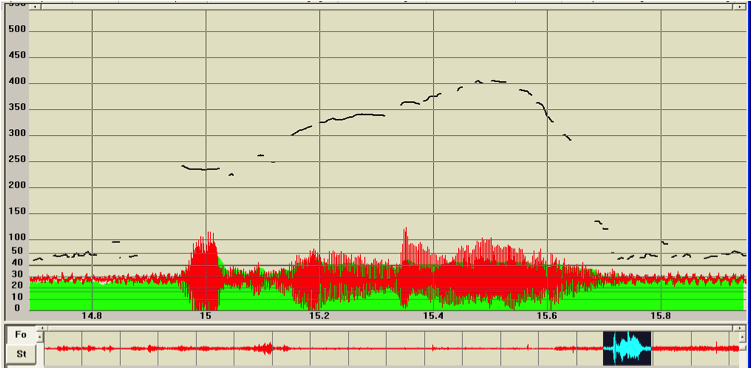
Figure 6: F0 track of (9)
| (10) | *MAX: ferma //COM |
| ‘stop’ [ifamdl19] | |
| %ill: order |
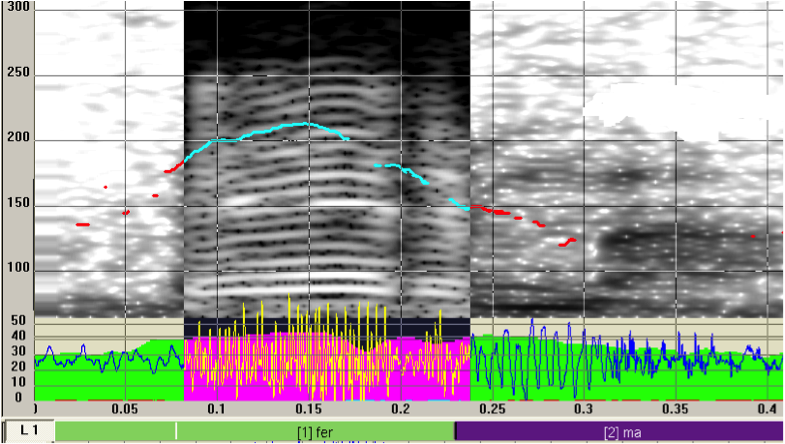
Figure 7: F0 track of (10)
Even if, according to the C-ORAL-ROM data, about 60 % of utterances contain further optional information units with different functions integrating and supporting the Comment, it must be stressed that the Information Pattern must always contain a Comment unit, which is its necessary core.
Let’s examine (11), which is a real and complete utterance performed by a speaker. Its f0 track is shown in figure 8, while (11a) and (11b) correspond to the laboratory’s progressive cutting of its wave file.
| (11a) | tutto pronto? |
| ‘everything ready?’ |
| (11b) | di là tutto pronto |
| ‘over there everything ready?’ |
| (11c) | *CEC: di là /TOP gli acidi /APT tutto pronto ?COM |
| ‘over there / (about) the acids /everything ready?’ [ifamdl17] | |
| %ill: polar question |
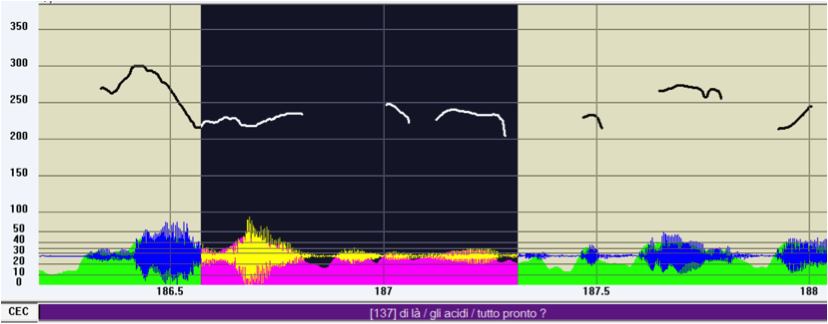
Figure 8: F0 track of (11)
It is evident that the audio of (11a) alone, which is a Comment unit accomplishing a polar question, is pragmatically interpretable and would present a sufficient enough utterance since it is prosodically terminated (verifiable from figure 8). In reality, however, the speaker wanted to also give the addressee a “field of application” for the question, specifying its location and argument, which is to say, its Topic and a kind of further integration (Appendix of Topic).18 By listening to the first two prosodic units we can see that they do not allow any pragmatic interpretation since their function is not to instruct the addressee on how to behave within the linguistic interaction (e. g. answering) – which the Comment does – but only to specify how the question should be interpreted.
Reviewing the previous figures, especially those from 5 to 8, we can appreciate the differing f0 profiles which correlate with the accomplishment of specific illocutionary types. The prosodic unit expressing the comment is called the “root”, in accordance with IPO terminology, and encompasses a set of variants. The root unit bears a prosodic prominence in its nuclear component which determines the variance and correlates with the expression of the illocutionary force (cf. Cresti 2012a: 74, passim). Studies dedicated to explicating the relationship between root units and illocutionary forces, as well as the conditions governing the performance of the various illocutionary act types, have been carried out for Italian (cf. Cresti/Firenzuoli 1999; Firenzuoli 2003; Cresti et al. 2003; Moneglia 2011; Cresti forthcoming a, forthcoming b) and for Brazilian Portuguese (cf. Rocha 2016). However, the details of this relation are beyond the scope of this paper.
What remains significant here is that the linguistic function of prosody goes beyond terminal and non-terminal break detection since it supports, and often determines, the expression of the illocutionary force in speech. Linguistic content can receive a pragmatic interpretation only if it accomplishes an illocutionary force which makes it interpretable in the real world. L-AcT stresses that in speech this information is necessarily conveyed by prosody, and example (12) shows this necessity in practice. Without the prosodic information, the sequence of three utterances, whose locution is always love, would simply be considered a case of repetition and would be almost meaningless. On the contrary, in considering the prosodic performances of the three utterances the dialogue exchange is easily understood by competent speakers.19
As can be verified by looking at the f0 tracks in figure 9, the profiles of the root units for each utterance demonstrate rising, rising modulated, and falling-rising (because of laugh) patterns, respectively.
| (12) | *DAR: do what you want /COMwith the time you have //APC learn /CMM give /CMM whatever //CMM |
| %ill: [1] invite; [2] suggestion (list) [afamdl02] | |
| *PAM: love //COM | |
| %ill: directive (proposal) | |
| *DAR: love //COM | |
| %ill: expressive (irony) | |
| *PAM: love //COM | |
| %ill: representative (conclusion) |
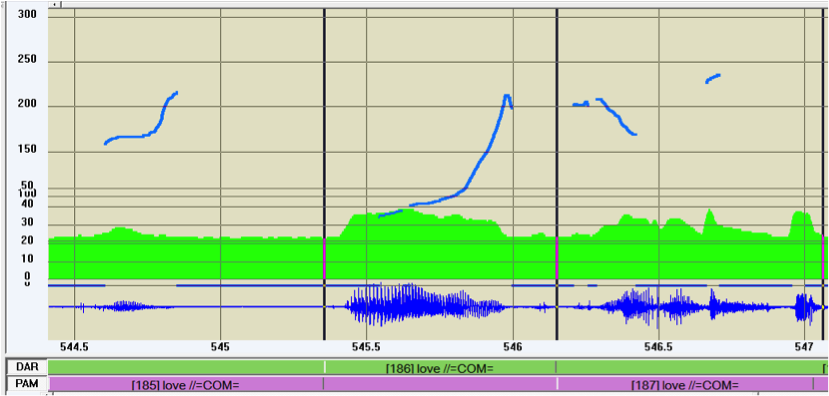
Figure 9: F0 track of (12)
The change in f0 track for each root unit in figure 9 is the only possible attribute responsible for the illocutionary values given to the three utterances, for which the locution love bears different illocutionary values each time (proposal/irony/confirmation). This judgment is a result of the prosodic information.
It must be stressed that the information structure does not end with the relation between the field of application of the force (Topic) and the accomplishment of the illocutionary force (Comment), even though this is the most frequent information strategy found and is also almost the only one investigated in literature. Our empirical study yields the discovery of some information functions ignored until now and to the confirmation of others which have already been cited in the literature, such as after-thought, parenthetical units, and discourse markers (generally speaking). However, what is truly significant is that the set of information functions that have been identified from corpus-driven Romance language research has been redefined, taking into account their prosodic features, and partly renamed according to an organic system within the L-AcT framework.
Generally speaking, a trend of isomorphic correspondences between the Information Pattern and the Prosodic Pattern is assumed (cf. Scarano 2009: 54–65). Consequently, no information function can be developed without being performed by way of a specific type of prosodic unit and this same prosodic unit cannot contain more than one information unit (and thus more than one information function). However, given that information functions are often defined in semantic terms, independent of their actual performance, these prosodic conditions seem to be ignored in the literature.
According to L-AcT, information functions are classified into two basic roles depending on whether they work (at some level) in fulfilling the semantic content of the utterance or in its communicative support. Thus far the corpus-driven classification of information types covers:
|
6 Textual functions: |
|
|
Comment (COM), Topic (TOP), Appendix of Comment (APC), Appendix of Topic (APT), Parenthesis (PAR), Locutive Introducer (INT) |
|
|
(cf. Cresti 2000; Signorini 2005; Giani 2005; Tucci 2004, 2010; Moneglia 2011; Mittman Malvessi 2012). |
|
|
6 Dialogical functions (Discourse markers): |
|
|
Incipit (INP), Phatic (PHA), Allocutive (ALL), Conative (CNT), Expressive (EXP), Dialogical Connector (DCT) |
|
|
(cf. Schriffin 1987; Frosali 2006; Pons Borderia 2008; Raso 2014; Moneglia/Cresti 2015). |
|
The Topic unit is traditionally considered the main way to structure information and, indeed, nearly 37 % of the compound utterances in Italian C-ORAL-ROM record a Topic-Comment Information Pattern. The linguistic fillings of the Comment and the Topic are dedicated to the performance of specific information functions:
| · | Comment: accomplishment of the illocution |
| · | Topic: «field» for the force’s application |
The Topic is marked by a non-terminal break and is performed by a prefix unit (IPO terminology), which bears a prosodic prominence correlating with the identification of the semantic field (cf. Cresti 2012a: 72–74). The Topic precedes the Comment and constitutes the domain in which the illocutionary force must be applied, allowing the Comment’s displacement from the context (cf. Hockett 1958: 201).
The following Italian example (13) concerns an utterance which contains a Topic-Comment Information Pattern, as can be seen in figure 10.
| (13) | *LID: il mi’ bisnonno /TOP Pietro //COM |
| ‘(about) my great-grand-father / (he was called) Peter’ [ifamdl 02] | |
| %ill: conclusion |
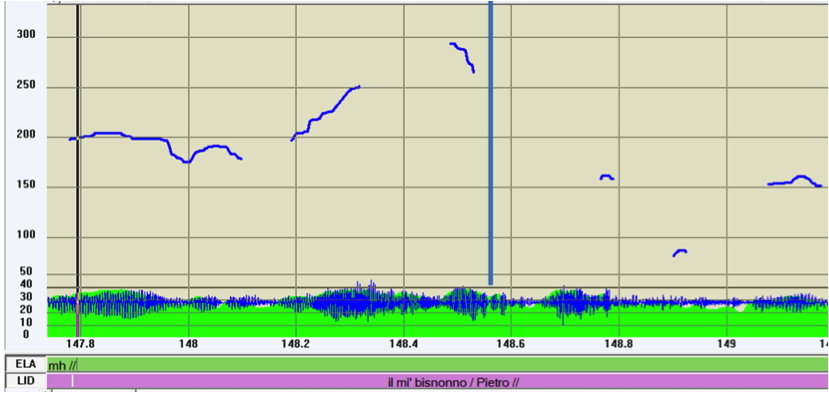
Figure 10: F0 track of (13)
(13) comes from a conversation in which the participants are looking for the names of their ancestors. As in previous examples, listening to the Comment allows the pragmatic interpretation of a conclusion, while listening to the Topic in isolation produce no intelligible pragmatic assignment. The utterance corresponds to a Topic-Comment Information Pattern performed via a prefix-root Prosodic Pattern. In this case their syntactic fulfillments are independent (i. e. non-compositional) and correspond to two separate syntactic phrases: a first NP my great-grand-father for the Topic and a second NP Peter for the Comment, differentiated functionally. The conclusion accomplished by Peter does not need to look for its application field in the context, since it is provided by my great-grand-father, thus the utterance is autonomous, or can be said to be displaced from the context. (13) is a Topic-Comment Information Pattern with no verb occurring in any of its linguistic fulfillments. Given that this nominal information strategy is quite frequent in all Romance languages, it must be underlined that the prefix-root Prosodic Pattern is the only way to allow the functional diversification of the two verbless groups. From a syntactic perspective this is a case of combining local syntactic islands.
Conversely, consider (14), which is a laboratory performance. It has been realized as a unitary sequence composed of the same two NPs found in (13), but integrated into a single root unit (see figure 11).
| (14) | *SP1: who is that man? |
| *LAB: il mi’ bisnonno Pietro //COM | |
| ‘my great-grand-father Peter’ [LAB-13] | |
| %ill: answer |
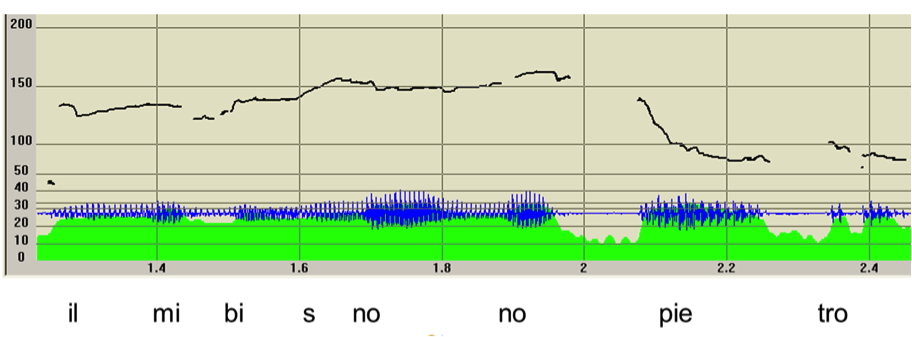
Figure 11: F0 track of (14)
This time the utterance corresponds to a simple Information Pattern, composed of just the Comment, and accomplishing an answer illocution. From a syntactic point of view the content is only a compositional NP, denoting my great-grand-father Peter. The utterance is no more displaced, because it can be interpreted only if it is related to the previous question introducing it, otherwise it should be imagined like an explication given about a picture in the context.
Let’s look at two French (15) and a Brazilian (16) Topic-Comment nominal examples:
| (15) | *EMA : sur la base /TOP très bon //COM |
| ‘basically / very good’ [fpubdl03] | |
| %ill: confirmation |
| (16) | *MAD: aì /TOP batata //COM |
| ‘there / potatoes’ [bfammn04] | |
| %ill: answer |
Even if verbless Topic-Comment strategies are rarer in English than in Romance languages, some examples may still be found. Consider (17) and (18):
| (17) | *ALN: most of them /TOP very expensive //COM |
| %ill: expression (disapproval) [afammn02] |
| (18) | *SCA: for two months /TOP prior to hear death …COM |
| %ill: expression of obviousness [afamdl02] |
In the few examples shown thus far it’s already worth remarking on the low occurrence of complex constructions implying, for instance, subordination, which results in a kind of overall syntactic reduction. What must be stressed, however, is the peculiar relation between these syntactic constituents and the information functions they are required to perform. We note in passing that, according to L-AcT, the compositional rules of syntax are enacted only inside the prosodic units, which are the interface between the Information Pattern and the locutio-nary act. In conclusion the syntax of the utterance corresponds to the combination of semantic and syntactic islands, which are bound to each other by pragmatic-information functions. Given that syntactic boundaries are delineated by prosody, and prosodic units are necessarily short due to physical constraints, even syntactic islands often result to be scarcely constructed (cf. Cresti 2012b, 2014, 2016; Cresti et al. 2011).
The Appendix of Comment (APC) in L-AcT performs the function of integrating itself with the text of the Comment and may be compared with the after-thought, anti-topic, and post-fix units (cf. Chafe 1976; Blanche-Benveniste 1990; Averintseva-Klisch 2008). Its occurrence is optional, even redundant, sometimes expressing a repetition, but judging by corpus-based data it seems to be performed on purpose by the speaker to put someone at ease. The APC necessarily follows the Comment, since it integrates with it. It does not bear a prosodic prominence, and, being defocused, must be performed by a suffix unit, in IPO terms. In accordance with the languages for which the suffix unit has been studied, its form is typically flat or falling (see below figure 12).
Let us look at two English examples (19) and (20) and one in Italian (21):
| (19) | *LAR: but it’s gonna be /SCAan extension of the kitchen /COM kind of //APC [apubdl02] |
| (20) | *TOB: so /INP but all that service time /TOP you put in thirty-five or forty <years /COM or> something like that /APC <right >//PHA [afamdl02] |
| (21) | *ZIA: tutto mio cognato /COM assomiglia //APC |
| ‘exactly my brother in law / (he) looks like’ [ifammn01] | |
| %ill: assertion (ascertainment) |
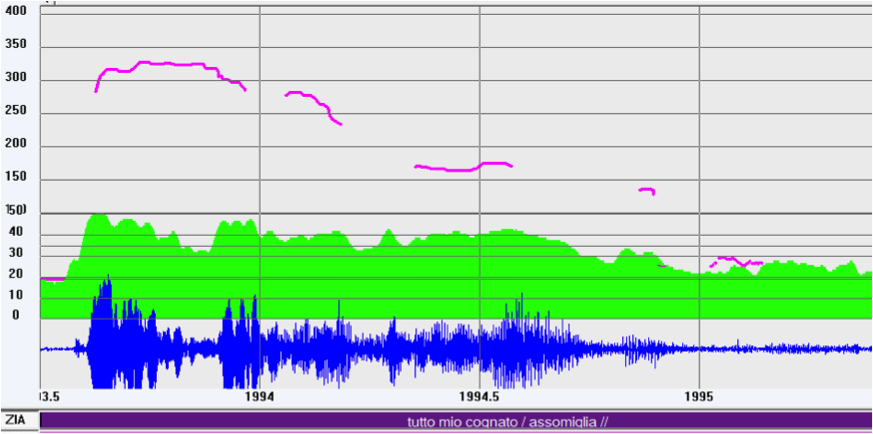
Figure 12: F0 track of (21)
In (21) a sort of mismatch between the syntax and the information structure is noticeable since the Comment corresponds to exactly my brother in law, which is a NP, but develops the significant illocutionary information. On the contrary, the VP looks like develops an optional, marginal Appendix function and could even have been cut out.
To our knowledge, no citation may be found in the literature of what is known within L-AcT as the Appendix of Topic (APT) (see example (11) above). The Appendix of Topic develops a partly similar function to the Appendix of Comment because it is conceived like a textual integration of the Topic content, in terms of delayed information, but lacks the agreement objective characterizing the latter. As far as the distribution of APC goes, it necessarily succeeds the Topic it integrates, and it is also performed by a suffix unit.
However, the Appendix of Topic is rare in both Italian and in English. (22) shows an English example and (11) an Italian one.
| (22) | *PAM: the thing I know most /TOPabout life and death /APT come from [/1] from my grandmother //COM |
| %ill: narration [afamdl02] |
| (11) | *CEC: di là /TOP gli acidi /APT tutto pronto ?COM |
| ‘over there / (about) the acids / everything ready?’ [ifamdl17] | |
| %ill: polar question |
The diverse functionalities of the information unit types are demonstrable through simple experiments. Again, the audio files for (19), (20), and (21) show the interpretability of the isolated Comment unit, while those of the Appendix of Comment are not interpretable in isolation. For the Appendix of Topic, the audio files (22) and (11) show in particular that there is no possible relationship between the Appendix of Topic and the Comment, even if they are contiguous and even if, in principle, the chunks about life and death and gli acidi should have been adequate arguments for the respective illocutions. Conversely, in these examples the relationship between the Topic and the Comment persists even if we cut out the Appendix of Topic.
Generally speaking, the Parenthesis unit (PAR) develops a metalinguistic function, since it demonstrates the speaker’s evaluation of his own utterance. It may help the addressee in different ways, clarifying the speaker’s attitude or giving the addressee explanations and pragmatic instructions with respect to the utterance. A Parenthesis is performed through a parenthetical unit, which does not bear a prosodic prominence. In accordance with the languages in which the parenthetical unit has been studied, it is characterized by a clear separation from the preceding prosodic unit and is often marked by a pause or a jump to a different f0 level, compared with the rest of the utterance (cf. Dehé 2014). The overall form of the f0 movement recorded in the Romance languages is flat (cf. Tucci 2010: 641–644), generally, even if it may record minor rising movements, and, in the case of a relevant lowering of the f0 value, may end with a sharply rising tail. It frequently co-occurs with an increased speech rate.
It is distributed freely, including inside other textual units (mostly Comments and Topics) as in (23) (see figure 13) and (24), although it can never occur at the absolute beginning of an utterance.
| (23) | *TOC: so I went to this /i-COM what I thought was my friend /PAR this navy captain down at /SCA naval headquarters //COM20 |
| %ill: narration [afamcv03] |
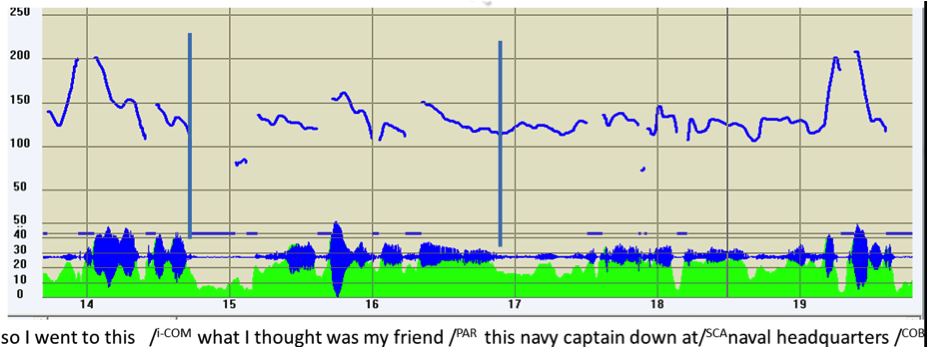
Figure 13: F0 track of (23)
| (24) | *LIA: e poi non c’era /i-COM come ora /PAR e’piatti /SCA usa e getta //COM |
| ‘and then there were not / as nowadays / disposable plates’ [ifamcv01] | |
| %ill: explanation |
Given their specific metalinguistic function, Parenthesis are frequently characterized by modal expressions (reduced parenthetical clauses, modal and stance adverbials), as in (25) (cf. Tucci 2009: 214).
| (25) | *PAM: and I &h [/1] I bit my tongue the other day /COB because /DCT remember /PAR you said to Davon /INT well /EXP_r I really want to spend time with you //COM_r21 |
| %ill: narration (stanza) [afamdl02-122] |
Again, the audio files show that Parenthesis units cannot be interpreted in isolation. From a syntactic perspective the parenthetical insertion demonstrates its non-compositional relation with the rest of the utterance.
The Locutive Introducer unit (INT) has the function of introducing a meta-illocution, with the most frequent corresponding to reported speech, as with those below in examples (26) and (27). The Locutive Introducer signals that whatever follows does not have to be taken as belonging to the same hic et nunc as the rest of the utterance. In particular the illocutions represented in the reported speech are not active in the present context and must be interpreted like a theatrical mimesis of forces. The unit’s linguistic fulfillment is often achieved by way of verbs, proper names, and formulae (cf. Giani 2005) and it is performed by way of an introducer unit, which bears no prosodic prominence. Its overall form is brief and descending, and it is characterized by a clear separation from the next prosodic unit, which is usually denoted by a jump to a higher f0 level. Almost always it records a marked increase in speech rate.
| (26) | *TOC: I said /INT this is terribly awkward //COM-r I’ve just been promoted /COB_rfrom third mate /CMM_r to second mate /CMM_r22 |
| %ill: reported speech (stanza) [afamcv03] |
| (27) | *LYN: and then like /INT I would never /SCA_r ever /SCA_r ever /SCA_r trust myself /SCA_r to shoe a horse //COM_r |
| %ill: reported speech [afammn01] |
From a distributional point of view, an Introducer may precede a sequence of information units, composing a reported speech or a spoken thought, as in the Italian example (28), corresponding to a new Information Pattern.
| (28) | *JHO: vale a dire /INTse io dovessi accettare /TOP-r perdo il personaggio //COM-r |
| ‘it means / if I had to accept / I’ll lose my role’ [ifamcv07] | |
| %ill: spoken thought |
Audio files show the un-interpretability of isolated Introducers, while the introduced Information Pattern is recognizable in accomplishing a form of imitation. For the syntactic relation between the Introducer and the introduced Pattern the latter is not a completive subordinate but instead a kind of combination between separate islands (cf. Banfield 1982: 25, passim).
Dialogic Units (DU) are defined as information units that do not contribute to the semantic content of the utterance and have functions that regulate the communication. They may be directed towards an addressee or otherwise connect utterances across turns or inside turns, even connecting information units inside an utterance (Frosali 2006). So far, six different types of DUs have been identified: Phatic (PHA), Incipit (INP), Conative (CNT), Allocutive (ALL), Expressive (EXP) and Discourse Connector (DCT). Each one has its own specific function, prosodic properties, distribution, and lexical correlates (Moneglia/Cresti 2015: 121–124).
Their functions can be summarized as follows:
| · | The Incipit opens the communicative channel, bearing a contrastive value and starting a dialogic turn or an utterance. |
| · | The Conative encourages the listener to take part in the Dialogue, or tries to stop his un-collaborative behavior. |
| · | The Phatic controls the communicative channel and maintains it. It stimulates the listener toward social cohesion. |
| · | The Allocutive specifies to whom the message is directed, holding his attention and forming a cohesive, empathic function. |
| · | The Expressive functions as an emotional support, stressing the sharing of a social affiliation. |
| · | The Discourse Connector joins different parts of the discourse together, indicating its continuation. |
Some examples of Dialogic Units can be found in the previous examples such as the Phatic in (7) and in (21), and a Discourse Connector and an Expressive in (23), but it is beyond this paper’s scope to report individual examples for Dialogical Units and to discuss their details. In any case, it may be noted that the linguistic fulfillment of each Dialogic Unit is non-compositional with respect to the rest of the utterance and it behaves like an island within the utterance combination.
The aim of this paper was to demonstrate the pragmatic foundation of the utterance and of its information structure and to closely connect the role of prosody in their identification. The ideas were presented in accordance with the L-AcT framework. A necessary premise to the work is that the question of the identification of the proper reference unit for speech may not be circumvented and our hypothesis is that the utterance’s demarcated prosody in the flow of speech, accomplishing an illocutionary act, is this unit. Moreover, it cannot be disregarded that the reference unit is an adequate and useful means of analyzing large spoken corpora. The L-AcT approach has been applied in the systematic tagging and investigation of representative corpora for Romance languages and English. For the information structure we propose that the Comment unit is the core of the Information Pattern and that since it is dedicated to the expression of the illocution it is automatically the source of new information. Furthermore, the next pragmatic choice of a speaker is always unpredictable. The Comment may be accompanied and supported by other optional information units which are functionally differentiated, thus composing an Information Pattern which is demarcated by a prosodic Pattern in an isomorphic trend. Generally speaking, syntax is dependent on information structure and compositionality applies only within prosodic boundaries, leading to a combination of local syntactic islands bound by pragmatic functions within the utterance.
Abeillé, Anne (ed.) (2003): Treebanks Building and Using Parsed Corpora. Dordrecht: Kluwer Academic.
Amir, Noam/Silber-Varod, Vered/Izre’el, Shlomo (2004): “Characteristics of Intonation Unit Boundaries in Spontaneous Spoken Hebrew: Perception and Acoustic Correlates”. In: Bel, Bernard/Marlien, Isabelle (eds.): Proceedings of Speech Prosody 2004, Nara, Japan, March 23–26. Nara, SProSIG: 677–680.
Arbib, Michael (2012): How the Brain Got Language. Oxford: Oxford University Press.
Austin, John Langshaw (1962): How to Do Things with Words. Oxford: Oxford University Press.
Averintseva-Klisch, Maria (2008): “German right dislocation and afterthought in discourse”. In: Benz, Anton/Kühnlein, Peter (eds.): Constraints in Discourse. Amsterdam, Benjamins: 225–247.
Banfield, Ann (1982): Unspeakable Sentences: Narration and Representation in the Language of Fiction. Boston/London/Melbourne: Routledge and Kegan Paul.
Barth-Weingarten, Dagmar/Reber, Elisabeth/Selting, Margret (eds.) (2010): Prosody in Interaction. Amsterdam: Benjamins.
Biber, Douglas et al. (1999): The Longman Grammar of Spoken and Written English. London: Longman.
Blanche-Benveniste, Claire et al. (1990): Le Français Parlé: Études Grammaticales. Paris: Éditions du C.N.R.S.
Blanche-Benveniste, Claire (1997): Approches de la Langue Parlée en Français. Paris: Ophrys.
Blanche-Benveniste, Claire (2003): « Le recrouvement de la Syntaxe et de la macro-syntaxe ». In: Scarano, Antonietta (ed.): Macro-syntaxe et pragmatique. Roma, Bulzoni: 53–75.
Buhmann, Jeska et al. (2002): “Annotation of Prominent Words, Prosodic Boundaries, and Segmental Lengthening by no-Expert Transcribers in the Spoken Dutch Corpus”. In: Rodriguez, Manuel Gonzales/Suarez Araujo, Carmen (eds.): Proceedings of the International Conference (LREC’ 02). Paris, ELRA: 779–785.
Cavalcante, Frederico Amorim/Ramos, Adriana (2016): “The American English spontaneous speech minicorpus. Architecture and comparability”. CHIMERA. Romance Corpora and Linguistic Studies 3/2: 99–124.
Chafe, Wallace (1970): Meaning and the Structure of Language. Chicago: University of Chicago Press.
Chafe, Wallace (1976): “Givenness, Contrastiveness, Definiteness, Subjects, Topics, and Point of View”. In: Li, Charles N. (ed.): Subject and Topic. New York, Academic Press: 25–55.
Cheng, Winnie/Greaves, Chris/Warren, Martin (2005): A Corpus-driven Study of Discourse Intonation: The Hong Kong Corpus of Spoken English. Amsterdam/Philadelphia: Benjamins.
Couper-Kuhlen, Elizabeth (2004): “Prosody and Sequence Organizations in English Conversation: The Case of New Beginnings”. In: Couper-Kuhlen, Elizabeth/Ford, Cecilia E. (eds.): Sound Patterns in Interaction. Amsterdam, Benjamins: 335–376.
Cresti, Emanuela (2000): Corpus di italiano parlato. Firenze: Accademia della Crusca.
Cresti, Emanuela (2005): «Per una nuova classificazione dell’illocuzione a partire da un corpus di parlato (LABLITA)». In: Burr, Elisabeth (ed.): Tradizione e innovazione: il parlato. Atti del VI Convegno internazionale SILFI (giugno 2000, Duisburg). Pisa, Cesati: 233–246.
Cresti, Emanuela (2006): “Some Comparisons between UBLI and C-ORAL-ROM”. In: Kawaguchi, Yuji/Zaima, Susumu/Takagaki, Toshiro (eds.): Spoken Language Corpus and Linguistics Informatics. Amsterdam, Benjamins: 125–152.
Cresti, Emanuela (2010): «La Stanza: un’unità di costruzione testuale del parlato». In: Ferrari, Angela (ed.): Sintassi storica e sincronica dell’italiano. Subordinazione, coordinazione e giustapposizione. Atti del X Congresso della Società Internazionale di Linguistica e Filologia Italiana, (Basilea, 30 giugno-3 luglio 2008). Firenze, Cesati: 713–732.
Cresti, Emanuela (2012a): “The Definition of Focus in the Framework of the Language into Act Theory (L-AcT)”. In: Panunzi, Alessandro/Raso, Tommaso/Mello, Heliana (eds.): Pragmatics and Prosody. Illocution, Modality, Attitude, Information Patterning and Speech Annotation. Firenze, Firenze University Press: 39–82.
Cresti, Emanuela (2012b): « L’unité de suffixe: identification et interprétation des unités de la langue parlé ». In: Caddéo, Sandrine et al. (eds.): Penser les langues avec Claire Blanche-Benveniste. Aix-en-Provence, Presses Universitaires de Provence: 201–213.
Cresti, Emanuela (2014): “Syntactic properties of spontaneous speech in the Language into Act Theory: data on Italian complements and relative clauses”. In: Raso, Tommaso/Mello, Heliana (eds.): Spoken corpora and linguistics studies. Amsterdam, Benjamin: 365–410.
Cresti, Emanuela (2016): «Dalla struttura informativa (alla prosodia) alla sintassi: dati sulla subordinazione nell’italiano parlato». In: Elia, Annibale/Iacobini, Claudio/Voghera, Miriam (eds.): Livelli di Analisi e Fenomeni di Interfaccia. Atti del LXVII Congresso Internazionale SLI. Roma, Bulzoni: 53–73.
Cresti, Emanuela (forthcoming a): «Per una classificazione empirica dell’illocuzione. Lo stato dell’arte». In: Biffi, Marco/Cialdini, Francesca/Setti, Raffaella (eds.): «Acciò che’l nostro dire sia ben chiaro» Scritti per Nicoletta Maraschio. Firenze, Accademia della Crusca.
Cresti, Emanuela (forthcoming b): “The Empirical Foundation of Illocutionary Classification”. In: De Meo, Anna/Dovetto, Francesca (eds.): Atti del Convegno internazionale GSCP, La comunicazione parlata, 13–15 giugno 2016. Università Federico II, Napoli.
Cresti, Emanuela/Firenzuoli, Valentina (1999): « Illocution et profils intonatifs de l’italien ». Revue française de linguistique appliquèe IV/2: 77–98.
Cresti, Emanuela/Moneglia, Massimo/Martin, Philippe (2003): « L’intonation des illocutions naturelles répresentatives: analyse et validation perceptive ». In: Scarano, Antonietta (ed.): Macrosyntaxe et pragmatique: l’analyse linguistique del’oral. Roma, Bulzoni: 243–264.
Cresti, Emanuela/Moneglia, Massimo (eds.) (2005): C-ORAL-ROM. Integrated reference corpora for spoken romance languages. DVD + Vol. Amsterdam: Benjamins.
Cresti, Emanuela/Moneglia, Massimo (2010): “The Informational Patterning Theory and the Corpus-based Description of Spoken Language. The Compositional Issue in Topic-Comment Pattern”. In: Moneglia, Massimo/Panunzi, Alessandro (eds.): Proceedings of 3rd International LABLITA Work-Shop in Corpus Linguistics. Bootstrapping Information From Corpora in a Cross Linguistic Perspective. Firenze, Firenze University Press: 13–46.
Cresti, Emanuela/Moneglia, Massimo/Tucci, Ida (2011): « Annotation de ‹ Anita Musso › selon la Théorie de langue en acte ». Langue Française 170: 95–110.
Cresti, Emanuela/Moneglia, Massimo/Panunzi, Alessandro (forthcoming): “The LABLITA Corpus & the Language into Act Theory: Analysis of Viterbo Excerpts”. In: De Dominicis, Amedeo (ed.): Atti del Convegno Internazionale « Speech Audio Archives: Preservation, Restoration, Annotation, Aimed at Supporting the Linguistic Analysis». Accademia dei Lincei (18–19 maggio 2017).
Cruttenden, Alan (1997): Intonation. 2nd ed. Cambridge: Cambridge University Press.
Crystal, David (1975): The English Tone of Voice. London: Arnold.
Danieli, Morena et al. (2004): “Evaluation of Consensus on the Annotation of Prosodic Breaks in the Romance Corpus of Spontaneous Speech C-ORAL-ROM”. In: Draxler, Christoph/van den Heuvel, Henk/Schiel, Florian (eds.): Speech Corpus Production and Validation. LREC 2004: Fourth International Conference on Language Resources and Evaluation, 24th May, 2004. Lisbon, ELRA: 1513–1516.
Dehé, Nicole (2014): Parentheticals in Spoken English: The Syntax-Prosody Relation. Cambridge: Cambridge University Press.
Du Bois, John W. (1992): “Discourse Transcription”. Santa Barbara Papers in Linguistics 4: 1–225.
Du Bois, John W. (2004): Representing Discourse. Part 2: Appendices and Projects. Santa Barbara: Linguistics Department, University of California.
Egorova, Natalia/Shtyrov, Yury/Pulvermüller, Friedemann (2013): “Early and Parallel Processing of Pragmatic and Semantic Information in Speech Acts: Neurophysiological Evidence”. Frontier in Human Neurosciences 86/7: 1–13.
Egorova, Natalia/Shtyrov, Yury/Pulvermüller, Friedemann (2015): “Brain Basis of Communicative Actions in Language”. NeuroImage 125: 857–867.
Fagioli, Massimo (2010): Istinto di morte e conoscenza. Roma: L’Asino d’oro.
Fagioli, Massimo (2011): Todestriebe und Erkenntnis. Frankfurt: Stroemfeld.
Fagioli, Massimo (2012): Teoria della nascita e castrazione umana. Roma: L’Asino d’oro.
Firenzuoli, Valentina (2000): «Nuovi dati statistici sull’italiano parlato». Romanische Forschungen 13: 213–225.
Firenzuoli, Valentina (2003): Le Forme Intonative di Valore Illocutivo dell’Italiano Parlato: Analisi Sperimentale di un Corpus di Parlato Spontaneo (LABLITA). Unpublished PhD Thesis, Università di Firenze.
Fox, Anthony (2000): Prosodic Features and Prosodic Structure: The Phonology of Suprasegmentals. Oxford: Oxford University Press.
Frosali, Fabrizio (2008): «Il Lessico degli ausili dialogici». In: Cresti, Emanuela (ed.): Prospettive nello studio del lessico italiano. Atti del IX Congresso della Società Internazionale di Linguistica e Filologia Italiana. Firenze, FUP: 417–424.
Gatti, Maria Gabriella et al. (2012): “Functional Maturation of Neocortex: A Base of Viability”. Journal Matern Fetal Neonatal 25/1: 101–103.
Giani, Daniela (2005): Il discorso riportato nell’italiano parlato e letterario: confronto tra due corpora. Unpublished PhD Thesis, Università di Firenze.
Hart, Johan/Collier, René/Cohen, Antonie (1990): A Perceptual Study on Intonation. An Experimental Approach to Speech Melody. Cambridge: Cambridge University Press.
Hirst, Daniel/Di Cristo, Albert (1998): “A Survey of Intonation Systems”. In: Hirst, Daniel/Di Cristo, Albert (eds.): Intonation Systems: A Survey of Twenty Languages. Cambridge, Cambridge University Press: 1–43.
Hockett, Charles F. (1958): A Course in Modern Linguistics. New York: The Macmillan Company.
Izre’el, Shlomo/Hary, Benjamin/Rahav, Giora (2001): “Designing CoSIH: The Corpus of Spoken Israeli Hebrew”. International Journal of Corpus Linguistics 6/2: 171–197.
Izre’el, Shlomo (2005): “Intonation Units and the Structure of Spontaneous Spoken Language: A View from Hebrew”. In: Auran, Cyril et al. (eds.): Proceedings of the IDP05 International Symposium on Discourse-Prosody Interfaces. Aix-en-Provence, Université de Provence.
Izre’el, Shlomo/Mettouchi Amina (2015): “Representation of Speech in CorpAfroAs. Transcriptional Strategies and Prosodic Units”. In: Mettouchi, Amina/Vanhove, Martine/Caubet, Dominique (eds.): Corpus-based Studies of Lesser-described Languages: The CorpAfroAs Corpus of Cpoken AfroAsiatic Languages. Amsterdam/Philadelphia, Benjamins: 13–41.
Karcevsky, Serge (1931): « Sur la phonologie de la phrase ». Travaux du Cercle linguistique de Prague IV: 188–228. [Reprint in Karcevski, Serge (2000). Inédits et introuvables. Textes rassemblés et établis par I. et G. Fougeron. Louvain: Peeters. (= Collection linguistique de la Société de linguistique de Paris 80).].
Kempson, Ruth M. (1977): Semantic Theory. Cambridge: Cambridge University Press.
Krifka, Manfred (2007): “Basic Notions of Information Structure”. In: Féry, Caroline/Fanselow, Gisbert/Krifka, Manfred (eds.): Interdisciplinary Studies of Information Structure 6. Potsdam, Universitätsverlag: 13–55.
Krifka, Manfred/Musan, Renate (eds.) (2012): The Expression of Information Structure. Berlin/Boston: Mouton de Gruyter.
Maccari, Stefania et al. (2016): “Early-life experiences and the development of adult diseases with a focus on mental illness: The Human Birth”. Neuroscience 342: 232–251. doi: 10.1016/j.neuroscience.2016.05.042.
MacWhinney, Brian (2000): The CHILDES Project: Tools for Analyzing Talk. 3rd ed. Mahwah: Lawrence Erlbaum Associates.
Martin, Philippe (2015): The Structure of Spoken Language. Intonation in Romance. Cambridge: Cambridge University Press.
Miller, Jim/Weinert, Regina (1998): Spontaneous Spoken Language. Oxford: Clarendon.
Mittmann, Maryualê Malvessi (2012): O C-ORAL-BRASIL e o estudo da fala informal: um novo olhar sobre o Tópico no Português Brasileiro. Unpublished PhD Thesis, Universidade Federal de Minas Gerais.
Mollo, Giovanna/Pulvermüller, Friedemann/Hauk, Olaf (2016): “Movement Priming of EEG/MEG Brain Responses for Action-words Characterizes the Link between Language and Action”. Cortex 74: 262–276.
Moneglia, Massimo (2006): “Units of Analysis of Spontaneous Speech and Speech Variation in a Cross-linguistic Perspective”. In: Kawaguchi, Yuji/Zaima, Susumu/Takagaki, Toshiro (eds.): Spoken Language Corpus and Linguistics Informatics. Amsterdam, Benjamins: 153–179.
Moneglia, Massimo (2011): “Spoken Corpora and Pragmatics”. Revista Brasileira de Linguìstica Aplìcada 11/2: 479–519.
Moneglia, Massimo/Cresti, Emanuela (1997): «L’intonazione e i criteri di trascrizione del parlato adulto e infantile». In: Bortolini, Umberta/Pizzuto, Elena (eds.): Il Progetto CHILDES Italia. Pisa, Del Cerro: 57–90.
Moneglia, Massimo/Cresti, Emanuela (2006): “C-ORAL-ROM Prosodic Boundaries for Spontaneous Speech Analysis”. In: Kawaguchi, Yuji/Zaima, Susumu/Takagaki, Toshiro (eds.): Spoken Language Corpus and Linguistics Informatics. Amsterdam, Benjamins: 89–114.
Moneglia, Massimo/Cresti, Emanuela (2015): “The Cross-linguistic Comparison of Information Patterning in Spontaneous Speech Corpora: Data from C-ORAL-ROM ITALIAN and C-ORAL-BRASIL”. In: Klaeger, Sabine/Thörle, Bitta (eds.): Interactional Linguistics: Grammar and Interaction in Romance Languages from a Contrasting Point of View. Tübingen, Stauffenburg: 107–128.
Moneglia, Massimo/Raso, Tommaso (2014): “Notes on the Language into Act Theory”. In: Raso, Tommaso/Mello, Heliana (eds.): Spok en Corpora and Linguistics Studies. Amsterdam, Benjamins: 468–494.
Moneglia, Massimo et al. (2010): “Challenging the Perceptual Prominence of Prosodic Breaks in Multilingual Spontaneous Speech Corpora: C-ORAL-ROM/C-ORAL-BRASIL”. In: Speech Prosody 2010. Chicago.
Moneglia, Massimo/Scarano, Antonietta (2006): «Il Corpus Stammerjohann. Il primo corpus di italiano parlato, in rete nella base dati di LABLITA». In: Pettorino, Massimo et al. (eds.): La comunicazione parlata. Tomo I. Napoli, Liguori: 1699–1734.
Montemagni, Simonetta et al. (2003): “Building the Italian syntactic-semantic treebank”. In: Abeillé, Anne (ed.): Treebanks Building and Using Parsed Corpora. Dordrecht, Kluwer Academic: 189–210.
Nicolas Martinez, Carlota (2012): Cor-DiAL, (Corpus oral didáctico anotado lingüísticamente). Madrid: Liceus.
Panunzi, Alessandro/Gregori, Lorenzo (2012): “DB-IPIC. AN XML Database for the Representation of Information Structure in Spoken Language”. In: Mello, Heliana/Panunzi, Alessandro/Raso, Tommaso (eds.): Pragmatics and Prosody. Illocution, Modality, Attitude, Information Patterning and Speech Annotation. Firenze, Firenze University Press: 133–150.
Panunzi, Alessandro/Mittmann, Maryualê Malvessi (2014): “The IPIC resource and a cross-linguistic analysis of information structure in Italian and Brazilian Portuguese”. In: Raso, Tommaso/Mello, Heliana (eds.): Spoken corpora and Linguistic Studies. Amsterdam, Benjamins: 129–151.
Pons Borderia, Salvador (2008): “Do Discourse Marker exist? On the treatment of Discourse Markers in Relevance Theory”. Journal of Pragmatics 40: 1411–1434
Pulvermüller, Friedemann (2001): “Brain Reflections of Words and their Meaning”. Trends in Cognitive Sciences 5: 517–524.
Pulvermüller, Friedemann/Fadiga, Luciano (2010): “Active Perception: Sensorimotor Circuits as a Cortical Basis for Language”. Natural Review of Neurosciences 11: 351–360.
Pulvermüller, Friedemann et al. (2014): “Motor Cognition-motor Semantics: Action Perception Theory of Cognition and Communication”. Neuropsychologia 55: 71–84.
Pulvermüller, Friedemann/Shtyrov, Yury/Hauk, Olaf (2009): “Understanding in an Instant: Neurophysiological Evidence for Mechanistic Language Circuits in the Brain”. Brain Language 110: 81–94.
Quirk, Randolph et al. (1985): A Comprehensive Grammar of the English Language. London/New York: Longman.
Raso Tommaso (2014): “Prosodic Constraints for Discourse Markers”. In: Raso, Tommaso/Mello, Heliana (eds.): Spoken Corpora and Linguistic Studies. Amsterdam, Benjamins: 411–467.
Raso, Tommaso/Mello, Heliana (eds.) (2012): C-ORAL-BRASIL I: Corpus de referência de português brasileiro falado informal. Belo Horizonte: Universidade Federal de Minas Gerais.
Rocha, Bruno (2016): Uma metodologia empírica para a identificação e descrição de ilocuções e a sua aplicação para o estudo da Ordem em PB e Italiano. Unpublished PhD Thesis. Universidade Federal de Minas Gerais.
Sacks, Harvey/Schegloff, Emanuel A./Jefferson, Gail (1974): “A Simplest Systematics for the Organization of Turn-taking for Conversation”. Language 50: 696–735.
Sbisà, Marina/Turner, Ken (2013): “Introduction”. In: Sbisà, Marina/Turner, Ken (eds.): Pragmatics of Speech Actions. Berlin, Mouton de Gruyter: 1–5.
Scarano, Antonietta (2003): « Les constructions de syntaxe segmentée: Syntaxe, macro-syntaxe et articulation de l’information ». In: Scarano Antonietta (ed.): Macrosyntaxe et Pragmatique: l’analyse de la langue orale. Roma, Bulzoni: 183–202.
Scarano, Antonietta (2009): “The Prosodic Annotation of C-ORAL-ROM and the Structure of Information in Spoken Language”. In: Mereu, Lunella (ed.): Information Structures and its Interfaces. Berlin, Mouton de Gruyter: 51–74.
Schegloff, Emanuel A. (1986): “Turn Organization: One Intersection of Grammar and Interaction”. In: Ochs, Elinor/Schegloff, Emanuel A./Thompson, Sandra (eds.): Interaction and Grammar. Cambridge, Cambridge University Press: 52–133.
Schegloff, Emanuel A. (2007): Sequence Organization in Interaction. A Primer in Conversation Analysis. Cambridge: Cambridge University Press.
Schiffrin, Deborah (1987): Discourse Markers. Cambridge: Cambridge University Press.
Searle, John (1966): Speech Acts. An Essay in the Philosophy of Language. Cambridge: Cambridge University Press.
Searle, John/Vanderveken, Daniel (1985): Foundations of Illocutionary Logic. Cambridge: Cambridge University Press.
Selting, Margret (2010): “Prosody in interaction: State of the art”. In: Barth-Weingarten, Dagmar/Reber, Elisabeth/Selting, Margret (eds.): Prosody in Interaction. Amsterdam, Benjamins: 3–40.
Signorini, Sabrina (2005): Topic e soggetto in corpora di italiano parlato. Unpublished PhD Thesis, University of Florence.
Sorianello, Patrizia (2006): «Per una definizione fonetica dei confini prosodici». In: Pettorino, Massimo/Giannini, Antonella/Savy, Renata (eds.): Atti del Convegno Internazionale, La comunicazione parlata. Napoli, Liguori: 310–330.
Sorianello, Patrizia (2006a): Prosodia. Modelli e ricerca empirica. Roma, Carocci.
Szczepek Reed, Beatrice (2010): “Intonation phrases in natural conversation: A participant’s category?”. In: Barth-Weingarten, Dagmar/Reber, Elisabeth/Selting, Margret (eds.): Prosody in Interaction. Amsterdam, Benjamins: 191–213.
Swerts, Mark (1997): “Prosodic features at discourse boundaries of different strength”. Journal of the Acoustical Society of America 101: 514–521.
Swerts, Mark/Geluykens, Ronald (1993): “The prosody of information units in spontaneous monologues”. Phonetica 50: 189: 196.
Tucci, Ida (2004): «L’inciso: caratteristiche morfosintattiche e intonative in un corpus di riferimento». In: Albano Leoni et al. (eds.): Il parlato italiano, Atti del Convegno Nazionale GSCP. Napoli, D’Auria: 1–14.
Tucci, Ida (2009): “The Scope of Lexical Modality and the Informational Structure in Spoken Italian”. In: Mereu, Lunella (ed.): Information Structure and Its Interfaces. Berlin/New York, Mouton de Gruyter: 203–226.
Tucci, Ida (2010): «Obiter dictum. La funzione informativa delle unità parentetiche». In: Pettorino, Massimo/Giannini, Antonella/Dovetto, Francesca (eds.): Atti del Convegno Internazionale GSCP « La Comunicazione parlata». Napoli, Università l’Orientale Press: 635–654.
Wichmann, Anne (2000): Intonation in Text and Discourse: Beginnings, M iddles and Ends. Harlow: Pearson Education.
1 A different line of research known as Interactionism must also be mentioned (cf. Couper-Kuhlen 2004; Bart-Weingarten et al. 2010), which chooses the dialogic turn as the natural unit of speech. It would appear that this kind of entity could solve the question of the actual identification of the reference unit, given the easy way in which the turn may be identified in speech flow depending on the speakers’ change of voice. However, given the difference in the linguistic contents of the turns this choice produces other relevant questions. Interactional researchers (Selting 2010: 7, passim; Szczepek Reed 2010: 201, passim) propose kinds of sub-turn to overcome this difficulty, according to the Schegloff’s tradition (cf. Sacks et al. 1974; Schegloff 1986, 2007), but these entities end up practically coinciding with the clause. back
2 Also A Comprehensive Grammar of the English Language (Quirk et al. 1985: 485, 590, passim) indirectly refers to this concept. back
3 C-ORAL-ROM is the primary result of an EU project in the IST program of the 5th Framework Program (IST2000-26228). The C-ORAL-ROM resource is distributed by Benjamin Publishing Company for personal use and distributed for Laboratories and Industry by The Evaluations and Language resources Distribution Agency (ELDA). back
4 C-ORAL-BRASIL is a collection of texts recorded (2006–2010) in the Minas Gerais metropolitan district (Universidade Federal de Minas Gerais) according to the same sampling criteria as C-ORAL-ROM and focusing on the informal variation (362 recorded speakers, 139 spoken texts, 21:08:52 hours of speech, 209’000 words, Raso/Mello 2012). back
5 Note that none of the previous cues for prosodic boundaries is in itself necessary or sufficient for the existence of a terminal boundary and that languages may differ in their most prominent cues for boundary delimitation (cf. Hirst/Di Cristo 1998). back
6 Nowadays, the perceptual detection of utterance boundaries is widely employed in typological studies which have started to collect spontaneous spoken corpora from many language families. In 2015, within the IX LABLITA and IV LEEL International Workshop held in Belo Horizonte, the prosodic detection principle was applied by 10 expert teams to Romance languages (French, Italian, Brazilian Portuguese), English, Russian, Hebrew, Japanese, and to Amerindian languages. Furthermore, within the ISSLaC2 workshop in Paris – dedicated to Afro-Asiatic languages and more generally to lesser-known or endangered languages – the majority of the corpus collection was carried out in accordance with the same methodology (cf. Izre’el/Mettouchi 2015). back
7 L-AcT developed an open repertory of nearly 90 illocutionary types which are classified into 5 general classes, each organized into different sub-classes based on pragmatic features. Their details are beyond the scope of this paper (cf. Cresti 2005: 240; forthcoming a; forthcoming b). back
8 Prosody is the necessary means of transmitting the pragmatic conception in a concrete and audible entity, and prosodic units are not, consequently, a kind of superficial execution of deep syntactic structures as the generative tradition claims, but, on the contrary, determine the boundaries of syntactic islands (cf. Cresti 2014: 370). Examples are shown in subsequent paragraphs. back
9 We refer in particular to the research carried out at the Brain Language Unit of the Freie Universitat of Berlin, coordinated by Pulvermüller (cf. Pulvermüller 2001; Pulvermüller et al. 2009; Pulvermüller/Fadiga 2010; Pulvermüller et al. 2014). back
10 See paragraphs 6 and 7 for more details. back
11 Examples are taken from the LABLITA corpora and Data Base (see paragraph 2). As it has been anticipated, the information structure of these corpora has been systematically annotated in DB-IPIC, based on an explicit tag set and annotation specification. Therefore, examples can be considered prototypes supported by a large data set. Quantitative data can be found in the literature cited in the paper. On the contrary, the assignment of the illocutionary type to the examples derives from a corpus driven research which is the basis for large campaign of illocutionary annotation in spoken corpora, following theoretical criteria and a working procedure of analysis (cf. Cresti forthcoming b). back
12 The simple numbering system: (1), (2), etc. is used for utterances tagged with their prosodic breaks, the acronym for the speaker, the information tags etc. Conversely, the bare transcription, or the partial transcription, or any other transformation of an utterance is indicated with a number followed by a letter: (1a), (2a), etc. back
13 Our transcription method is a version of the CHAT format (cf. MacWhinney 2000) combined with the tagging of terminal and non-terminal prosodic breaks (cf. Moneglia/Cresti 1997). The transcriptions are orthographic, capital letters are employed only for proper names. Speakers are identified by an asterisk and three capital letters, followed by a colon and one space; each dialogic turn is introduced by the acronym of the speaker and continues until he is silent. Each utterance and each information unit are followed by a space and, respectively, a double or single slash (//, /). A slash is given its information tag using three capital letters in superscript (COM, TOP, APC, etc.) (see paragraph 7 for details). In a dependent layer, preceded by the percentage sign, there may be different kinds of information, concerning for instance the situation, the lexicon (%sit, %lex), and specifically the illocutionary type (%ill). Other transcription conventions regard the ‘&’ character as symbolizing a word fragment and ‘+’ as symbolizing an interrupted utterance. The [/] and [//] symbols represent phenomena of retraction, such as repetition and reformulation and are followed by the superscript EMP. Overlaps are indicated with angular parentheses (<word>). Examples are accompanied by a sequence of 5 letters plus a number, and the whole id enclosed in square parenthesis, indicating the source file in the corpus. The file of English examples is that of a selected and annotated mini-corpus made by LEEL team under the direction of Raso (cf. Cavalcante/Ramos 2016). back
14 The second utterance in (1) is parsed into two units: the first is tagged with SCA in superscript, signalizing an emphatic f0 movement on life, but which does not change the functional value of the final Comment unit. Each information unit is performed, necessarily, by an adequate prosodic unit (see paragraph 7). However the expression of an information function may require a long stretch of speech, especially in the formal register. Given that a prosodic unit must respect severe limits of duration and syllabic length and not surpass a canonical size of seven syllables (cf. Martin 2015: 114–121; Miller/Weinert 1998: 79–80), in the case of a long linguistic chunk the information function is realized through a strategy of prosodic parsing. Only the last parsed unit is characterized by the proper acoustic cues of its prosodic type, since the previous one(s) just carries the locution expressing the same information function. When tagged, prosodic units within the same information unit – excluding the last one – are marked by the SCA acronym and the last one is tagged with the actual information unit type. In such cases the locutive content of the different SCA prosodic units is fully compositional with regard to its syntactic value. back
15 The Romance C-ORAL-ROM data record a frequency of nearly 35 % for verbless utterances, excluding the case of French. back
16 The acronym CMM replaces the term multiple comments. One single Information Pattern (see paragraph 6) may correspond to a chain of two or more Comments which form a kind of natural rhetoric figure (Illocutionary Pattern). The most common of these is the reinforcement pattern, composed of a doubling of the illocution; otherwise there are comparison and alternation patterns, as well as a chain of three or more Comments which make up a list. According to the IPIC DB, for 21’007 terminated sequences 7.80 % are Illocutionary Patterns. back
17 It may be observed how the illocutionary tagging of dialogue exchange in (6) and (7) evidences the richness of the illocutionary types used by the speakers, their continuous variation, and, as a consequence, their unpredictability. back
18 See paragraph 7 for the functions and definitions of these information units. back
19 (12) represents an interesting example showing why the new information is always the speaker’s affective/pragmatic reaction, expressed by the Comment. It also demonstrates how it is incorrect to assume that it depends on the Common Ground. back
20 The acronym i-COM and all tags preceded by i- (lowercase ‘i’ followed by a hyphen) replace the term interrupted with a Parenthesis unit or by time-taking. back
21 The acronym COB replaces the term bound comment. It is employed to mark a stanza, which is a sequence of Comments with weak illocutionary forces, typically composed on the fly. A stanza corresponds to an un-patterned sequence (cf. Cresti 2000: 160–162; Cresti 2010). According to the IPIC DB, Stanzas correspond to 9.48 % of 21’007 terminated sequences. back
22 The acronym COM-r and all tags followed by a hyphen and a lowercase r replace the term reported and are employed to denote information units composing a reported Information Pattern. back