
Abbildung 2: Belege von glücklicherweise aus dem public-Korpus, alphabetisch geordnet nach dem 1. und 2. Wort rechts des Bezugswortes.
Der vorliegende Beitrag präsentiert Teilaspekte einer umfassenden empirischen Untersuchung der Satzadverbien im heutigen Deutsch, die an der Universität Neuchâtel (Schweiz) im Rahmen einer Dissertation erarbeitet wird.[1] Ich werde im Folgenden skizzieren, wie das Dissertationsprojekt konzipiert ist (Kapitel 1) und mit welchen Methoden und Analyseroutinen die Satzadverbien erforscht werden (Kapitel 2). Im Anschluss daran soll an den zwei speziell ausgewählten Satzadverbien glücklicherweise und paradoxerweise, die im Korpus klar unterschiedlich gebraucht werden, exemplarisch gezeigt werden, wie empirisches Arbeiten mit der Cosmas-Plattform[2] konkret aussehen kann (Kapitel 3). Schliesslich die aus dem Korpus herausgearbeiteten Sprachdaten mit dem in Wörterbüchern kodifizierte Wissen verglichen (Kapitel 4). Es wird deutlich werden, dass das in Wörterbüchern und Grammatiken kodifizierte Wissen über die Satzadverbien öfter revisionsbedürftig ist.
Ziel meiner Dissertation ist es, mit Hilfe von empirisch erhobenen Daten zu beschreiben und wenn möglich zu erklären, wie Satzadverbien in der geschriebenen deutschen Standardsprache der Gegenwart gebraucht werden.[3] Unter Satzadverbien werden hier vereinfacht gesagt Wörter aus der Klasse der Adverbien verstanden, die ohne syntaktische Bindung zu anderen Wörtern im Satz auftreten, also sozusagen ausserhalb des Satzverbandes stehen und sich somit auf den Satz als Ganzes beziehen. Mit solchen Wörtern kann ein Sprecher den Sachverhalt einer Aussage bewerten oder die Geltung eines Sachverhalts einschränken. Die meisten Satzadverbien sind mit Hilfe des Fugenelements -er- und des Suffixes -weise von Adjektiven oder Partizipien abgeleitet. Typische Vertreter der Wortklasse Satzadverbien sind möglicherweise, angeblich, freundlicherweise, leider.
Im Gegensatz zu anderen Untersuchungen[4] stehen bei meinem Dissertationsprojekt nicht Fragen der Abgrenzung, der Definition und der formalen und semantischen Subklassifizierung der Kategorie Satzadverb im Vordergrund, sondern die Frage nach deren Gebrauch, d. h. nach Auftreten, Frequenz und Kollokationen ausgewählter einschlägiger Lexeme. Kookkurrenzpartner bzw Kollokationen. spielen somit in dieser Untersuchung eine zentrale Rolle. Sie werden genau analysiert mit dem Ziel, der "Bedeutung" des Bezugswortes[5] auf die Spur zu kommen. Gemäss dem 43. Paragraphen in Wittgensteins Philosophischen Untersuchungen ist "die Bedeutung eines Wortes sein Gebrauch in der Sprache" (Wittgenstein 1971: 41). Der Gebrauch des Wortes materialisiert sich in seiner sprachlichen Umgebung, so die These, die dieser Arbeit zu Grunde liegt. Analysieren wir über die Kookkurrenzpartner die typische sprachliche Umgebung und somit den typischen Gebrauch eines Wortes, erfahren wir möglicherweise und hoffentlich (!) etwas über seine prototypische Bedeutung.
Ausgangspunkt meiner Arbeit bildet das Lexikon deutscher Modalwörter von Agnes und Gerhard Helbig (Helbig/Helbig 1990). Dieses alphabetisch angeordnete Nachschlagewerk stellt die bislang vollständigste Sammlung und Untersuchung der Satzadverbien des Deutschen dar. Es scheint mir deshalb sinnvoll, meiner Dissertation diese Auflistung und Darstellung von zwei der besten Kennern der Materie zu Grunde zu legen. Der von Helbig/Helbig erfasste Bestand an Satzadverbien soll mittels der nun vorzustellenden Analyseroutine untersucht werden. Die empirische Grundlage der Untersuchung bildet das Deutsche Referenzkorpus des IDS in Mannheim. Dessen öffentlich zugänglicher Teil, die Korpussammlung public, bildet mit über einer Milliarde Wortformen eine der grössten elektronischen Sammlungen deutschsprachiger Gegenwartstexte. Es enthält Belletristik, Wissenschaftsprosa und etliche weitere Textsorten sowie eine grosse Anzahl von Zeitungstexten. Das deutsche Referenzkorpus ist über Cosmas II recherchierbar, was neben der Grösse der Textsammlung das zweite wichtige Argument für die Wahl des Referenzkorpus als Datenbasis ist.[6]
Bei meiner Untersuchung der Satzadverbien handelt es sich um eine korpusbasierte Arbeit mit sowohl quantitativem als auch qualitativem Ansatz, der dem britischen Kontextualismus im weiteren Sinn verpflichtet ist. Das Korpus bildet die alleinige Basis für die Untersuchung. Es wird mit Hilfe von statistischen Verfahren vollständig analysiert. Die Daten, aus dem Korpus zusammengestellt, werden in der Folge mit linguistischen Methoden interpretiert (vgl. Lemnitzer/Zinsmeister: 32ff.).
Die Korpusanalyse im Sinne des Kontextualismus erfolgt stets exhaustiv, was jedoch meist zu unübersichtlich grossen Datenmenge führt. Einzelne zufällig ausgewählte Belegstellen zu untersuchen würde kaum zu brauchbaren Ergebnissen führen. Angesichts der grossen Datenmengen ist deshalb ein überlegtes und geplantes Vorgehen bei der Analyse überaus wichtig. Eine solche Analyseroutine wird in diesem Kapitel vorgestellt und erläutert. Sie verläuft in folgenden Teilschritten:
|
1. Introspektive Annäherung an
das Phänomen 2. Vergleich der Frequenzen 3. Berechnung der regionalen Verteilung 4. Grobanalyse der KWIC-Konkordanzen |
|
5. Kookkurrenzanalyse 6. Analyse und Kompilation der Kookkurrenzprofile 7. Linguistische Beschreibung und Interpretation der Kookkurrenzpartner 8. Zweite Kookkurrenzanalyse zur Gewinnung von typischen syntaktischen Mustern 9. Reziprokanalyse der Kookkurrenzpartner |
Abbildung 1: Schematische Darstellung des Vorgehens bei der Analyse der Kookkurrenzen
Die einzelnen Schritte dieser Routine gliedern sich in zwei Teilphasen. Die ersten Analyseschritte dienen der Annäherung an das Phänomen und sollen globale Aussagen zum Gebrauch des betreffenden Satzadverbs ermöglichen (2.1-2.4). Der zweite Teil untersucht die sprachliche Umgebung des jeweiligen Satzadverbs, insbesondere die aus einer Kookkurrenzanalyse gewonnenen Kookkurrenzpartner (2.5-2.9).
Es führt auch in der Korpuslinguistik kein Weg an der Introspektion vorbei. Sie ermöglicht eine schnelle und "kostengünstige" Hypothesenbildung. Allerdings ist nicht alles sprachliche Wissen der Introspektion zugänglich: Ein klassisches Beispiel dafür sind etwa Frequenzdaten. Selbstverständlich gilt es auch, einschlägiges, bereits kodifiziertes Sprachwissen, das in Wörterbüchern und Grammatiken abgelegt ist, zu berücksichtigen, dies auch dann, wenn dieses Wissen nicht korpusbasiert ist.
Frequenzen einzelner Lexeme können mit recht einfachen Abfragetools ermittelt werden. Frequenzdaten bilden in der Regel die Basis für weitere statistische Manipulationen, können aber schon an sich, als Endresultat, interessant sein, etwa für die Lexikographie oder die Fremdsprachendidaktik. Auch der Rang auf einer nach Frequenz geordneten Wortliste oder die Verteilung von Majuskel- und Minuskelschreibung (eine Unterscheidung, die Cosmas möglich macht) kann in Bezug auf gewisse Fragestellungen (etwa Wortstellung bzw. Satzerststellung) aussagekräftig sein.
Mittels adäquater statistischer Verfahren lassen sich aus Frequenzlisten von Teilkorpora, die nach sprachgeographischen Kriterien zusammengestellt sind, Aussagen über die regionale Verteilung des Gebrauchs einzelner Lexeme machen. Im Variantenwörterbuch des Deutschen (Bickel et al. 2004), das regionale Gebrauchspräferenzen verzeichnet, sind Wortarten wie Satzadverbien allerdings kaum vertreten, dies weil die regionale Besonderheit solcher eher inhaltsschwacher Wörter kaum aufzuspüren ist, wenn man den einzelnen Beleg isoliert betrachtet.
Die Belegstellen werden von Cosmas in der Form einer sogenannten KWIC-Darstellung (KWIC: Key Word In Context) präsentiert, bei der das Bezugswort (das key word) in Konkordanzform aufgeführt wird. Die Belege können nach verschiedenen Kriterien geordnet werden; von den verschiedenen Optionen ist das alphabetische Ordnen der Wörter links und rechts des Bezugswortes oft besonders aufschlussreich. Denn dadurch werden schon beim Überfliegen der Belegstellen "Nester" wie in Abbildung 2 sichtbar, die erste Hinweise auf häufige Verwendungsweisen des Bezugswortes liefern können.
Abbildung 2: Belege von glücklicherweise aus dem public-Korpus, alphabetisch geordnet nach dem 1. und 2. Wort rechts des Bezugswortes.
Von besonderem sprachwissenschaftlichen Interesse sind mit dem untersuchten Lexem auftretende Wortverbindungen. Solche Kookkurrenzen oder Kollokationen[7] werden von der Korpuslinguistik als bedeutungstragende lexikalische Einheiten verstanden.[8] Das in Cosmas integrierte Kookkurrenzanalysemodel erfasst Wörter und Wortcluster, die im Vergleich mit ihrem Gesamtvorkommen statistisch überproportional häufig in der Umgebung des Bezugswortes (z. B. fünf Wörter link und rechts des jeweiligen Satzadverbs) vorkommen.[9] Die Kookkurrenzanalyse erfasst diese Zeichenketten und deren distributionelle Eigenschaften und ordnet sie als Kookkurrenzcluster in sogenannten Kookkurrenzprofilen an (vgl. Abb.3).
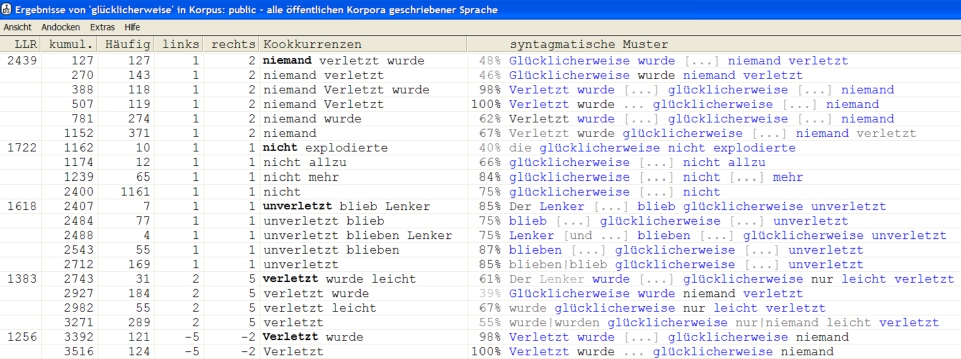
Abbildung 3: Ausschnitt eines Kookkurrenzprofils zu glücklicherweise
Das in Abbildung 3 ausschnittweise reproduzierte Kookkurrenzprofil liefert eine Fülle von Angaben zum Gebrauch des Bezugswortes glücklicherweise. Dazu eine kleine Lesehilfe: In der Kolonne Kookkurrenzen werden die Kookkurrenzpartner zum Bezugswort glücklicherweise aufgeführt. Die primären Kookkurrenzpartner sind fett markiert, dazu kommen weitere Kookkurrenten des jeweiligen Syntagmas. Die Kookkurrenzpartner sind absteigend nach dem LLR-Wert angeordnet, der in der ersten Spalte angegeben ist. Der LLR-Wert ist eine statistisch berechnete Grösse der Affinität des Kookkurrenzpartners zum Bezugswort. In der Spalte Häufig[keit] wird die Zahl der Belege der Kookkurrenzpartner im definierten Suchbereich angegeben (hier: 371 Belege für niemand im Umkreis von 5 Wörtern links und rechts von glücklicherweise). Weiter werden in den Spalten links und rechts Angaben zur typischen Stellung der Kookkurrenten gemacht (z. B. für niemand 1. bis 2. Wort rechts im Kontext, für Verletzt 5. bis 2. Wort links im Kontext). Schliesslich werden ganz rechts noch typische syntagmatische Muster aufgeführt, zusammen mit einer Angabe, auf wieviele Prozent der Belege das angegebene Muster zutrifft.[10]
Zusammenfassend kann man sagen: Das Kookkurrenzprofil liefert die Gesamtheit der statistisch ermittelten Kookkurrenzcluster für ein Bezugswort. Unter Kookkurrenzcluster sollen hier ganz allgemein elementare Konstituenten der Sprache, usuelle Wortverbindungen verstanden werden, wie sie durch massenhaften Gebrauch entstanden sind (vgl. Belica/Steyer to come: 8).
Eine solche Kookkurrenzanalyse kann durch unterschiedliche Parametereinstellungen variiert werden. Es entstehen dadurch natürlich auch leicht unterschiedliche Ergebnisse, unterschiedliche Kookkurrenzprofile, bei denen Kookkurrenten, Frequenzen und LLR-Werte differieren. Für eine gründliche Untersuchung muss die Analyse also mehrmals und mit jeweils veränderten Parametereinstellungen erfolgen. Die unterschiedlichen Profile können dann vom Linguisten verglichen, interpretiert und von Hand zu einem Globalprofil kompiliert werden, bei dem dann aber folglich Angaben zu Frequenz und LLR-Wert fehlen, da diese Angaben in den verschiedenen Profilen nicht identisch sind. Interessant ist dabei auch immer wieder der Vergleich mit den Einträgen in der Kookkurrenzdatenbank des IDS.[11] Ein derart zusammengestelltes Kookkurrenzprofil zum Satzadverb glücklicherweise findet sich als Abbildung 7 im Kapitel 3.1.
Die in den Kookkurrenzprofilen aufgeführten Kookkurenzpartner werden vorerst einmal linguistisch beschrieben. Diese Art der Beschreibung und die damit verbundene Kategorienbildung ist wichtig für deren Interpretation, denn hier werden grammatische, semantische, modale usw. Gemeinsamkeiten der verschiedenen Kookkurrenzpartner sichtbar.
Wenn zu den einzelnen Kookkurrenzpartnern eine grosse Zahl von Belegen im Korpus existiert (z. B. 371 Belege für niemand im Umkreis von 5 Wörtern links und rechts von glücklicherweise), ist deren Bewertung schwierig. In diesen Fällen ist eine eine zweite Kookkurrenzanalyse der betreffenden Belegsätze von grossem Interesse. Dabei wird eine neue Bezugseinheit, bestehend aus dem ursprünglichen Bezugswort (glücklicherweise) und seinem Kookkurrenzpartner (niemand) konstituiert. Aus der Analyse der daraus resultierenden Kookkurrenzprofile und dem genauen Studium der KWIC-Belege können usuelle Muster im Gebrauch von glücklicherweise + niemand extrahiert werden.[12]


Abbildungen 4 und 5: Zweite Kookkurrenzanalyse; Belege der Bezugseinheit glücklicherweise + niemand in Konkordanzform.
In unserer Arbeit wird der Versuch unternommen, solche usuellen Verwendungsweisen auf typische syntaktische Muster, d. h. auf abstrakte, nicht lineare types zu reduzieren, wie sie in der Abbildung 6 zu sehen sind. In Satzform gebracht sind solche Gebrauchsmuster etwa als Beispielsätze in Wörterbüchern sinnvoll (z. B. Bei dem Unfall wurde glücklicherweise niemand verletzt).
| glücklich~ | verletzt werden | niemand | [Ø] dabei bei dem Unfall bei dem Zwischenfall bei der Kollision bei dem Vorfall |
Abbildung 6: Typische syntaktische Muster zu glücklicherweise + niemand
Die Evidenz dieser Muster kann mit Hilfe eines "Gegenchecks", der Reziprokanalyse, überprüft werden. Dazu werden die Kookkurrenten von glücklicherweise (z. B. niemand oder unverletzt) ihrerseits zum Bezugswort erklärt und einer Kookkurrenzanaylse unterzogen. Liefert diese Reziprokanalyse ähnliche oder gleiche Resultate wie die Kookkurrenzanalyse von glücklicherweise, dann kann das als Beleg dafür angesehen werden, dass die als typische syntaktische Muster bezeichneten Gebrauchseinheiten tatsächlich charakteristisch sind für die Verwendung des ursprünglichen Bezugswortes, des Satzadverbs.
In einigen Fällen ist eine quantitative Analyse der Kookkurrenzpartner, wie sie unter 2.8 und 2.9 beschrieben wurde, nicht möglich oder nicht sinnvoll, insbesondere bei zu geringer Affinität der Kookkurrenzpartner zum Bezugswort (d. h. zu geringem LLR-Wert) oder bei einer zu geringen Anzahl von Belegen trotz hohem LLR-Wert. Wir müssen es in solchen Fällen bei einer beschreibenden Analyse gemäss den Schritten 2.1 bis 2.7 bewenden lassen. Ein Beispiel dafür bietet die Analyse des Bezugswortes paradoxerweise im nächsten Kapitel unter 3.2.
Im Folgenden werden die oben skizzierten Analyseschritte eins bis fünf nicht einzeln zu erkennen sein, da sie der Annäherung an das Phänomen dienen und nicht Endresultate liefern. Die im Analyseschritt sechs gewonnenen kompilierten Kookkurrenzprofile sind in den Abbildungen 7 und 8 dargestellt. Die weiteren Analyseschritte (linguistische Interpretation der Kookkurrenzpartner, Beschreibung typischer syntaktischer Muster, Reziprokanalyse) werden dann im einzelnen ausführlich dargestellt.
Das Satzadverb glücklicherweise ist im Untersuchungskorpus Cosmas 8156 mal belegt und erweist sich damit als das dritthäufigste Satzadverb auf -erweise im Korpus. Gemäss der Grammatik der deutschen Sprache handelt es sich bei glücklicherweise um ein bewertend-assertives Satzadverbial, bei dem "eine Bewertung des Sachverhalts durch den Sprecher ins Spiel kommt" (Zifonun 1997: 1128). Es konnten im Übrigen keine regionalen Präferenzen für den Gebrauch von glücklicherweise festgestellt werden.
Kompiliertes Globalprofil
| glücklicherweise | ||
| niemand | ||
| niemand verletzt wurde | ||
| niemand Verletzt wurde | ||
| nicht | ||
| nicht kamen | ||
| nicht allzu | ||
| verletzt | ||
| verletzt wurde leicht | ||
| unverletzt | ||
| unverletzt blieb Lenker | ||
| unverletzt blieb | ||
| nur | ||
| nur leicht erlitt | ||
| keine | ||
| keine Verletzten beklagen | ||
| glimpflich | ||
| glimpflich verlief | ||
| glimpflich endete | ||
| blieb | ||
| blieb verschont | ||
| blieb unversehrt | ||
| Schaden | ||
| Schaden Personen gekommen |
Abbildung 7: Kompiliertes Kookkurrenzprofil zum Bezugswort glücklicherweise
niemand
Das Negationspronomen niemand ist mit einem LLR-Wert von ca. 2500 der engste Kookkurrenzpartner von glücklicherweise und wird in quasi allen Belegen in Passivsätzen verwendet. Das Pronomen hat dabei stets die Subjektfunktion in der semantischen Rolle eines Patiens inne. Die Agensphrase muss in der Regel aus dem Kontext erschlossen werden. In nur gerade 11 Fällen (von ingesamt 317) wird der Agens in Form einer Präpositionalphrase mit von oder durch explizit genannt (von den Trümmern, durch die Lawine, durch Schüsse, durch diese Attacke, usw.). Bei rund einem Viertel der Belegsätze wird die Angabe, bei welcher Art von Ereignis der Vorfall geschehen ist, durch das Präpositionaladverb dabei bzw. wobei oder eine Präpositionalgruppe mit bei eingeleitet. Ansonsten muss auch diese Information aus dem Kontext erschlossen werden.
Typische syntaktische Muster
| glücklich~ | verletzt werden | niemand | [Ø] dabei bei dem Unfall bei dem Zwischenfall bei der Kollision bei dem Vorfall |
Beispiele
| (1) | Durch die Wucht des Aufpralles wurde das Fahrzeug des
fehlbaren Lenkers wieder auf die linke Fahrbahn zurückgeschleudert,
wo
es anschliessend einen Abhang hinunterrutschte und an einem Baum zum
Stillstand
kam. Glücklicherweise wurde niemand
verletzt. St. Galler Tagblatt, 28.06.1999 |
| (2) | Nahe der
Ortschaft Pontebba am Grenzübergang Tarvis
entgleiste mitten in der
Nacht in einer Schlammlawine der Schnellzug Rom Wien,
wobei
glücklicherweise jedoch niemand verletzt wurde. Tiroler Tageszeitung, 24.06.1996 |
Reziprokanalyse
Eine Kookkurrenzanalyse mit dem Bezugswort niemand zeigt mit schöner Evidenz gleiche syntaktische Muster, wie sie im Kookkurrenzprofil von glücklicherweise auftreten [verletzt wurde niemand], allerdings ohne das Satzadverb. Es scheint also, als handle es sich beim Syntagma [verletzt wurde niemand] (3509 Treffer) um Grundmuster, zu dem das Satzadverb glücklicherweise eine frequente Erweiterung bildet (total 85 Mal). Daneben erscheinen als bewertende Satzadverbialien die Präpositionalphrase zum Glück (186 Mal), ferner gottlob (9), Gott sei Dank (5), erfreulicherweise (1).
nicht
Die Negationspartikel nicht wird in den Belegsätzen auffällig oft mit den Verben verletzt werden und explodieren und dem Funktionsverbgefüge zu Schaden kommen gebraucht. Gelegentlich wird die Partikel zusammen mit der Fokuspartikel allzu verwendet.
Typische syntaktische Muster
| glücklich~ | nicht | zu Schaden kommen | Personen Menschen |
|
| glücklich~ | nicht nicht |
verletzt werden expodieren |
Personen Bombe Handgranate |
|
| glücklich~ | nicht | sich
bewahrheiten sich bestätigen eintreten |
[…] | |
| glücklich~ | nicht | sein | allzu gross | Schäden |
Beispiele
| (3) | Menschen kamen glücklicherweise
nicht
zu Schaden, wie die Kantonspolizei St. Gallen mitteilt. Vorarlberger Nachrichten, 15.05.1999 |
Reziprokanalyse
Eine Analyse von nicht ergab nichts für unsere Zwecke Relevantes.
verletzt/Verletzt
Die Verbform verletzt ist hier stets das Partizip II von verletzen im Rahmen einer Passivform. Es handelt sich dabei fast ausschliesslich um Formen der 3.Sg.Ind.Prät., da die Subjektstelle meist von niemand eingenommen wird. Das ergibt dann die schon unter niemand behandelten prototypischen Muster. In der Analyse taucht das Partizip 170 mal mit Minuskelschreibung [wurde glücklicherweise niemand verletzt] und 130 mal mit Majuskelschreibung [Verletzt wurde glücklicherweise niemand] auf.
Typische syntaktische Muster
| glücklich~ | verletzt | werden | niemand keine Personen |
|
| glücklich~ | verletzt | werden | nur leicht | (Fahrzeug)Lenker(in) Fahrer |
| Verletzt | werden | bei dem Unfall | glücklich~ | niemand bei dem Brand |
| Verletzt | werden | durch das Tier | glücklich~ | niemand |
Beispiele
| (4) | Durch den
Aufprall wurde da Auto wieder nach rechts
abgewiesen, schleuderte
über die ganze Fahrbahn und überschlug sich
schlussendlich im
ansteigenden Wiesenbord. Personen wurden glücklicherweise
keine verletzt. St. Galler Tagblatt, 21.10.1998 |
| (5) | Verletzt wurde bei dem Großbrand
glücklicherweise
niemand. Und da auch Gebäude und
Maschinen nicht beschädigt wurden,
liegt der geschätzte Schaden
nur bei rund 2000 Euro. Mannheimer Morgen, 28.06.2003 |
Reziprokanalyse
Eine Analyse der Kookkurrenzpartner zu verletzt zeigt die hohe Auffälligkeit der Kette [wurde niemand verletzt]. Sowohl das einzige Satzadverb unter den Kookkurrenzpartnern, glücklicherweise, als auch die synonyme Präpositionalphrase zum Glück weisen beide eine recht hohe Affinität auf.
unverletzt
Das Adjektiv unverletzt bildet zusammen mit dem Verb bleiben ein Syntagma, das einem Zustands-Passiv ähnelt. Die Subjektstelle wird meist von Ausdrücken wie Lenker und Fahrer eingenommen.
| glücklich~ | unverletzt | bleiben | Lenker (Fahrzeug)Insassen (Bei)Fahrer Menschen |
|
| glücklich~ | unverletzt | überstehen | den
Horror-Crash den Zusammenstoss |
Beispiele
| (6) | Der Fahrer blieb bei dem Crash
glücklicherweise
unverletzt. Es wurden keine weiteren
Personen in den Unfall verwickelt. Mannheimer Morgen, 11.12.2000 |
Reziprokanalyse
Die Kookkurrenzpartner zu unverletzt zeigen eine sehr starke Auffälligkeit der Kette [Lenker blieb unverletzt]. Auch hier weisen das Satzadverb glücklicherweise und die Präpositionalphrase zum Glück hohe LLR-Werte auf.
nur
Die Fokuspartikel[13] nur trägt das Merkmal [+Einschränkung] und bezieht sich auf Verletzungen, Prellungen, Sachschäden und ähnliches. Im dominanten Kontext Unfälle und Katastrophen wären Alternativen zu diesen eben genannten Auswirkungen meist dermassen gravierend, dass der Berichterstatter selbst über Kalamitäten wie Prellungen noch glücklich ist. Die Analyse zeitigt im Übrigen keine dominanten Nomina an der Subjektstelle.
Typische syntaktische Muster
| glücklich~ | verletzt werden | nur | leicht | |
| glücklich~ | erleiden | nur | leichte geringe |
Verletzungen |
| glücklich~ | erleiden | nur | Prellungen Schürfungen |
|
| glücklich~ | entstehen anrichten |
nur | Sachschaden Blechschaden |
|
| glücklich~ | geben | nur | Leichtverletzte |
Beispiele
| (7) | Aus bisher ungeklärter Ursache neigte sich das
fast 100 Tonnen schwere Fahrzeug 150 Meter nach der Eisenbahnkreuzung nach
links und kippte um. Der Kranführer wurde dabei
glücklicherweise
nur leicht verletzt. Kleine Zeitung, 25.09.2000 |
| (8) | Glücklicherweise nur kleinen
Sachschaden
richtete ein Autofahrer an, der am Sonntag gegen abend nach
gefährlicher
Fahrt in Goldach einen Unfall verursachte. St. Galler Tagblatt, 17.11.1998 |
Reziprokanalyse
Eine Analyse von nicht ergab nichts für unsere Zwecke Relevantes.
keine
Der Negations-Artikel kein trägt ebenso wie die Fokuspartikel nur das Merkmal [+Einschränkung]. Er benennt die unter nur bereits angesprochenen Alternativen und schliesst sie gleichzeitig aus. Das Ausbleiben gravierender Verletzungen oder verletzter Personen beispielsweise wird als glücklicher Umstand gewertet.
Typische syntaktische Muster
| glücklich~ | gibt es | keine | Verletzten | |
| glücklich~ | verletzt werden | keine | Personen | |
| glücklich~ | festgestellt werden erleiden davon tragen |
keine | grösseren gravierenden schwerwiegenden |
Verletzungen |
| glücklich~ | zu Schaden kommen | keine | Personen Menschen |
Beispiele
| (9) | Immer häufiger müssen Genfer
Polizeieinheiten
in Kampfanzügen zum Schutz der UN ausrücken.
Glücklicherweise
gab es bisher keine
Verletzte. Frankfurter Rundschau, 26.09.1998 |
| (10) | Sieben
weitere Personen hatten durch die Stichflamme
zum Teil schwere,
glücklicherweise aber keine lebensgefährlichen
Verletzungen erlitten. Kleine Zeitung, 29.06.1998 |
Reziprokanalyse
Eine Analyse von nicht ergab nichts für unsere Zwecke Relevantes.
glimpflich
Das Adjektiv glimpflich, hier meist adverbial gebraucht und entsprechend unflektiert, bezieht sich häufig auf den Verlauf bzw. den Ausgang eines Unfalls.
Typische syntaktische Muster
| glücklich~ | verlaufen enden ausgehen |
Unfälle Stürze Busunfall |
glimpflich |
Beispiele
| (11) | Regen und nasser Schnee auf unterkühlten
Fahrbahnen
führten am Wochenende auch in Oberösterreich zu
gefährlichen
Straßenverhältnissen und einen Busunfall,
der glücklicherweise
aber glimpflich verlief: Neue Kronen-Zeitung, 23.01.1995 |
Reziprokanalyse
Die Analyse zu glimpflich bestätigt die angegebenen typischen Muster, etwa mit den verbalen Kookkurrenzpartnern verlaufen, ausgehen, enden und den nominalen Kookkurrenzpartnern Unfall, Zwischenfall, Stürze. Auch hier sind wieder sowohl die Präpositionalgruppe zum Glück als auch das Satzadverb glücklicherweise prominent vertreten.
blieb/blieben
Die Flexionsformen von bleiben bilden zusammen mit dem Partizip verschont (oder den bedeutungsähnlichen Adjektiven unverletzt, unversehrt, usw.) Formen des Zustands-Passivs (vgl. unverletzt). Die Subjektstelle wird meist von Nomen wie Lenker und Fahrer eingenommen.
Typische syntaktische Muster
| glücklich~ | unverletzt verschont unversehrt |
bleiben | Lenker (Fahrzeug)Insassen Fahrer Menschen |
|
| glücklich~ | bleiben | es | bei
Blechschaden bei Sachschaden |
Beispiele
| (12) | In der Folge überschlug sich das Fahrzeug gleich
mehrere Male. Glücklicherweise blieb der Fahrer
unverletzt. St. Galler Tagblatt, 16.07.1997 |
| (13) | Zu dem
Unfall kam es auf der Auffahrt von der Friedrich-Engels-Straße
zur
Nuthestraße. Es blieb glücklicherweise bei
Sachschaden,
meldete die Polizei. Berliner Morgenpost, 20.09.1999 |
Reziprokanalyse
Die Kookkurrenzanalyse von blieb bzw. blieben zeitigt sehr deutlich Syntagmen wie [blieb verschont Lenker] oder [blieb unversehrt glücklicherweise].
Schaden
Das Nomen Schaden stellt in den Belegsätzen in den allermeisten Fällen den Nominalteil des Funktionsverbgefüges zu Schaden kommen dar (Kamber 2006: 1378). Dieses Funktionsverbgefüge hat einen passivischen Charakter, das Subjekt erfüllt hier also wiederum die Patiensrolle (vgl. niemand).
Typische syntaktische Muster
| glücklich~ | zu Schaden kommen | niemand keine Menschen |
|
| glücklich~ | nicht | zu Schaden kommen | Menschen Personen |
Beispiele
| (14) | In Südkalifornien hat am Samstag die Erde stark
gebebt. Doch glücklicherweise kam niemand zu
Schaden. Züricher Tagesanzeiger, 18.10.1999 |
Reziprokanalyse
Die Analyse des Funktionsverbgefüges zeigt ein deutlich signifikantes Miteinander-Auftreten von zu Schaden kommen mit glücklicherweise, niemand, nicht und Personen.
Zusammenfassung
Aufgrund der oben durchgeführten Analysen können wir folgende Aussagen treffen:
| 1. | Fünf Verwendungsweisen von glücklicherweise
können als prototypisch angesehen werden: - Glücklicherweise wurde niemand verletzt. - Personen sind dabei glücklicherweise nicht/keine zu Schaden gekommen. - Der Fahrer blieb glücklicherweise unverletzt. - [Jmd.] erlitt glücklicherweise nur leichte Verletzungen. - Der Unfall verlief glücklicherweise glimpflich. |
| 2. | Mit Abstand am häufigsten wird glücklicherweise im Kontext von Unfall- und Katastrophenmeldungen verwendet. Verkehrsunfälle sind dabei sehr stark vertreten. Dies lässt sich wohl durch die Tatsache erklären, dass das public-Korpus vor allem aus Zeitungstexten besteht. |
| 3. | Das Satzadverb glücklicherweise bezieht sich ausnahmslos auf Propositionen im Aussage-Modus. Es wird darüber hinaus nie zusammen mit einem zweiten Satzadverb gebraucht. Ein an sich durchaus möglicher Satz wie Es wurde dabei wahrscheinlich glücklicherweise niemand verletzt ist nicht belegt. Aus diesem - für die Satzadverbien insgesamt repräsentativen Befund geht hervor, dass die detaillierten Kombinationsregeln von Helbig/Helbig (1990) an der sprachlichen Realität vorbeizielen. |
| 4. | Die Verwendung des Satzadverbs glücklicherweise zeigt eine auffällige Vorliebe für passivische Prädikate, was sich vermutlich durch den dominanten Kontext Unfall- und Katastrophenmeldungen erklären lässt, in dem die beteiligten Agenten nicht klar erkennbar sind oder nicht genannt werden können. |
| 5. | Auffällig häufig wird das Satzadverb glücklicherweise zusammen mit Wörtern und Morphemen gebraucht, die das Merkmal [+Einschränkung] tragen, wie niemand, nicht, keine, nur, un- usw. Man kann daraus schliessen, dass das Satzadverb besonders häufig gebraucht wird, wenn jemand glücklich darüber ist, dass etwas nicht so schlimm ausgegangen ist, wie man hätte befürchten können. |
| 6. | Das Verhältnis von Majuskel- zu Minuskelschreibung ist im Korpus etwa drei zu fünf. Das Satzadverb glücklicherweise wird also mit einem Majuskelanteil von knapp 40 % im Vergleich zu anderen Satzadverbien besonders gerne in Satzerststellung verwendet: Glücklicherweise wurde niemand verletzt. |
Das Satzadverb paradoxerweise verhält sich im Korpus anders als das unter 3.1. analysierte glücklicherweise. Es finden sich zum einen deutlich weniger Belege (1296), zum anderen hat es als Bezugswort auch eine weitaus geringere Affinität zu anderen Lexemen, was sich in den deutlich niedrigeren LLR-Werten der Kookkurrenzpartner niederschlägt. Es konnten ebenfalls keine regionalen Präferenzen für den Gebrauch von paradoxerweise festgestellt werden.
| paradoxerweise | ||
| gerade | ||
| gerade dadurch | ||
| gerade deshalb | ||
| gerade der/die/das | ||
| ausgerechnet | ||
| - [Gedankenstrich] | ||
| - paradoxerweise - | ||
| scheinbar | ||
Abbildung 8: Kompiliertes Kookkurrenzprofil zum Bezugswort paradoxerweise
gerade
gerade wird in den Belegsätzen ausschliesslich als Fokuspartikel verwendet. Die Partikel kann in allen Belegsätzen ohne grosse Bedeutungsveränderung durch ausgerechnet oder just ersetzt werden.
| (15) | Paradoxerweise sind es aber gerade oft
die Frauen selbst, die "Nur-Hausfrauen" geringschätzen und ihre
Männer
in eine Karrierelaufbahn pushen. Züricher Tagesanzeiger, 22.10.1996 |
| (16) | Das gilt
nicht nur für Skitouren, sondern auch
für viele andere
Risikosportarten, die in den letzten Jahren populär
wurden und die
ihre Attraktivität ja paradoxerweise gerade
aus dem
Gefahrenmoment beziehen. Die Presse, 20.01.1995 |
| (17) | Die Salinen
verkaufen heuer mehr Streusalz denn je.
Paradoxerweise schmilzt
gerade dadurch der Gewinn. Salzburger Nachrichten, 10.02.1999 |
Gerade stuft den fokussierten Aspekt der Proposition als auffällig und unerwartet ein. Der Schreiber hätte nicht erwartet, dass es gerade die Frauen selbst sind, die "Nur-Hausfrauen" geringschätzen (Beispiel 15) und dass just das Gefahrenmoment eine Tätigkeit attraktiv machen kann (Beispiel 16). Die Partikel gerade steht in fast allen Belegsätzen rechts vom Satzadverbs.
Die semantischen Merkmale [+auffällig] und [+unerwartet] des Satzadverbs paradoxerweise werden durch die Verwendung der Fokuspartikel gerade, die dieselben Merkmale trägt, zusätzlich herausgestrichen, oder anders herum: das statistisch signifikante Zusammenauftreten von paradoxersweise und gerade legt den Schluss nahe, dass auch das Satzadverb die semantischen Merkmale [+auffällig] und [+unerwartet] trägt.
ausgerechnet
ausgerechnet wird in den Belegsätzen stets als Fokuspartikel und zur Diktumsgraduierung verwendet (Zifonun et al. 1997: 869ff.).
| (18) | Eine der schmalsten Gassen in Lampertheim trägt
paradoxerweise ausgerechnet den Namen Riesengasse. Mannheimer Morgen, 30.12.1997 |
Der Schreiber bewertet die Koinzidenz zweier Sachverhalte als (auf den ersten Blick) in hohem Grad widersprüchlich. Die Fokuspartikel ausgerechnet erscheint in den Belegsätzen ausschliesslich rechts des Satzadverbs, meist in der Position [+1].
Ausgerechnet hat eine hervorhebende Wirkung. Es fokussiert jenen Teil der Aussage, die den grössten Mitteilungswert hat. In ihrem Skopus steht eine Nominalgruppe, die durch die Partikel eingestuft wird. Sie bringt zum Ausdruck, dass der angesprochene Sachverhalt stark von der Erwartung abweicht, ohne dabei dieses Abweichen positiv oder negativ zu bewerten. Das Satzadverb paradoxerweise hat eine dieser Fokuspartikel ähnliche Wirkung. Diese beiden sprachlichen Mittel der Modalität scheinen sich also eher zu verstärken als zu ergänzen (vgl. gerade).
- [Gedankenstrich]
Das Satzadverb wird mittels des graphischen Elements Gedankenstrich als Einschub ausgewiesen. Allerdings können dafür keine Gründe, wie sie bei Zifonun (Zifonun et al. 1997: 896) aufgezählt werden, namhaft gemacht werden. Vielleicht markiert der Gedankenstrich eine besonders starke persönliche Einstellung des Schreibers. Hier kann jedoch nur spekuliert werden. Der - [Gedankenstrich] ist bei anderen Satzadverbien kein Kookkurrenzpartner.
| (19) | Das Werk
Kafkas war - paradoxerweise - nie zur Gänze auf Tschechisch
lesbar. Die Presse, 08.02.1997 |
| (20) | Die
Lener-Truppe hat den Finalplatz aber vermutlich
schon einen Tag zuvor
verloren -
paradoxerweise in einem Match, das gewonnen
wurde. Kleine Zeitung, 10.05.1997 |
scheinbar
Scheinbar zeigt zwar eine nur geringe Affinität zu paradoxerweise (kleiner LLR-Wert) und ist im gesamten Korpus auch nur sechsmal belegt. Dennoch ist es für diese Untersuchung von einigem Interesse, weil es sich beim Kookkurrenzpartner scheinbar ebenfalls um ein Satzadverb handelt.
| (21) | Das Buch
hat, scheinbar paradoxerweise,
im Prozeß seiner
Verbreitung keine Stütze mehr. Die ZEIT, 19.04.85 |
| (22) | Gerade die religiöse Neubestimmung des Ehebundes
und der Versuch der Kirchen, die Sexualität auf die Ehe zu
beschränken,
schufen, scheinbar paradoxerweise, die
Bedingungen für die
Liebesheirat. Mannheimer Morgen, 02.01.1998 |
Die beiden Satzadverbien haben in keinem Beleg denselben Bezugsbereich. Paradoxerweise bezieht sich auf das ganze Diktum, während sich scheinbar in (21) auf paradoxerweise (die Paradoxie ist nur scheinbar) und in (22) auf das Partizip innerhalb der Nominalgruppe bezieht, die innerhalb des Diktums eine Proposition für sich bildet. Gemäss den Angaben in Wörterbüchern ist ein Paradox ein bloss scheinbarer Wiederspruch. Demzufolge dürfte es sich bei scheinbar paradoxerweise um einen Pleonasmus handeln. Scheinbar könnte somit bei jeder Verwendung von paradoxerweise ohne Bedeutungsunterschied hinzugefügt werden.
Zusammenfassung
| 1. | Paradoxerweise verfügt über eine gewisse Affinität zu den Fokuspartikeln gerade und ausgerechnet, welche wie dieses die unerwartete und auffällige Koinzidenz zweier Sachverhalte herausstreichen. |
| 2. | Für paradoxerweise ist ein Zusammenauftreten mit einem zweiten Satzadverb (scheinbar) belegt. Man kann dieses selten zu beobachtende Zusammenauftreten als verstärkenden Pleonasmus deuten. |
| 3. | Der auffälligste Befund ist die Fehlen typischer syntaktischer Verbindungen. Ebenfalls nicht nachzuweisen sind typische Wortverbindungen mit Autosemantika. Auch verwendungstypische Domänen und Kontexte sind nicht auszumachen. Dies alles deutet auf einen sehr unspezifische Gebrauch von paradoxerweise hin, was wohl ein Charakteristikum der meisten Satzadverbien sein dürfte. |
| 4. | Das Faktum, dass Satzadverbien wie paradoxerweise häufig zwischen Gedankenstrichen (19) oder Kommas (21) eingeschlossen auftreten, ist ein starkes Indiz für deren Bezug auf den Satz als ganzen. Bei der gesprochenen Realisierung werden die auf diese Weise isolierten Satzadverbien intonatorisch vom Rest des Satzes abgehoben. |
Zum Schluss möchte ich die Ergebnisse der Korpusuntersuchungen mit den Einträgen in verschiedenen Wörterbüchern konfrontieren. Ich vergleiche dabei die Angaben das einsprachige Grosswörterbuch Das grosse Wörterbuch der deutschen Sprache in zehn Bänden (GWDS) von Duden, die beiden einbändigen Wörterbücher Duden Universalwörterbuch (DUW) und Wahrig, sowie zwei einsprachige Lernerwörterbücher Langescheidts Grosswörterbuch Deutsch als Fremdsprache (LaDaF) und das Wörterbuch Deutsch als Fremdsprache (WöDaF) miteinander. Das Ziel ist es zu überprüfen, ob der mit korpuslinguistischen Methoden beschriebene Sprachgebrauch mit der in den Wörterbüchern präsentierten Sprachwirklichkeit übereinstimmt.
Die folgenden Tabellen orientieren über die Aufnahme eines der beiden Satzadverbien in den Wörterbüchern sowie über die dazu gelieferten Erläuterungen.[14]
| GWDS | DUW | Wahrig | LaDaF | WöDaF | |
| glücklicherweise | x | x | x | x | x |
| paradoxerweise | x | x | o | [unter: paradox] | o |
Abbildung 9: Überblick der Wörterbucheinträge. x = das Lemma ist gebucht; o = das Lemma ist nicht gebucht.
| glücklicherweise | ||
| Interpretamente | Beispiel | |
| GWDS | - zum Glück - erfreulicherweise |
- g. gab es
keine Verletzten. - Man braucht bei uns g. nicht viel Mut, um den Mächten zu widersprechen. |
| DUW | - zum
Glück - erfreulicherweise |
- g. gab es keine Verletzten. |
| Wahrig | - zum Glück - durch einen glücklichen Zufall |
- O |
| LaDaF | - durch einen
günstigen Umstand
od. Zufall - zum Glück ↔ leider |
- g. wurde bei dem Umfall niemand verletzt |
| WöDaF | - weil die Umstände günstig, glücklich sind, waren. | - g. wurde niemand verletzt |
Abbildung 10: Interpretamente und Beispiele zu glücklicherweise in den betreffenden Wörterbüchern.
| paradoxerweise | ||
| Interpretamente | Beispiel | |
| GWDS | 1. in paradoxer Weise 2. merkwürdigerweise unsinnigerweise |
1. p. wird nämlich die weltweite
Wasserverknappung
von überfluteten Küsten begleitet. 2. er hat sich p. freiwillig für diese Tätigkeit gemeldet |
| DUW | 1. in paradoxer Weise 2. merkwürdigerweise unsinnigerweise |
O |
| Wahrig | O | O |
| LaDaF | [unter: paradox] | O |
| WöDaF | O | O |
Abbildung 11: Interpretamente und Beispiele zu paradoxerweise in den betreffenden Wörterbüchern.
In den beiden Duden-Wörterbüchern werden für das Lemma glücklicherweise die Präpositionalgruppe zum Glück und das Satzadverb erfreulicherweise als Interpretamente aufgeführt. Beide Duden liefern das gleiche konstruiertes Beispiel: glücklicherweise gab es keine Verletzten, das sich aus drei Gründen als absolut prototypisch erwiesen hat (Kontext Unfälle, affine Kookkurrenzpartner, Erstellung des Satzadverbs). Der 10-bändige Duden bietet darüber hinaus noch einen Originalbeleg.
Während zum Glück ein - im Prinzip in jedem Kontext mit dem Satzadverb austauschbares - Synonym sein dürfte, trifft dies für erfreulicherweise nicht zu. Erfreulicherweise wurde niemand verletzt ist zwar rein grammatisch betrachtet ein korrekter Satz, kommt aber im gesamten Korpus bei insgesamt 3175 Belegen für erfreulicherweise lediglich 3 Mal so vor.
Glücklicherweise ist ein prototypisches Sprachmittel zum Ausdruck der Erleichterung (cf. Kontaktschwelle), erfreulicherweise dagegen scheint eher demjenigen der Zufriedenheit/Befriedigung zu dienen.[15] Auch die jeweiligen typischen Verwendungskontexte sind unterschiedlich. Bei glücklicherweise ist ein Ereignis, bedingt durch Zufall oder einen günstigen Umstand nicht eingetreten, während man mit erfreulicherweise eher stattgehabte Ereignisse (vor allem in den Domänen Vereine und Freizeit) berwertet. Ein prototypisches Verwendungsmuster ist etwa der folgende: Erfreulicherweise stehen zwei Austritten drei Neueintritte gegenüber.
Ein Gegencheck in den Duden-Wörterbüchern ergibt, dass das Lemma erfreulicherweise mit den Interpretamenten zum Glück, glücklicherweise erklärt wird, sowie mit dem Beispiel Erfreulicherweise passierte ihm nichts exemplifiziert wird. Das Wörterbuch ist somit zwar in sich konsistent, dürfte hier aber nicht ins Schwarze treffen. Die bei Wahrig gegebenen Interpretamente zum Glück, durch einen glücklichen Zufall scheinen angemessen, ein typischer Verwendungskontext wird leider nicht gegeben.
Die Einträge bei LaDaF und WöDaF sind angemessen und treffend, bei WöDaF fehlt das direkt substituierbare Synonym zum Glück.
Das Satzadverb paradoxerweise dient dazu, die Koinzidenz zweier Sachverhalte als überraschend, so nicht erwartet oder gar (eventuell bloss scheinbar) widersprüchlich zu charakterisieren. Die Duden-Werke glauben, dabei zwei Unterbedeutungen unterscheiden zu können: zum einen sozusagen den reinen (scheinbaren) Widerspruch, zum andern - in umgangssprachlicher Verwendung - eine stärker negativ wertende Verwendung merkwürdigerweise oder gar unsinnigerweise. Eine solche Differenzierung ist von den Belegen her allerdings kaum zu rechtfertigen. Entsprechende Substitutionstests insbesondere mit Hilfe des Interpretaments unsinnigerweise führen fast immer zu einer nicht akzeptablen Veränderung des Sinns der betreffenden Äusserung.
| (23) | "Wir
profitieren paradoxerweise [*unsinnigerweise]
von der Rezession in
der Baubranche", sagt er. Mannheimer Morgen, 26.03.2002 |
Im Übrigen zeigt auch ein Gegencheck im Dudenwörterbuch selber, dass unsinnigerweise durch andere Interpretamente als paradox(erweise) paraphrasiert wird.
(un|sin|ni|ger|wei|se <Adv.>: obgleich es unsinnig, überflüssig, unnötig ist. DUW)
Wichtiger schiene uns beim Lemma paradoxerweise, in den Anwendungsbeispielen verstärkende Partikeln wie gerade oder ausgerechnet als prototypische Kookkurrenten zu verwenden und eventuell die Kombination mit dem verstärkend-pleonastischen Satzadverb scheinbar zu dokumentieren.
Anhand der Beispiele glücklicherweise und paradoxerweise wurde das methodische Vorgehen bei der Untersuchung der Satzadverbien im Rahmen meines Dissertationsprojektes vorgestellt. Dabei haben sich die Kookkurrenzanalyse, die Analyse der Kookkurrenzprofile und die Reziprokanalyse als die lohnensten Untersuchungsschritte erwiesen. Mit ihrer Hilfe lassen sich zuverlässige und wichtige Aussagen über den Gebrauch dieser Satzadverbien machen.
Bei der Untersuchung des - absichtlich ungleich zusammengestellten - Wortpaares hat sich deutlich gezeigt, dass glücklicherweise im Vergleich zu anderen Satzadverbien über stark ausgeprägte Gebrauchstypen mit autosemantischen Kookkurrenzpartnern und klare Präferenzen für bestimmte Domänen verfügt. Die Analyse des Gebrauchs von paradoxerweise dagegen zeitigt Charakteristika, die wohl auch für die meisten anderen Satzadverbien typisch sein dürften: fehlende Kookkurrenzpartner mit Autosemantik, fehlende Gebrauchstypen, Affinität zu Fokuspartikeln, keine Präferenzen bezüglich der Stellung im Satz.
Die beiden sehr unterschiedliche Beispiele sollten die Stärken und Schwächen der gewählten Analyseroutine aufzeigen. Eine so angelegte Untersuchung stellt also auch die Methoden der Korpuslinguistik selbst auf den Prüfstand. Bei der konkreten Anwendung dieser Verfahrensweisen kommen unweigerlich auch methodologische Fragen auf, die hier allerdings nicht oder nur am Rande angesprochen werden konnten. Im Rahmen einer Dissertation aber werden solche Probleme sicherlich zu diskutieren sein.
1 Arbeitstitel: Satzadverbien im Deutschen - eine korpusbasierte Untersuchung. [zurück]
2 Cosmas ist das Korpusrecherche- und Korpusanalysesystem des Instituts für deutsche Sprache (IDS) in Mannheim. Für weitere Informationen zu Cosmas (Corpus Search, Management and Analysis System) siehe: http://www.ids-mannheim.de/cosmas. [zurück]
3 Satzadverbien werden in der Fachliteratur auch als Modaladverb (Kolde 1970), Modalwort (Helbig/Helbig 1990), Modalpartikel (Zifonun et al. 1997) oder Kommentaradverb (Duden 2005) bezeichnet. Vgl. für Testbatterien und Definitionskriterien Helbig/Helbig (1990). [zurück]
4 Vgl. besonders Helbig/Helbig (1990) und die dort zitierte Literatur. [zurück]
5 Unter Bezugswort (key word) wird hier, im Anschluss an die Cosmas-Terminologie, das zu untersuchende Wort verstanden, für welches Belege oder Kookkurrenzpartner gesucht werden. [zurück]
6 Für weitere Informationen bezüglich Referenzkorpus und Cosmas II vgl. http://www.ids-mannheim.de/cosmas2/. [zurück]
7 Zur Unterscheidung Kookkurrenz vs. Kollokation vgl. u. a. Lemnitzer/Zinsmeister (2006: 30) oder auch: Steyer (2002) und Steyer (2004). [zurück]
8 Vgl. dazu das von Teubert in diesem Band vertretene Konzept der "lexikalischen Einheit" als Bedeutungsträger. [zurück]
9 Zur Arbeitsweise des Kookkurrenzanalysemodels in Cosmas vgl.: http://www.ids-mannheim.de/kl/misc/tutorial.html und Belica/Steyer (to come). [zurück]
10 Zur Interpretation des Kookkurrenzprofils vgl. auch http://www.ids-mannheim.de/kl/misc/tutorial.html. [zurück]
11 Diese Kookkurrenzdatenbank (http://corpora.ids-mannheim.de/ccdb/) wurde von Cyril Belica am Institut für deutsche Sprache in Mannheim als "korpuslinguistische Denk- und Experimentierplattform" ins Netz gestellt. Sie enthält für jedes Wort die Ergebnisse von bis zu fünf verschiedenen Kookkurrenzanalysen (mit unterschiedlicher Parametereinstellung). [zurück]
12 Solche usuellen Muster werden bereits in der ersten Kookkurrenzanalyse durch die sogenannten syntagmatischen Muster, die Cosmas berechnet, angezeigt (vgl. Abb. 1). [zurück]
13 Fokuspartikeln (vgl. Duden 2005: 596) werden bei (Zifonun et al. 1997) auch Gradpartikeln genannt. [zurück]
14 Die Einträge finden sich unter: GWDS 1545, 2851; DUW 619, 1120; Wahrig: 568; LaDaf: 414, 725; WöDaF: 421. [zurück]
15 Die bei Helbig/Helbig (1990) genannten Sprechaktwerte Glücksgefühl (für glücklicherweise) und Freude (für erfreulicherweise) scheinen uns zu eng aus dem Etymon abgeleitet und dabei in den betreffenden Kontexten nicht zutreffend. [zurück]
Belica, Cyril/Steyer, Kathrin (to come): "Korpusanalytische Zugänge zu sprachlichem Usus". Vorabdruck: www.ids-mannheim.de/kl/projekte/uwv/CBKSpraha.ver20050426.mit.summ.pdf.
Duden (31996): Universalwörterbuch. Hrsg. u. bearb. vom Wiss. Rat u. d. Mitarb. der Dudenredaktion. Unter der Leitung von Günther Drosdowski. Mannheim.
Duden (31999): Das grosse Wörterbuch der Deutschen Sprache in zehn Bänden. Hrsg. vom Wiss. Rat der Dudenredaktion. Mannheim.
Duden (72005): Die Grammatik - unentbehrlich für richtiges Deutsch. Hrsg. von der Dudenredaktion. Mannheim. (= Der Duden in 10 Bänden; Bd. 4)
DUW = Duden (31996): Universalwörterbuch.
GWDS = Duden (31999): das grosse Wörterbuch der Deutschen Sprache in zehn Bänden.
Götz, Dieter et al. (eds.) (51997): Langenscheidts Grosswörterbuch Deutsch als Fremdsprache. Hrsg. in Zusammenarbeit mit der Langenscheidt-Redaktion. Berlin.
Helbig, Gerhard/Helbig, Agnes (1990): Lexikon der deutschen Modalwörter. Berlin.
Kempcke, Günter (2000): Wörterbuch Deutsch als Fremdsprache. Unter Mitarbeit von Barbara Seelig et al. Berlin.
Kolde, Gottfried (1970): "Zur Funktion der sogenannten Modaladverbien in der deutschen Sprache der Gegenwart". Wirkendes Wort 20: 116-125.
LaDaF = Götz (1997).
Lemnitzer, Lothar/Zinsmeister, Heike (2006): Korpuslinguistik - eine Einführung. Tübingen.
Steyer, Kathrin (2002): "Wenn der Schwanz mit dem Hund wedelt". In: Hass-Zumkehr, Ulrike et al. (eds.): Ansichten der deutschen Sprache. Festschrift für Gerhard Stickel zum 65. Geburtstag. Tübingen: 215-236. (= Studien zur deutschen Sprache 25).
Steyer, Kathrin (ed.) (2004): Wortverbindungen - mehr oder weniger fest.. Berlin. (= Institut für Deutsche Sprache Jahrbuch 2003).
Wahrig, Gerhard (1997): Deutsches Wörterbuch. Gütersloh.
WöDaF = Kempcke (2000).
Zifunon, Gisela et al. (eds.) (1997): Grammatik der deutschen Sprache. Berlin. (= Schriften des Instituts für Deutsche Sprache 7,1-7,3).