Die Tatsache, dass das Deutsche im Vergleich zum Englischen als nominaler und komplexer in seiner Phrasenstruktur gilt, wird hinreichend in der Literatur postuliert. Die gleiche Merkmalskombination trifft allerdings auch auf Fachkommunikation im Vergleich zur Gemeinsprache zu. Dieser Artikel widmet sich der quantitativen Ausprägung dieser Merkmale in englischen und deutschen Fachtexten. Eine interessante Frage in diesem Kontext ist darüber hinaus, ob sich diese Unterschiede auch in deutsch-englischen Übersetzungen widerspiegeln. Die Vermutung liegt nahe, dass in englischen Übersetzungen z. B. die Phrasenstruktur der deutschen Originale "durchscheint" und umgekehrt. Somit wären englische Übersetzungen in Bezug auf ihre Phrasenstruktur nominaler und komplexer, als englische Originale, wohingegen deutsche Übersetzungen verbaler und weniger komplex in ihrer Phrasenstruktur wären als deutsche Originale. Falls sich diese Hypothesen bestätigen lassen, könnten hier Indikatoren für Sprachwandel durch Übersetzung zu beobachten sein, da die Rezeption der Übersetzungen die Wahrnehmung in der Zielsprache beeinflusst.
Der vorliegende Beitrag widmet sich genau diesen Fragestellungen. Nach einer kurzen Beschreibung der deutschen und englischen Fachkommunikation, wird das dieser Untersuchung zugrundeliegende multidimensionale Korpusdesign vorgestellt, um anschließend die Ergebnisse und Interpretationen in Bezug auf die Nominalphrasenkomplexität der untersuchten Korpora vorzustellen.
Fachsprachen gliedern sich nicht nur in eine horizontale Schichtungsebene (entsprechend der verschiedenen Fächer), sondern auch in eine vertikale Schichtungsebene. Hierbei wird zwischen fachinterner und fachexterner Kommunikation unterschieden. Letztere gliedert sich in didaktisierende, popularisierende und verhaltenssteuernde Fachtextsorten (cf. Gläser 1990). Heutzutage scheinen insbesondere populärwissenschaftliche Texte ein gängiges Mittel zu sein, der Öffentlichkeit Zugang zu wissenschaftlichen Inhalten zu ermöglichen. Diese Art der popularisierenden Kommunikation forderte bereits Altbundeskanzler Helmut Schmidt (1975) mit der "Bringschuld der Wissenschaft", Theorien, Modelle und Ergebnisse dem Laien zu vermitteln und der gesellschaftlichen Verantwortung, die mit Forschung und Wissenschaft einhergeht nachzukommen.1
Nun stellt sich die Frage, ob populärwissenschaftliche Texte auch wirklich verständlicher sind als Wissenschaftsdiskurs. Diese Frage wird auch von der sprachwissenschaftlichen Forschung aufgegriffen, jedoch basieren diese Studien sowie Untersuchungen, die sich dem Wissenschaftsjournalismus widmen, vorwiegend auf der Diskussion von Beispielen bzw. sind durch einen eher normativen Charakter geprägt. Bevor wir nun der empirischen Beantwortung dieser Frage nachgehen, werden im Folgenden kurz die Fachsprachenmerkmale im Deutschen und im Englischen erläutert.
Fachsprachenmerkmale findet man auf allen Sprachebenen: Auf der lexikalischen Ebene ist die Verwendung von Terminologie und Abkürzungen am offensichtlichsten. Fachsprachen zeichnen sich allerdings auch durch einen ausgeprägten Nominalstil aus. Dies beinhaltet die vermehrte Verwendung von Substantiven einerseits, Kompositabildung und Nominalisierungen andererseits. Verben sind typischerweise inhaltsarm und stehen im Präsens. Auf diese Weise versucht man Sachverhalte exakt, ökonomisch und objektiv darzustellen (cf. z. B. Fluck 1997). Auf grammatischer Ebene findet man komplexe Nominalphrasen, Funktionsverbgefüge, komplexe Attribuierung sowie Infinitiv- und Partizipialsätze. Weiterhin erreicht man durch die Verwendung des Passivs eine Entpersönlichung der Sachverhalte (cf. z. B. Beneš 1981). Die Komplexität verschiebt sich von der Satzebene in die Phrasenebene. Dies geht einher mit dem Begriff der grammatischen Metapher (cf. Halliday/Martin 1993). All dies führt zu einer Inhaltsbezogenheit, die sowohl in englischen als auch in deutschen Fachtexten zu finden ist. Es stellt sich die Frage, wie die quantitative Ausprägung dieser Fachsprachenmerkmale im vertikalen und interlingualen Vergleich aussieht. Die Vermutung liegt nahe, dass in populärwissenschaftlichen Texten weniger Fachsprachenmerkmale zu finden sind als im Wissenschaftsdiskurs. Was den Sprachenvergleich angeht, stellt House (1996) fest, dass das Deutsche inhaltsbezogener ist als das Englische, wohingegen das Englische eher adressatenorientiert im Vergleich zum Deutschen ist. Weiterhin ist das Deutsche direkter und expliziter als das Englische. Vor diesem Hintergrund ist es interessant zu untersuchen, ob deutsche Fachtexte noch inhaltsbezogener sind als Englische bzw. ob englische populärwissenschaftliche Texte addressatenorientierter sind als Deutsche und inwiefern sich dies auf die Direktheit und Explizitheit der Texte auswirkt (siehe auch Steiner 2001).
Für Übersetzungen vom Englischen ins Deutsche werden unterschiedliche Phänomene beobachtet: Liegen zwischen der Zielsprache und der Ausgangssprache sprachtypologische Unterschiede vor, müssen diese in der Übersetzung ausgeglichen, "Lücken" geschlossen werden. Dies führt dazu, dass die Übersetzungen den Normen der Zielsprache angepasst werden ('Normalisierung', cf. Baker 1996). In diesem Fall würden die Übersetzungen wie Originale in der Zielsprache rezipiert werden (siehe auch 'overt vs. covert translation', cf. House 1996). Gibt es im Sprachsystem der Zielsprache hingegen ähnliche Realisierungsoptionen wie in der Ausgangssprache, können die ausgangssprachlichen Strukturen in den Übersetzungen erhalten werden, was zu ungewöhnlichen Frequenzeffekten in der Zielsprache führen kann. Allzu wörtlich übersetzte Strukturen können auch zu dem Effekt führen, dass die Ausgangssprache strukturell in der Zielsprache "durchscheint" ('Shining-through', cf. Teich 2003), was Irregularitäten bei der Rezeption dieser Übersetzungen nach sich ziehen könnte. Das gleiche gilt für Fälle, in denen die Übersetzungen zwischen den Normen der Ausgangs- und Zielsprache liegen. Diese Art der Hybridisierung kann ebenfalls zu Besonderheiten bei der Textrezeption führen.
In diesem Kontext lassen sich folgende Hypothesen formulieren:
1. Populärwissenschaftliche Texte weisen weniger Fachsprachenmerkmale auf als Texte aus dem Wissenschaftsdiskurs.
2. Deutsche Fachtexte sind inhaltsbezogener und weniger adressatenorientiert als englische Fachtexte.
3. Vom Englischen ins Deutsche übersetzte Fachtexte weisen fachübersetzungsspezifische Eigenschaften auf.
Diese Hypothesen werden in Kapitel 4 am Beispiel der Nominalphrasenkomplexität getestet. Wie bereits dargelegt, ist die komplexe Nominalphrase und deren Ausprägung im Nominalstil oder der grammatischen Metapher hinreichend in der Fachsprachenliteratur beschrieben worden. Diese Studie soll nun dazu beitragen, statistisch nachweisbare Häufigkeitsverteilungen der komplexen Nominalphrase im Sprachenvergleich und für verschiedene Fachlichkeitsgrade hervorzubringen, so dass typische Sprach- sowie Registermuster nachgewiesen werden können. Wie diese unabhängigen Untersuchungsvariablen (Sprache und Register) durch das Korpusdesign repräsentiert werden, wird im folgenden Kapitel erläutert.
Um die in Kapitel 2 beschriebenen Hypothesen zu testen, wird ein multidimensionales Korpusdesign benötigt. Die Multidimensionalität bezieht sich sowohl auf den Korpusaufbau (Sprach- und Registervergleiche müssen möglich sein) als auch auf die Korpusannotation und -alignierung (grammatische Phänomene sollen empirisch untersucht werden). Dies wird im Folgenden kurz erläutert.
| – | Das Untersuchungskorpus enthält Fachtexte aus dem wirtschaftspolitischen Bereich, popularisierende Zeitungsartikel aus dem Wirtschaftsressort, und ein gemeinsprachliches Referenzkorpus. Die Fachtexte stammen aus dem CroCo-Korpus (cf. Neumann/Hansen-Schirra 2005) – es handelt sich um englische Originale und deutsche Übersetzungen. |
| Das deutsche Zeitungskorpus besteht aus dem Wirtschaftsteil der TiGer-Baumbank (cf. Brants et al. 2004), das englische Zeitungskorpus wurde aus der Penn-Treebank extrahiert (cf. Marcus et al. 1994). Die deutschen Texte sind in der Frankfurter Rundschau, die englischen im Wall Street Journal erschienen. Für beide Sprachen ist davon auszugehen, dass die jeweiligen Zeitungsartikel für ein interessiertes Laienpublikum geschrieben wurden. Hierbei handelt es sich also um Experten-Laien-Kommunikation. | |
| Die englischen und deutschen Referenzkorpora stammen wiederum aus dem CroCo-Korpus und enthalten jeweils 2'000-Wortausschnitte aus 17 Registern. Die heterogene Zusammensetzung dieser Korpora zielt auf einen textsortenneutralen Ausschnitt der beiden Sprachen ab; sie sollen einen repräsentativen Auszug der Gemeinsprache darstellen. Die Verwendung der Referenzkorpora, die einen repräsentativen Auszug der Gemeinsprache darstellen sollen, unterstützt das Auffinden kontrastiver Gemeinsamkeiten und Unterschiede der beteiligten Sprachsysteme sowie die Identifizierung von Fachsprachenmerkmalen. Insgesamt umfasst das Korpus ca. 120'000 Wörter. | |
| – | Da sich die empirische Analyse mit Frequenzeffekten von grammatischen Strukturen in Fachkommunikation beschäftigt, was über die lexikalische Ebene hinausgeht, reicht es nicht aus, "rohe", bzw. unannotierte, Textkorpora zu untersuchen. Die Penn-Treebank und die TiGer-Baumbank enthalten vollständige syntaktische Analysen inklusive Dependenzstruktur. Das CroCo-Korpus wurde auf folgenden Ebenen annotiert: Morphologie, Lemmatisierung, Wortklassen, Phrasenstruktur und syntaktische Funktionen. Die übersetzten Texte aus dem CroCo-Korpus wurden multidimensional aligniert: Sätze, Einzelsätze, Phrasen, grammatische Funktionen und Wörter. Da das CroCo-Korpus nur in Bezug auf die obersten Knoten im Satz annotiert wurde, wurden die Texte weiterhin mit einer manuellen Annotation der Nominalphrasen und deren Attribuierungen versehen. Das Besondere hierbei ist, dass die Annotationseinheiten auch aligniert wurden, was die automatische Extraktion und Kategorisierung von Übesetzungsshifts ermöglicht. |
Durch dieses multidimensionale Korpusdesign werden zwei theoretische Probleme operationalisierbar: Einerseits ergeben sich die unabhängigen Variablen aus der Zusammensetzung der Subkorpora und sind somit getrennt analysierbar. Wir unterscheiden hier den Fachlichkeitsgrad (Fachsprache vs. Popularisierung vs. Gemeinsprache), die Sprache (Englisch und Deutsch) und die Art der Textproduktion (Originalsprache vs. Übersetzung). Zum anderen ist es auf der Basis der multidimensionalen Annotation und Alignierung möglich, die Kluft zwischen bisher introspektiver oder allenfalls beispielbasierter Fachsprachenbeschreibung und deren Operationalisierung, d. h. der Quantifizierung der Fachsprachenmerkmale im Textkorpus zu überbrücken. Grammatische Fachsprachenmerkmale können automatisch abgefragt werden und in Bezug auf den inter- und intralingualen Vergleich empirisch ausgewertet werden. In diesem Kontext konzentrieren wir uns auf die Nominalphrasenkomplexität als abhängige Variable.
Zur Untersuchung der Nominalphrasenkomplexität im Englischen und im Deutschen sind auf der Basis der multidimensionalen Annotation alle Nominalphrasen aus dem Korpus extrahiert und deren unterschiedliche Prä- und Postmodifikationen automatisch gezählt worden.
Im Sprachvergleich bestätigt ein t-Test, dass in den deutschen Texten sowohl mehr Prämodifikationen (t(7449,696)=3,14; p<0,01) als auch mehr Postmodifikationen (t(8332,827)=3,18; p<0,01) zu finden sind als in den Englischen (beide Ergebnisse sind hochsignifikant)2. Dies deutet auf eine komplexere Nominalphrasenstruktur im Deutschen hin.
Im Registervergleich zeigt die ANOVA3, dass man mehr Prämodifikationen in fachsprachlichen Texten als im Referenzkorpus findet (t(3663,307)=5,69; p<0,001) und dort wiederum mehr als in den popularisierenden Texten (t(6245,633)=5,33; p<0,001). Dies lässt vermuten, dass Prämodifikationen ein Fachsprachenmerkmal sind, und durch deren Weglassung Popularisierung erzeugt wird. Hier könnte es sich also um ein negatives Merkmal für Popularisierungen handeln. Für Postmodifikationen werden im Registervergleich keine signifikanten Ergebnisse gefunden, was nicht verwunderlich ist, wenn man bedenkt, dass z. B. der Relativsatz auch in gemeinsprachlichen Texten als Postmodifikation eingesetzt wird. Auf eine Einzelanalyse der Postmodifikationen werden wir weiter unten noch genauer eingehen.
Für den Vergleich der Übersetzungen mit ihren ausgangssprachlichen Texten zeigt ein Chi-Quadrat-Test, dass mehr veränderte Nominalphrasen in der Übersetzung gefunden werden als identische (χ2(1)=38,01; p<0,001). Dies deutet darauf hin, dass die Übersetzungen eher den typischen Mustern der Zielsprache entsprechen als denen der Ausgangssprache. D. h. die Phrasenstruktur der Ausgangssprache wird selten beibehalten, was auf den Prozess der Normalisierung hinweist.
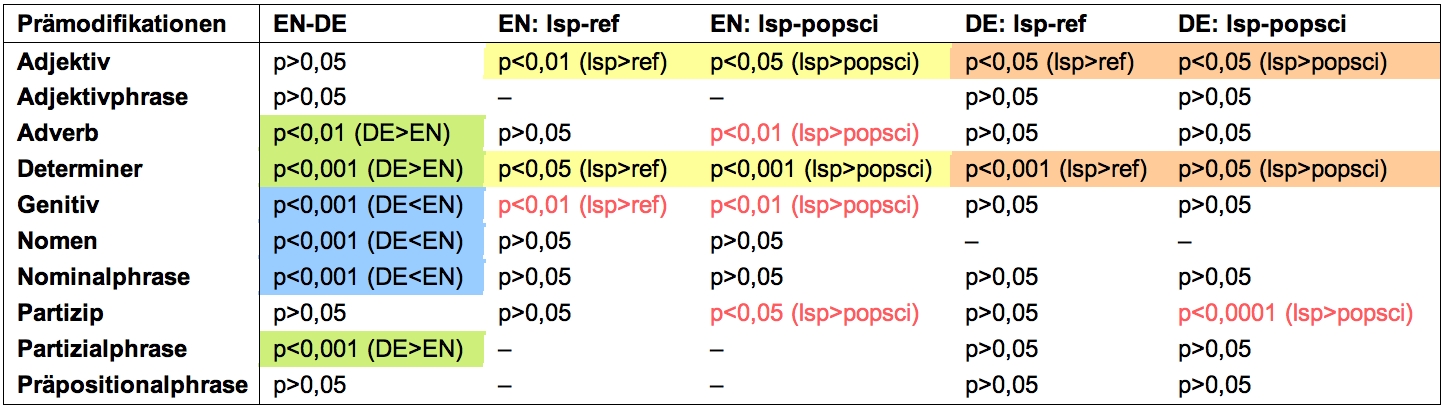
Tabelle 1: Prämodifikationen im Sprach- und Registervergleich
Im Folgenden werden die Einzelanalysen für die Prämodifikationen (Tabelle 1) und Postmodifikationen (Tabelle 2) im inter- und intralingualen Vergleich betrachtet. Um die Signifikanz zu testen, ist eine logistische Regressionsanalyse durchgeführt worden (cf. Baayen 2008). Diese Analysemethode liefert für kategoriale Daten, wie sie hier vorliegen, präzisere Ergebnisse als andere statistische Tests (vgl. Jaeger 2008) und vergleicht die Auftretenswahrscheinlichkeit bestimmter Merkmale unter verschiedenen Bedingungen (hier Korpora) untereinander.
In den beiden Tabellen ist für jeden Vergleich das Signifikanzniveau zu sehen, sowie die Verteilung der Häufigkeiten. 'DE>EN' bedeutet z. B., dass das entsprechende Merkmal in deutschen Texten häufiger auftritt als in englischen5. Die Abkürzung 'LSP' bezieht sich aufden englischen Begriff 'Language for Special Purposes' und bezeichnet dieFachtexte, mit 'REF' ist das Referenzkorpus gemeint und mit 'POP-SCI' die Popularisierung.
Was den Sprachvergleich angeht, können eindeutig kontrastive Unterschiede zwischen dem Englischen und dem Deutschen festgestellt werden. Die Merkmale, die typisch für das Deutsche sind, sind in der Tabelle grün hinterlegt, die typisch englischen Merkmale sind blau hinterlegt. Als typisch deutsche Merkmale können in prämodifizierender Position Adverbien, Determiner und Partizipialphrasen identifiziert werden (siehe Tabelle 1).
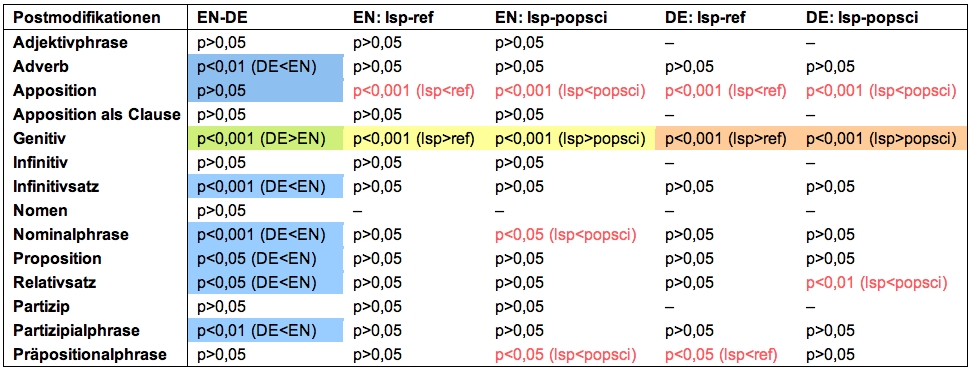
Tabelle 2: Postmodifikationen im Sprach- und Registervergleich
Als Postmodifikation kommt im Deutschen im Vergleich zum Englischen lediglich eine Art, die Genitivattribuierung, signifikant häufiger vor (W(1)=-39,39)5:
Im Englischen lassen sich im Vergleich zum Deutschen signifikant mehr Arten von Postmodifikationen finden: Adverbien (W(1)=-23,52), Infinitivsätze (W(1)=-8,27), Nominalphrasen (W(1)=-29,36), Propositionen (W(1)=-16,72), Relativsätze (W(1)=-38,65) und Partizipialphrasen (W(1)=-21,03). Prämodifizierend findet man im Englischen typischerweise Genitive (siehe Beispiele 3 und 4), Nominalphrasen und Nomen (siehe Tabelle 2).
Obwohl die Prä- und Postmodifikationen bis auf wenige Ausnahmen in beiden Sprachen im System verankert sind, ist deren Quantifizierung im kontrastiven Vergleich sehr unterschiedlich.
Weiterhin kann man den beiden Tabellen entnehmen, welche Merkmale typisch für englische (gelb hinterlegt) und deutsche (orange hinterlegt) Fachtexte sind – beides im Vergleich zur Popularisierung und Gemeinsprache. Interessanterweise sind in beiden Sprachen prämodifizierende Adjektive und Determiner sowie postmodifizierende Genitivattribuierungen als Fachsprachenmerkmale identifiziert worden6. Zusätzlich sind noch einige Sonderfälle (durch rote Schrift markiert) gefunden worden, die im Folgenden beschrieben werden.
| – | Vergleicht man die Popularisierungen mit dem Referenzkorpus, zeigt sich ein signifikanter Unterschied in der Anzahl der prämodifizierenden Partizipien sowohl im Deutschen (W(2)=-3,40) als auch im Englischen (W(2)=-2,22). In beiden Sprachen kommt dieses Merkmal in den Popularisierungen seltener vor als in den Referenzkorpora. Für den Vergleich zwischen den Fachtexten und dem Referenzkorpus kann dieser Unterschied nicht festgestellt werden. Es scheint, als ob die Autoren durch den Nichtgebrauch des prämodifizierenden Partizips versuchen, die Zeitungstexte einfacher zu gestalten. Dies ist allerdings nur eine Pseudo-Vereinfachung, da die Prämodifikation durch ein Partizip kein Fachsprachenmerkmal ist, sondern in der Gemeinsprache genauso häufig auftritt wie in der Wirtschaftsfachsprache. |
| – | Für das prämodifizierende Adverb gilt das gleiche wie für das prämodifizierende Partizip – allerdings statistisch abgesichert nur für das Englische (W(2)=-3,19) (für das Deutsche werden keine signifikanten Unterschiede ermittelt: W(2)=-0,47). |
| – | Der prämodifizierende Genitiv wird im Englischen sowohl im Referenzkorpus (W(2)=2,58) als auch im Zeitungskorpus (W(2)=3,25) signifikant häufiger verwendet als im Fachsprachenkorpus. Die Verwendung dieses Merkmals scheint demzufolge zur Vereinfachung der Texte beizutragen und ist daher als Mittel der Popularisierung im Englischen zu sehen. |
| – | Für das Englische trifft dies auch auf die postmodifizierende Nominalphrase zu, die im Zeitungskorpus signifikant häufiger verwendet wird als im Fachsprachenkorpus (W(2)=2,59). Sie kann im Englischen als popularisierendes Merkmal verwendet werden. |
| – | Die gleiche Wirkung wird durch die postmodifizierende Apposition erzielt. Auch dieses Merkmal ist in den Zeitungstexten (EN: W(2)=6,10; DE: W(2)=5,47) sowie im Referenzkorpus (EN: W(2)=3,88; DE: W(2)=4,91) häufiger zu finden als in den Fachtexten – und dies gilt für beide Sprachen. Es handelt sich also auch hierbei um ein Merkmal der Popularisierung. |
| – | Die Postmodifikation durch Präpositionalphrasen ist im Deutschen ein Fachsprachenmerkmal. Es kommt in Fachtexten signifikant häufiger vor als im Referenzkorpus (W(2)=2,14). Für das Fachtextkorpus und das Zeitungskorpus wird kein signifikanter Unterschied gefunden. Das Merkmal scheint in popularisierenden Texten noch erhalten zu sein. |
| Im Englischen wird ebenfalls kein signifikanter Unterschied zwischen Fach- und Gemeinsprache festgestellt. Der signifikante Unterschied zwischen Fachtextkorpus und Zeitungskorpus (W(2)=-2,11) deutet wiederum darauf hin (ähnlich wie bei der Prämodifikation durch Partizipien oder Adverbien), dass man durch die Weglassung dieses Merkmals in den Popularisierungen eine Pseudo-Vereinfachung zu erreichen versucht. | |
| – | Für den postmodifizierenden Relativsatz werden im Englischen
keine signifikanten Unterschiede für die Subkorpora ermittelt. Das gleiche gilt
für den Vergleich zwischen Fachsprache und Gemeinsprache im Deutschen. Es gibt
allerdings signifikante Ergebnisse dahingehend, dass in deutschen Fachtexten
mehr Relativsätze verwendet werden als in Popularisierungen (W(2)=-3,26).
Nun könnte man dies auch als Pseudo-Vereinfachung interpretieren. Hier liegt
jedoch ein anderer Fall vor: Durch den Sprachenvergleich wird deutlich, dass es
sich bei den Relativsätzen um ein typologisches Merkmal des Englischen handelt
(W(1)=-2,30; p<0,05). Wenn man nun bedenkt, dass die deutschen
Fachtexte Übersetzungen aus dem Englischen sind, deutet die hohe Anzahl an
Relativsätzen eindeutig auf einen Shining-through-Effekt hin. Hier werden die
ausgangssprachlichen Strukturen einfach in den Zieltext importiert, ohne die
zielsprachlichen Normen zu berücksichtigen (siehe Beispiel 5).
(5) "the growth that is essential to achieve that goal" → |
Dieses letzte Beispiel zeigt, dass für typologische Unterschiede zwischen der englischen und der deutschen Sprache geprüft werden muss, ob die Übersetzungen den Normen der Zielsprache gehorchen (was auf einen Normalisierungseffekt hindeuten würde) oder ob sie die Strukturen der Ausgangssprache übernehmen (wie bei dem Shining-through-Effekt am obigen Beispiel der Relativsätze). Kann für einen kontrastiven Unterschied kein signifikanter Unterschied für den Fachlichkeitsgrad festgestellt werden, deutet dies darauf hin, dass sich die Übersetzungen trotz der typologischen Divergenz den anderen beiden deutschen Subkorpora und somit den Normen der Zielsprache angepasst haben6. Dies ist der Fall für die folgenden Prämodifikationen: Adverb, Partizipialphrase, Genitiv, Nomen, Nominalphrase. Weiterhin sind folgende Postmodifikationen betroffen: Adverb, Infinitivsatz, Nominalphrase, Proposition, Partizipialphrase. Determiner sowie postmodifizierende Genitivattribute weichen von diesem Muster dahingehend ab, dass sie einen signifikanten Registerunterschied aufweisen. Beide sind typische Merkmale für das Deutsche, beide kommen im deutschen Fachtextkorpus häufiger vor als in den anderen Subkorpora (letzteres trifft auch auf das Englische zu). Dies deutet ebenfalls auf einen Normalisierungseffekt hin, da sowohl die typologischen als auch die registerbedingten Sprachmuster des Deutschen in den Übersetzungen realisiert wurden.
Abschließend sollen die Ergebnisse noch einmal in Bezug auf die in Kapitel 2 formulierten Hypothesen diskutiert werden.
| – | Was die Untersuchung des Fachlichkeitsgrades der Texte angeht, bestand die Annahme, dass in den Fachtexten signifikant mehr Prä- und Postmodifikationen vorkommen als in der Gemeinsprache. Allgemein kann festgestellt werden, dass in den hier untersuchten Wirtschaftskorpora signifikant mehr Prädmodifikationen vorkommen. Wenn man die Verteilung der Modifikationsarten genauer betrachtet, sind im Registervergleich Determiner, prämodifizierende Adjektive und postmodifizierende Genitive signifikant häufiger in den Fachsprachenkorpora zu finden. Dies ist erstaunlich, da Determiner und prämodifizierende Adjektive in der bisherigen Forschungsliteratur nicht als Fachsprachenmerkmale beschrieben werden und als Merkmale der Gemeinspache gelten. Weiterhin ist es umso interessanter zu beobachten, da diese Merkmale für beide untersuchten Sprachen als Fachsprachenmerkmale identifiziert werden können. |
| Durch die Untersuchung konnten allerdings auch Merkmale der Popularisierung eindeutig nachgewiesen werden, wie z. B. der Genitiv als Prämodifikation in englischen Texten. Popularisierende Merkmale werden sowohl in gemeinsprachlichen Texten als auch in Popularisierungen signifikant häufiger gefunden, was darauf hindeutet, dass dadurch die Texte einfacher und verständlicher werden. Weiterhin gibt es auch einige Merkmale (z. B. Partizipien als Prämodifikation im Englischen und im Deutschen), bei denen zwar kein Unterschied zwischen Fach- und Gemeinsprache gefunden werden kann, die aber in Popularisierungen signifikant seltener verwendet werden. Hier ist anzunehmen, dass die Autoren der Zeitungstexte diese Merkmale als Fachsprachenmerkmale erachten und durch deren Weglassung die Texte einfacher gestalten wollen. Inwiefern dies die bewusste Intention der Autoren ist und ob die Texte dadurch vielleicht doch verständlicher sind, müsste allerdings durch psycholinguistische Experimente überprüft werden. | |
| – | Was den Sprachenvergleich angeht, wird vermutet, dass das
Deutsche inhaltsbezogener ist als das Englische. Diese Inhaltbezogenheit soll
sich in der Verwendung von komplexen Nominalphrasen ausdrücken. Diese Hypothese
wird nicht eindeutig bestätigt: Was die Prämodifikationen angeht, sind
Adverbien, Determiner und Partizipialphrasen typisch für das Deutsche. Im
Englischen findet man hingegen Genitive, Nomen und Nominalphrasen. Die beiden
letzteren lassen sich allerdings dadurch erklären, dass sie vermutlich die
Verwendung von Mehrworteinheiten im Englischen belegen. Überall dort, wo man im
Deutschen Komposita findet, muss das Englische auf mehrgliedrige
Nominalkompositionen zurückgreifen:
(6) "such as the free trade area of the Americas" → |
| Um die Komplexität dieser Strukturen kontrastiv vergleichen zu können, müsste man eine Kompositazerlegung für das Deutsche anwenden. Ginge man vorerst davon aus, dass die deutschen Komposita durch die englischen nominalen Prämodifikationen aufgewogen würden, ist das Deutsche in Bezug auf die Prämodifikationen durchaus als komplexer anzusehen. | |
| Postmodifikationen scheinen hingegen ein deutliches Merkmal für das Englische zu sein. Während man als typisch deutsche Postmodifikation nur die Genitivattribuierung findet, hat das Englische eine ganze Reihe von Postmodifikationen aufzuweisen. Da allerdings die Postmodifikationen meist weniger dicht und somit leichter verständlich sind als die Prämodifikationen, wird hier die Hypothese bestätigt, dass das Englische eher addressatenorientiert und weniger inhaltsbezogen ist als das Deutsche. Allerdings muss auch diese Interpretation psycholinguistisch verifiziert werden. | |
| – | Was die fachübersetzungsspezifischen Eigenschaften angeht, lässt sich festhalten, dass die deutschen Fachübersetzungen in den meisten Fällen Normalisierungseffekte aufweisen. Dies deutet darauf hin, dass die Fachübersetzungen ähnlich rezipiert werden müssten als originalsprachliche Fachtexte, da sie den zielsprachlichen Registernormen gerecht werden. Nur in einem einzigen Fall, bei der Postmodifikation durch den Relativsatz, wurden Shining-through-Effekte gefunden. |
Die hier beschriebene Studie widmete sich der Quantifizierung kontrastiver Unterschiede in englischen und deutschen Nominalphrasen einerseits und der Ausprägung dieser Merkmale in Fachtexten und deren Übersetzungen andererseits. Es wurde gezeigt, dass die statistisch-quantitative Herangehensweise dazu genutzt werden kann, etablierte (Fach-) Sprachenbeschreibungen durch Häufigkeitsbelege im Sprach- und Registervergleich zu verifizieren. Da diese Untersuchung allerdings eher als Pilotstudie anzusehen und nicht repräsentativ für Fachtextsorten im Allgemeinen ist, lassen sich durch die Anwendung der Methodologie auf breiter angelegte Korpusanalysen weiterführende Forschungsperspektiven für die kontrastive Fachsprachenforschung ableiten.
Abgesehen von der Aufstockung des Untersuchungskorpus auf weitere (Fach-)Sprachen, könnte eine linguistische Erweiterung der Studie z. B. die Analyse der Einbettungstiefe sowie Aneinanderreihungen von Prä- und Postmodifikationen betreffen. Außerdem könnten Korrelationen der unterschiedlichen Attribuierungen mit ihrer Stellung im Satz, d. h. mit syntaktischen Funktionen, ausgewertet werden. Eine Ausdehnung der statistischen Tests auf den Vergleich der Fachübersetzungen mit englischen und deutschen Originalen würde weitere fachübersetzungsspezifische Eigenschaften, wie Explizierung, Simplifizierung oder sogar Hybridisierung zum Vorschein bringen. Zu guter Letzt bliebe dann noch die Untersuchung weiterer Fachsprachenmerkmale, wie z. B. Passivierung, und deren Kookkurrenz untereinander.
Inwiefern allerdings die Komplexität grammatischer Strukturen in Fachtexten mit Verständlichkeitsproblemen einhergehen und ob die Verwendung von weniger komplexen Merkmalen zu verständlicheren Texten führt, ist durch psycholinguistische Tests zu überprüfen. In diesem Kontext versuchen wir im Projekt KUFA8 die Komplexität von Fachtexten und deren Auswirkung auf die Verständlichkeit durch eine Kombination von Experimenten (Eye-Tracking, Verständlichkeitstests, Akzeptabilitätsurteile) zu analysieren.
1 Eine ähnliche Problematik geht mit dem "Transparenzgebot" in der Rechtssprache einher (Bundesgerichtshof in Zivilsachen: BGHZ 136: 401ff.). zurück
2 "p" gibt die Irrtumswahrscheinlichkeit bei der Annahme eines statistischen Zusammenhangs an. Bei p<0,05 wird gemeinhin von einem signifikanten Ergebnis gesprochen, bei p<0,01 von "hoch signifikant" (p<0,01) und bei p<0,001 von "höchstsignifikant". zurück
3 Analysis of Variance. Für Prämodifikationen gilt: F(2,10275)=58,77; p<0,001. Für Postmodifikationen gilt: F(2,10275)=1,36; p=0,26). Die paarweisen Vergleiche wurden durch t-Tests vorgenommen. zurück
4 Wenn ein Merkmal in einer Sprache nicht verwendet wird oder wenn ein Merkmal für unsere Hypothesen nicht relevant ist, wurde es bezüglich sprachstruktureller Registerunterschiede in der entsprechenden Sprache auch nicht getestet. zurück
5 Als Prüfgröße für die logistischen Regressionsanalysen wird die Prüfgröße der Wald-Statistik berichtet. Die Irrtumswahrscheinlichkeiten sind in den Tabellen 1 und 2 notiert. zurück
6 Der Begriff "Fachsprachenmerkmal" wird in dieser Studie für diejenigen Prä- und Postmodifikationen verwendet, die in dem untersuchten Fachtextkorpus signifikant häufiger auftreten als im gemeinsprachlichen Referenzkorpus. Da das Fachtextkorpus dieser Studie nicht repräsentativ ist für Fachtexte im Allgemeinen, können keine Generalisierungen und Abstrahierungen in Bezug auf Fachsprachenmerkmale im Allgemeinen vorgenommen werden. zurück
7 Diese Interpretation eines Nicht-Effekts ist nicht unproblematisch, da dies auch darauf hindeuten kann, dass ein Unterschied aufgrund der vorliegenden Daten nicht gefunden werden konnte. Dies scheint hier jedoch nicht der Fall zu sein, da alle relevanten Irrtumswahrscheinlichkeiten weit jenseits der 10%-Marke liegen. Außerdem kann bei der vorliegenden Stichprobengröße von N > 10000 davon ausgegangen werden, dass ein vorliegender Unterschied gefunden werden sollte. zurück
8 www.staff.uni-mainz.de/hansenss/kufa/home.html. zurück
Baker, Mona (1996): "Corpus-based translation studies. The challenges that lie ahead". In: Somers, Harold (ed.): Terminology, LSP and Translation. Studies in Language Engineering in Honour of Juan C. Sager. Amsterdam, Benjamins: 175–186.
Baayen, Harald (2008): Analyzing Linguistic Data. A Practical Introduction to Statistics using R. Cambridge: University Press.
Beneš Eduard (1981): "Die formale Struktur der wissenschaftlichen Fachsprachen in syntaktischer Hinsicht". In: Bungarten, Theo (ed.): Wissenschaftssprache. München, Fink: 185–212.
Brants, Sabine et al. (2004): "TiGer. Linguistic Interpretation of a German Corpus". Journal of Language and Computation (JLAC), Special Issue 2: 597–619.
Fluck, Hans-Rüdiger (1997): Fachdeutsch in Naturwissenschaft und Technik. Einführung in die Problematik der Fachsprachen und die Didaktik/Methodik eines fachsprachlichen Deutschunterrichts. Heidelberg: Groos.
Gläser, Rosemarie (1990): Fachtextsorten im Englischen. Tubingen: Narr.
Halliday, Michael A. K./Martin, Jim R. (1993): Writing science. Literacy and discursive power. London/Washington, D.C.: Falmer Press.
House, Juliane (1996): "Contrastive discourse analysis and misunderstanding. The case of German and English". In: Hellinger, Marlis/Ammon, Ulrich (eds.): Contrastive Sociolinguistics. Berlin/New York, de Gruyter: 345–361.
Jaeger, T. Florian (2008): "Categorial data analysis: Away from ANOVAs (transformation or not) and towards logit mixed models". Journal of Memory and Language 59: 434–446.
Marcus, Mitchell et al. (1994): "The Penn Treebank. Annotating predicate argument structure". Proceedings of the ARPA Human Language Technology Workshop. San Francisco/California, Morgan Kaufman: 114–119.
Neumann, Stella/Hansen-Schirra, Silvia (2005): "The CroCo Project. Cross-linguistic corpora for the investigation of explicitation in translations". In: Proceedings from the Corpus Linguistics Conference Series 1/1. www.corpus.bham.ac.uk/pclc/cl-134-pap.pdf (Stand: September 2009).
Schmidt, Helmut (1975): "Soziale Bindung von Wissenschaft und Forschung". In: Bulletin. Presse und Informationsamt der Bundesregierung 81: 749–753.
Steiner, Erich (2001): "Intralingual and interlingual versions of a text. How specific is the notion of 'translation'?" In: Steiner, Erich/Yallop, Colin (eds.): Exploring translation and multilingual text production. Beyond content. Berlin/New York, de Gruyter: 161–190.
Teich, Elke (2003): Cross-linguistic variation in system and text. A methodology for the investigation of translations and comparable texts. Berlin/New York: de Gruyter.