 in French
in French
in French
in FrenchStandard European French / /
has not enjoyed a great deal of attention in phonological literature, especially
with regard to surface variations.[1] Approximant-fricative and voiced-voiceless
manifestations are discussed only cursorily, if at all, in the majority of works
on French phonology. The lack of interest in //
may stem from the relative stability of this segment or from French speakers'
lack of attention to variation, the exceptions being variants associated with
immigrants, older speakers and/or those from rural areas, contexts where apical
[r] is still attested. Other // alternations
are, however, of interest to the phonologist inasmuch as they demonstrate lenition
tendencies in French and provide examples of apparent free variation. The present
work describes one pattern of // variation,
voiced-voiceless and variable voice quality, where voicing and surface contrast
neutralization are analyzed as instances of passive lenition. Other issues raised
in the present work include the integration of phonetic principles in phonological
explanation, the justification for input or underlying representations of variant
phonemes and the heuristic capabilities of proposed constraints.
/
has not enjoyed a great deal of attention in phonological literature, especially
with regard to surface variations.[1] Approximant-fricative and voiced-voiceless
manifestations are discussed only cursorily, if at all, in the majority of works
on French phonology. The lack of interest in //
may stem from the relative stability of this segment or from French speakers'
lack of attention to variation, the exceptions being variants associated with
immigrants, older speakers and/or those from rural areas, contexts where apical
[r] is still attested. Other // alternations
are, however, of interest to the phonologist inasmuch as they demonstrate lenition
tendencies in French and provide examples of apparent free variation. The present
work describes one pattern of // variation,
voiced-voiceless and variable voice quality, where voicing and surface contrast
neutralization are analyzed as instances of passive lenition. Other issues raised
in the present work include the integration of phonetic principles in phonological
explanation, the justification for input or underlying representations of variant
phonemes and the heuristic capabilities of proposed constraints.
A first section of the paper comprises the presentation of
data relative to // variation and the
contrast of these data to other French continuants. In the second section, an
autosegmental analysis of // voice alternation
is provided and subsequently critiqued based on its inability to account for
these patterns. In the third section, discussion is turned to a lenition-based
approach and to the explanation of active and passive voicing. Here, the primary
goal is to demonstrate that alternations between voiced and voiceless //
are the result of principled phonological processes involving effort avoidance
and reduction, and to support a representation of //
that is unspecified for active glottal control. The fourth section turns to
articulation of grounded constraints and to the application of these constraints,
as well to as an explanation of what appears to be co-variation involving voiced
and voiceless // in word-final environments.
The concluding section comprises a discussion of the data and the conception
of voice as a phonological category.
// is a phonologically
unique segment in the inventory of Standard European French (henceforth French).
Phonetically, this sound may be classified as either approximant, fricative
or alternating between the two (Russell Webb 2002, MS; Ladefoged and Maddieson
1996: 232-236), whereas it is phonologically grouped as a liquid, most closely
related to /l/ (Walter 1977: 35-36; Casagrande 1984: 155; Walker 2001: 119).
This divergence of terminology has perhaps impeded the segment's study within
the phonological community. Liquid being a phonetically questionable term, whose
motivation lies not in production or perception, but in a history of prosodic
and phonotactic considerations, the present work ignores the traditional terminological
distinctions and approaches the question of //
and of similar consonants, /l/, /z/, /s/ and others, using the larger category
of continuants. By continuant, reference is made to those sounds produced in
the buccal cavity where the movement of articulator to articulatory target is
done without complete oral closure, i.e., the impedance but not arrest of egressive
pulmonic airflow (see Russell Webb 2002, Chapter 3, for discussion of the notion
of continuance).
// may occur in both
simple onsets and codas in French, but is marked with regard to licit and illicit
clusters in both onset and coda. It may occur only in the vowel-adjacent position
in complex onsets and codas or form an extra-syllabic unit when following an
occlusive in a coda (Dell 1995).[2] In addition to the distinctions noted in
Russell Webb (2002 and MS) between fricative and approximant, //
is voiced in intervocalic environments, in a complex onset consisting of a voiced
consonant and //, and in codas consisting
of the string // plus voiced consonant.
// is voiceless in complex onsets consisting
of a voiceless consonant or consonants and //
and in complex codas when adjacent to a voiceless consonant, either preceding
or following. Likewise, // is voiced
or voiceless when adjacent to heterosyllabic voiced or voiceless consonants,
respectively. While there is general AGREEment in the phonological literature
as to the contrast between voiced and voiceless //
in licensed clusters (i.e., CRV or VRC), the occurrence of this segment in extra-syllabic
(VCR) and in simple onsets and codas (RV and VR) is treated distinctly by different
authors (e.g., Tranel 1987: 142-143; Walter 1977: 36; Walker 2001: 136-139).
Synthesis of these data is presented in (1), below. It should be noted that
the greatest divergences of opinion with regard to //
voicing derive from observations of //
voicing in simple onsets; the present work will largely ignore this question,
although it is hoped further empirical evidence will be made available in the
near future.
/ voice
alternation in French ([v] = [voice])
Voiced [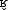 ] ] |
ira, paru, serrer |
voudriez, griller, brillant |
pardon, larguer, barbe |
Voiceless [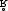 ] ] |
crie, patrie, proue |
parti, marquer, harpe |
quatre, capre, âcre |
| Voiced []
or Voiceless [] |
roule, rit, rat |
bar, cire, pour |
poudre, vibre, aigre |
Acknowledgement of the variability of //
voicing in the third row of (1) raises several questions, not only as to the
pragmatic context for one or the other variant - a question that will be ignored
in the present work - but also as to representation of //
in underlying form, for traditional analyses, or input, for Optimality Theoretic
(OT, Prince and Smolensky 1993) analyses and the ability of phonology to account
for free variation. These questions will be taken up in § 4 and 5.
The // complex onset
and coda patterns shown in (1) underscore an important generalization about
consonant clusters in French. No licit combination involving any continuant
and another consonant, in either onset, coda or heterosyllabic, shows tolerance
for voice contrast within clusters; this is true for all combinations, including
those marked as non-native (e.g., psychologie [psikolo i],
casba [kazba]), as well as affricates (e.g., exacte [egzakt],
Xavier [gzavje] or [ksavje], but *[gsavje] or *[kzavje]) and bi-syllabic
clusters (e.g., actif [ak.tif], adjoint
[ad.w
i],
casba [kazba]), as well as affricates (e.g., exacte [egzakt],
Xavier [gzavje] or [ksavje], but *[gsavje] or *[kzavje]) and bi-syllabic
clusters (e.g., actif [ak.tif], adjoint
[ad.w )]).
However, no other continuant exhibits the regular variability of //
with regard to the third instance of voice alternation, i.e., variability between
voicing and voicelessness, nor is intervocalic voicing a productive process
in modern French. Cursory data for all French continuants is provided in (2),
including examples of intervocalic stability of voiceless continuants. Note
that clustering constraints (irrelevant to the present discussion) result in
gaps or asymmetries in the data.
)]).
However, no other continuant exhibits the regular variability of //
with regard to the third instance of voice alternation, i.e., variability between
voicing and voicelessness, nor is intervocalic voicing a productive process
in modern French. Cursory data for all French continuants is provided in (2),
including examples of intervocalic stability of voiceless continuants. Note
that clustering constraints (irrelevant to the present discussion) result in
gaps or asymmetries in the data.
| |
|
|
|
| V__V | se] bouffer [bufe] boucher [bu 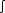 e] e] |
ze] couver [kuve] bouger [bu e] |
|
| # __ V | ] foule [ful] chaise [ z] |
 n] n] vous [vu] joue [ u] |
|
| V __ # | bouffe [buf] bouche [bu ] |
z] couve [kuv] bouge [bu ] |
|
| C [+v]__ # | lapse [laps] |
obs [obz] |
|
Data for continuant voice assimilation in (1) and (2) lead to the establishment of three distinct types of rules. The first of these concerns all continuant consonants in clusters, as in (3a) through (3d).
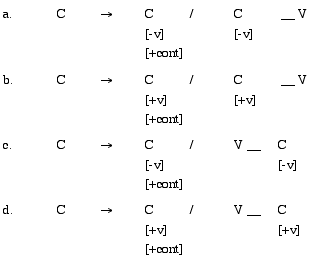
(3a) through (3d) assume that a continuant will assimilate
to the adjacent consonant in a cluster, either through a process of regressive
voice assimilation (in the case of VCC clusters) or progressive assimilation
(in the case of CCV clusters). While this assumption is tenable ipso facto in
the case of clusters involving //, the
lack of clusters such as *[kz] or *[gs] render these analyses vacuous, at best.
A second set of rules is evidenced by the data in (1) alone
and is specific to //. These rules involve
what has been traditionally considered passive voicing (as seen in 4a) and devoicing
(4b). A final series of rules, included for descriptive purposes only, is seen
in (5a) through (5c):
/-specific voicing rules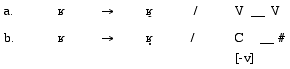 /-specific co-variation rules
/-specific co-variation rules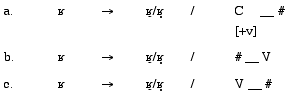
As mentioned above, these rules succeed in describing the phenomenon
of voicing specific to //, but do little
to promote an explanation of this behavior, nor to further understanding of
voicing in general.
Voice alternation has been widely treated from an autosegmental
perspective as a process of feature assimilation and/or contrast neutralization.
The assimilation-neutralization view has evolved to include specific structures
and widely-used constraints in its descriptions and explanations. This section
provides one autosegmental analysis and highlights several of the theoretical
and heuristic shortcomings of this approach, both in general and with regard
to data on French //. These will be contrasted
to a lenition-based account of the phenomenon, provided in § 4 and 5.
Crucial to any autosegmental approach to phonological processes
is the assumption and manipulation of features (Chomsky and Halle 1968) and
geometric representations (Clements 1985). These presume that specific features
of segments may interact independently of the segment itself, according to principles
of strict layering. In the case of voice assimilation and contrast neutralization,
the voice feature [ voice] of segment X may
spread to segment Y, as in (6a) and (6b), for progressive and regressive voice
assimilation, respectively. Note that these geometric representations are simplified
and include only the manner node.
voice] of segment X may
spread to segment Y, as in (6a) and (6b), for progressive and regressive voice
assimilation, respectively. Note that these geometric representations are simplified
and include only the manner node.
(6) Autosegmental geometric patterns of assimilation
a. Progressive voice assimilation
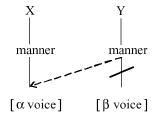
b. Regressive voice assimilation
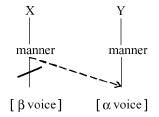
The autosegmental approach presents a distinct advantage over more cumbersome, rule-based descriptions; namely, this model makes explicit the process by which one feature can be shared or transferred across segments, without effect on other features, and captures a greater number of generalizations that need not be specific to individual segments.
Applied principally to word-final and syllable-final consonant devoicing, Lombardi (1994, 1995a and b, 1998, 1999, 2001) uses geometric representations and proposes a laryngeal feature (LAR), dominated by the root node, in her explanation of patterns of voice neutralization and assimilation. She asserts that, in languages such as Dutch, Yiddish and Polish, LAR voice neutralization in syllable codas is the result of a licensing constraint, whereby LAR is an allowable feature only in segments preceding a sonorant, as in (7).
(7) Lombardi's Laryngeal Constraint (1999:267, her Figure 1)
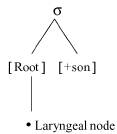
Lombardi (1999, 2001) also posits LAR as being a privative feature; a voiced obstruent contains the feature [voice] under the laryngeal node, whereas a voiceless segment lacks this structure entirely, therefore this specification (2001:9). In the case of positive voice assimilation, where a voiceless segment becomes voiced, laryngeal features are shared; in the case of devoicing or negative assimilation, LAR is "delinked," implying the loss of featural specification. Using notation similar to Lombardi - albeit in simplified figures lacking full geometric notation - the rules of (3b) and (3d) may be reformulated to account for progressive and regressive assimilation, as in (8a) and (8b). The reader will note that the latter figure assumes that the constraint of (7) is not highly ranked in French.
(8) Rules for cluster voice assimilation (simplified)
a. Progressive, positive voice assimilation
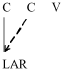
b. Regressive, positive voice assimilation
The rules of (8) account for //
cluster voicing in such examples as dragon [dag)]
and pardon [pad)].
These are also adequate descriptions of a larger phonological process in French,
whereby voice contrast is prohibited in obstruent clusters. (8a) and (8b) are
positively-stated rules; in the case of voiceless obstruent + []
clusters, they are inoperative. This does not, however, pose an immediate problem
and correct outputs may be obtained, as no LAR feature has been specified in
the input or underlying form of //.
Foundational to Lombardi's analysis of voice assimilation and neutralization is the observation that obstruents in the onset show a marked tendency to preserve an assumed input laryngeal specification, whereas obstruents in codas demonstrate an equally marked tendency to lose any such specification. In an OT framework, this is accounted for with a series of markedness and faithfulness constraints. The former prohibit cluster contrast and penalize LAR in post-sonorant positions; the latter specify input-to-output laryngeal feature identity and promote such identity in pre-sonorant positions. These are provided in (9) and (10).
(9) Markedness constraints
*LAR: Do not have Laryngeal features (1999:271, her 5)
AGREE: Obstruent clusters should AGREE in voicing (1999:272, her 6)
(10) Faithfulness constraints
IDONSLAR: Consonants in the position state in the Laryngeal Constraint should
be faithful to underlying laryngeal specification (1999:270, her 3)
IDLAR: Consonants should be faithful to underlying laryngeal specification (1999:270,
her 4)
Note that faithfulness constraints in (10) do not distinguish between input-output maximization and dependency, as in the MAX and DEP family of correspondence constraints (McCarthy and Prince 1995), but are stated in such a way as to promote absolute faithfulness.
Unlike the languages studied by Lombardi, French has little
word compounding or inflexion resulting in the obstruent concatenation, the
notable exception being the prefixes such as trans-. In these situations,
where the status of the prefix as a distinct phonological word is dubious (and
beyond the scope of the present work), regressive voice assimilation occurs
and voice contrast is neutralized, as in transvaser
[tzvaze]
(compare to tranférer [tsfee]).[5]
IDLAR is thus lower ranked with regard to both AGREE - prohibiting cluster contrast
- and IDONSLAR - penalizing output such as *[sf] and promoting [zv]. Likewise,
examples such as those provided in (2) imply a low-ranking *LAR constraint in
this analysis, as the asserted laryngeal feature is clearly permitted in the
coda (e.g., base [baz]). (9) and (10) are thus ranked {
AGREE, IDONSLAR >> IDLAR, *LAR}. Interaction of these constraints predicts
the correct output for obstruent clusters in French, as in (11).
| ts
+ vase |
AGREE | IDONSLAR | IDLAR | *LAR |
| tsvase |
*! | * | ||
| tsfase |
*! | * | ||
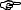 tzvase tzvase |
* | ** | ||
| tzfase |
*! | ** | * |
This approach encounters three distinct but related problems
with regard to //, however: //
voicing in intervocalic environments and the phonotactic distinction of //
with regard to all other continuants, none of which undergo such intervocalic
voice alternations; output selection in the case of //
+ voiceless obstruent clusters, both RC and CR; and co-variation involving voiced
and voiceless //, most notably in word-final
CR clusters where the preceding obstruent is voiced. These problems refer directly
to the issue of // featural specification.
Were the representation of // to include
LAR, then assimilation to voiceless obstruents must be motivated; were representation
to exclude this feature, intervocalic and variable word-final - both absolute
and CR - voicing must be explained. With regard to the latter, the assimilation-neutralization
approach should respond to the foundational questions of cluster AGREEment and
word-final voice markedness with the theoretical imperative of motivated constraints.
At first glace, evidence supporting //
representation including LAR seems straightforward. Most literature on French
refers to devoicing, i.e., the loss of featural specification in the output,
rather than the reverse (Casagrande 1984: 52-53, Valdman 1976: 90-92). Assertion
of a laryngeal voice specification for //
solves one issue raised above, intervocalic voicing, as devoicing in examples
such as ira would be blocked by IDONSLAR, providing [ia]
and not *[ia]. This assumption also
predicts the correct output for voiceless obstruent + //
clusters, such as parti and patrie. In the latter case, the lower-ranked
*LAR constraint is crucial to the generation of the correct output; this cross-linguistic
markedness constraint provides the mechanism by which onset devoicing is preferred
to onset voicing. Examples are provided in (12).
/ + voiceless
obstruent devoicing| pa.ti |
AGREE | IDONSLAR | IDLAR | *LAR |
| pati |
*! | * | ||
| i |
* | * | ||
| padi |
* | * | **! | |
| padi |
*! | ** | ** | * |
| pa.ti |
||||
| pati |
*! | * | ||
| ti |
* | |||
| padi |
*! | * | ** | |
| padi |
*! | * | ** | * |
This assumption encounters difficulties with regard to instances
of free variation. Ignoring for the moment the case of word-initial //,
two instances of apparent free variation between []
and [] must be addressed, VR and VCR
where the preceding obstruent is voiced. Data in Russell Webb (2002, Chapter
3) suggests that devoicing is a more frequent occurrence than is voicing (or,
assuming LAR specification, the delinking of the laryngeal node) in both instances,
although this should be viewed as a tendency only among the subjects included
in that study. Rather than dismiss this as surface variability, I propose that
phonological theory should be able to describe, if not explain such data; in
the case of an OT approach, this implies the generation of co-optimal candidates
whose evaluative score is equal.
Within the assimilation-neutralization approach, position of
//-voice specification cannot positively
respond to this proposal, specifically with regard to free variation. In the
case of word-final devoicing, there is no means by which to predict optional
LAR delinking in the case of bar ([ba]
or [ba]) and the required maintenance
of LAR in the case of base ([baz], *[bas]) or balle ([bal], *[ba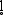 ]).
A strict ranking of IDLAR >> *LAR might provide the correct output in
the latter examples, but prohibits the possible - if not preferred - [].
Apparent free variation in post-voiced-obstruent, word-final position provides
an even more difficult challenge to this approach. This is demonstrated in (13),
where the use of double
]).
A strict ranking of IDLAR >> *LAR might provide the correct output in
the latter examples, but prohibits the possible - if not preferred - [].
Apparent free variation in post-voiced-obstruent, word-final position provides
an even more difficult challenge to this approach. This is demonstrated in (13),
where the use of double indicates the more
frequent output for the input cadre.
/
word-final free variation, LAR-specified| kad |
AGREE | IDONSLAR | IDLAR | *LAR |
| |
** | |||
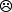 kad
kad |
*! | * | * | |
| kat |
*! | * | * | |
| kat |
**! | ** |
Constraint ranking as in (13) not only fails to predict the
optimality of candidate [kad], but provides
that this candidate, which should be optimal, is evaluated as equally suboptimal
as the unattested [kat] and that, in
response to laryngeal markedness constraints (those that are crucial to selection
in (12)), [kad] is equal to [kat].
A potential resolution to this problem is the assumption that
// includes no laryngeal feature, i.e.,
no voice quality is assumed for // representation.
This implies the assimilation, either regressive or progressive, of voice quality
by adjacency, an assumption that poses no problems for examples such as très
[t], but provides an incorrect
output for examples such as gris [gi],
as in (14).
/ assimilation
assuming //
without input LAR| te |
AGREE | IDONSLAR | IDLAR | *LAR |
| e |
||||
| te |
*! | * | * | * |
| de |
*! | * | * | * |
| de |
**! | ** | ** | |
| gi |
||||
| gi |
*! | * | ||
| i |
* | * | **! | |
|
ki |
* | * | ||
| ki |
*! | ** | ** | * |
In addition to incorrect prediction of (14), problems similar
to those obtained with the assumption of //
LAR specification emerge from this counter-assumption, namely the difference
between // and other continuants lacking
LAR in intervocalic environments and the question of free variation. Were the
representation of // to be specifically
stated as absent of laryngeal specification, as would be the representation
of /s/ and /f/, then any proposed constraint ranking should effect these segments
in the same manner. This is not borne out in the data, however, as is seen in
examples pousser [puse] and bouffer [bufe], where no laryngeal
features are assimilated to the continuant, but where the reverse must be true
for bourrer [bue] (*[bue]).
This might well be resolved by the inclusion of an //-specific
constraint on intervocalic laryngeal spreading; such a solution is critiqued
below.
The second problem encountered by the assertion of //
representation lacking laryngeal features derives from data shown in (13). Were
// to specifically lack LAR, there would
be no means by which to capture the co-optimality of candidates, as in (13').
/
word-final free variation, LAR-unspecified| kad |
AGREE | IDONSLAR | IDLAR | *LAR |
| |
** | |||
|
kad |
*! | * | * | |
| kat |
*! | * | * | |
| kat |
** | ** |
Here again, assumption of //
representation unspecified for LAR fails to capture the co-optimality of two
candidates and, even if such covariance is to be considered gradient, obtains
only one of the two candidates actually supported in the data.
Without modification, this approach cannot account for //
voicing data in French, whether obligatory or optional and indifferent of assumptions
as to the input representation of //. One potential
resolution to the problem is seen in Wetzel and Mascaró (2001), who assert
voice to be a binary quality. Constraints involving laryngeal faithfulness may
thus be restated as voice-faithfulness (e.g. IDONSVOICE
for IDONSLAR; 2001: 213), with little change to
the approach articulated above (for examples cited in French, at least; Wetzel
and Mascaró focus on typologically different data). Assuming that all
continuant segments were specified as either voiced or voiceless does not resolve
the questions posed above, as // must also enjoy
a representational specification for any binary voice feature. In essence, the
same problems encountered with Lombardi's privative LAR will be encountered
with Wetzel and Mascaró's binary [voice]: there is no way to account
for processes relative to // voicing and devoicing
without the position of -specific constraints.
As tempting as it may seem to introduce a family of constraints
specific to //, I assert that such a
solution does not constitute a theoretically motivated means by which to describe
and explain phonological data. Introduction of a segment-specific rule does
nothing to promote understanding of phonological grammars, but subtracts from
the heuristic power of linguistic theory; an //-specific
rule would provide no more of an explanation of this phenomenon than would the
traditional "slash-dash" rules given in (3), (4) and (5). A motivated explanation
of this phenomenon must be able to explain the processes operating on the linguistic
system with regard to all segments and allow for //
to behave differently than other continuants.
Russell Webb (MS) demonstrates that gradient no-effort constraints
can account for alternations between fricative and approximant variations of
// and views this as a case of lenition
by position. In many respects, fricative-approximant variation is a more transparent
instance of lenition, with clearer positional contrasts between fortis [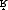 ]
and lenis [
]
and lenis [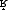 ] allophones. Voice
alternation is more complex, as syllabic position would appear to be less important
for output generation than are linear adjacency and clustering. Discussion of
lenition as effort avoidance in the case of voice alternation must take positional
and transitional rules into account and motivate //
with reference to both. Additionally, the question of apparent free variation
remains a troubling point for any explanation. A lenition approach must resolve
the issue of // voice representation,
i.e., voice quality as an integral part of input or underlying form, in such
a way that does not necessitate //-specific
markedness constraints for the description and explanation of either voicing,
devoicing or free variation.
] allophones. Voice
alternation is more complex, as syllabic position would appear to be less important
for output generation than are linear adjacency and clustering. Discussion of
lenition as effort avoidance in the case of voice alternation must take positional
and transitional rules into account and motivate //
with reference to both. Additionally, the question of apparent free variation
remains a troubling point for any explanation. A lenition approach must resolve
the issue of // voice representation,
i.e., voice quality as an integral part of input or underlying form, in such
a way that does not necessitate //-specific
markedness constraints for the description and explanation of either voicing,
devoicing or free variation.
Lenition is frequently used in phonology to describe any assumed default to an easier or simpler articulatory effort and, as such, is often construed with notions of weakening, this without any direct statement of what is meant by either lenition or weakening. In many diachronic works, such terminology is accepted ipso facto and no grounding or motivation is offered (see Bauer 1988 for a more complete critique of traditional lenition-based accounts). The idea of ease-of-effort as a principle involved in language variation (especially diachronic data) is hardly innovative: in the late nineteenth century, Paul Passy proposed contrasting notions of economy and emphasis as the competing forces underlying language change (1891: 146-147, 150-153). Early functionalists, such as André Martinet, were inspired by the biomechanical work of Zipf (cf. 1949) and considered weakening as a movement lacking in precision whose result is a less-than-ideal acoustic signal (cf. Martinet 1955). A complete understanding of lenition suffered from a lack of precision in these early works, in which effort was often no more than an impressionistic notion and was not grounded in evidentiary data external to both the specific language under study and to speech mechanisms in general.
Articulatory phonology (AP, Browman and Goldstein 1989, 1990,
1992) integrates the contrastive productive properties of sound segments and
has been used to account for phonological behavior such as lenition. Here, the
basic units of phonological organization are not features, but gestures, abstracted
characterizations of articulatory events. In contrast to autosegmental approaches,
where features of a segment may influence those of a second segment, AP allows
for the overlap of gestures over time (Browman and Goldstein 1992: 155-156).
A specified gesture of segment X (
(X)) overlap the production of segment Y and, eventually, positively or negatively
influences the production of gesture 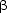 (Y), this
with or without effect upon gestures
(Y), this
with or without effect upon gestures 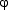 (X),
(X),
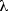 (X), etc. The concatenation of segments is
provided in scores, schemata of specific gestures and tract configurations,
arranged on a vertical axis, in which the duration of gestures is represented
on a horizontal, temporal axis.
(X), etc. The concatenation of segments is
provided in scores, schemata of specific gestures and tract configurations,
arranged on a vertical axis, in which the duration of gestures is represented
on a horizontal, temporal axis.
In AP, consonant voicing is described by means of the glottis tract variable. This is meant to reflect the phonetic properties of voiced and voiceless sounds; during pulmonic egression, voicelessness is maintained by a wide or spread glottis, a gestural effort impeding the vibration of vocal folds. Browman and Goldstein assume voicelessness, rather than voicing, implies additional gestural specification and use the notation "wide glottis" in their gestural score; voicing is represented by the absence of a glottal gesture (cf. 1992: 158-159). The reader will note that this assumption stands in opposition to Lombardi's assumption that voicelessness is structurally unmarked, as captured in a lack of laryngeal feature specification and in the *LAR constraint.
Considered from an articulatory phonological standpoint, //
voicing is approached as an alternation between scores containing and lacking
the gesture spread glottis. Scores in (15) provide simplified gestural scores
for intervocalic // in contrastive environments;
I have omitted gestural information not relevant to the present discussion (e.g.,
vowel information).
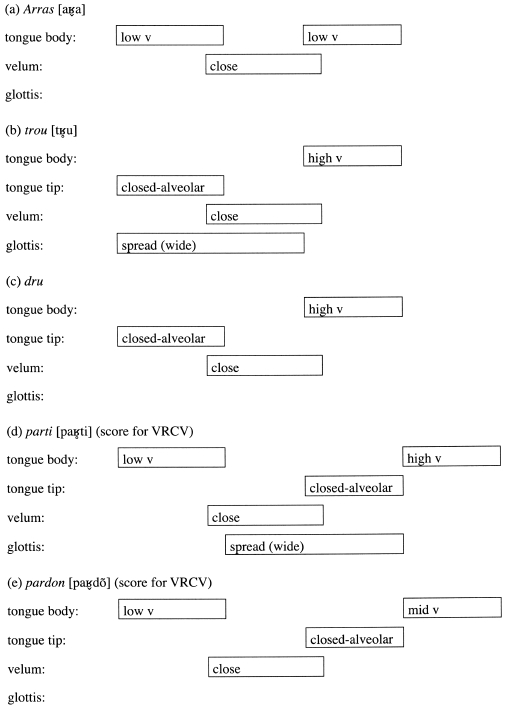
From an AP perspective, lenition is then a simplification of
the gestural score. Any loss of gestural specification or any temporal reduction
of a given gesture results in a less complex score and in reduced articulatory
effort. This model provides an effective means of describing the interaction
of gestures and the influence of one segment's gestural representation on that
of a second one. Such an approach might provide an adequate framework for the
generation of no-effort constraints in specific environments, impeding for instance
[] in intervocalic environments such
as (15a). This does little to further discussion of examples seen in (15b) through
(15e), however, let alone other examples in (1), the gestural scores of which
have not been presented here.
Clearly any lenition-based account must develop a greater understanding of the phonetic principles implied by the notion of weakening, as well as the contrary conception of fortition or strengthening. Ideally, these should be integrated into a phonological framework, one which takes such principles into account but expresses these in terms of regularities useful for output generation in such a way that explains "what is happening" in a given language, rather than merely "what has happened." The present analysis borrows heavily from Kirchner (1998, forthcoming), where effort is gradient and constraints against effort affect a given segment differently, depending upon positional factors. Kirchner's approach makes a direct reference to the integration of phonetics in an OT framework, i.e., notions of well-formedness and constraints based upon principles of phonetic optimization (1998: 24). He also incorporates the mechanical notion of force with that of precision of effort and makes an important distinction between active and passive effort reduction, i.e., those productive operations that explicitly seek to achieve effort reduction and those that are accomplished implicitly (58). The following provides a brief, if not simplistic overview of voicing and its relation to articulatory effort and effort reduction or lenition; for more complete discussion of these ideas, the reader is referred to the cited works.
The phonological notion of voice quality refers to the configuration of the glottis during articulation; the glottis is adducted or drawn together during the production of voiced sounds and abducted or drawn apart during that of voiceless sounds. Mutatis mutandis, a relative degree of voicing will occur during normal, unobstructed pulmonic egression. Voicing will fail, however, when sub-glottal pressure is significantly lower than supra-glottal pressure or when supra-glottal pressure is significantly higher than that present in the sub-glottal cavity; both states of affairs will result in the passive abduction of vocal folds or the widening of the glottis (see Stevens 1998: 80-82 and 465-485 for complete discussion of the conditions for vocal fold abduction and adduction). Occlusives provide for either complete closure or a close aperture in the vocal tract, the result of which is a marked increase in supra-glottal pressure. This has been advanced as one phonetic correlate of the phonological observation of patterns in the world's languages, where voiced occlusives - especially voiced fricatives - are marked (Ohala 1997: 687-89; 1983).
The production models of Westbury and Keating (1986) and Kirchner (1998) model linear articulatory efforts in characterizations of consonant voicing and explanation of ease of articulatory effort with regard to the voice quality of consonants. Here, articulatory effort refers to the velocity of articulatory transitions - changes in a string of controlled states over time - in which less velocity implies less effort. The results of Westbury and Keating, especially, parallel certain regularities observed in languages. In the case of intervocalic fricatives, a voiceless fricative implies greater articulatory effort, as the glottis must be spread in the environment of voiced sounds in order to avoid a change in sub-glottal pressure, by which the passive adduction of vocal chords (and their subsequent vibration) would occur. Avoidance of intervocalic voiceless obstruents thus results in the reduction of positive transitional effort (Westbury and Keating 1986: 149-152). This corresponds to the gestural score in (15a) and is commonly termed passive voicing (Kirchner 1998: 54-55).
By contrast, sub-glottal pressure decreases in the production of word-final and, especially, utterance-final obstruents. Here, two factors are at play in the promotion of vocal fold abduction: an increase in supra-glottal pressure caused by occlusion and a corresponding decrease in sub-glottal pressure, perhaps exacerbated by the end of pulmonic egression and the need to breathe. With final occlusives, unconstrained pressure differentiation provides for the passive abduction or spreading of the glottis, impeding vocal fold vibration (Westbury and Keating 1986: 156-157, Kirchner 1998: 56-58). Similar patterns are evidenced with regard to fricatives by Ohala (1997, 1983). All other input variables being equal, which is a principal assumption of both Westbury and Keating and Kirchner, this state of the vocal tract results in passive devoicing. Final devoicing as a means of effort reduction is also supported by data demonstrating that post-vocalic instantiations of voiced consonants are longer than those of voiceless ones (cf. Dunn 1993, Maddieson 1997). In this instance, effort reduction is predicated upon the assumption that articulatory effort is greater during a relatively longer occlusion.
The avoidance of voice contrast in obstruent clusters provides a final example of effort reduction, whether this be passive voicing or devoicing, as the transition between abducted and adducted glottis (or the reverse) implies an increase in transitional articulatory effort, in opposition to either the maintenance of one glottal configuration during the production of both sounds. Neither model discussed here provides convincing evidence that voicing or voicelessness is, ceteris paribus, a more natural outcome in such environments, although both support neutralization of contrast as an expression of effort reduction. Any statement of positive effort reduction or of effort avoidance in these instances must therefore refer to the psychological input variables associated with the respective sounds, i.e., the representation of the consonants in the cluster, and to the perceptual penalties output differentiation of these representations might engender.
With regard to French //
+ occlusive clusters, effort reduction by avoidance of contrast - for simplicity's
sake, neutralization - is accomplished via //
voice alternation, and not the reverse. When the stop is voiceless, the glottis
is abducted prior to (in the case of fricative-stop) or remains abducted after
(in the case of stop-fricative) oral closure is achieved; when the stop is voiced,
the glottis either adducts prior to closure or remains adducted after release.
An account of cluster voicing in this instance must assume one of two possibilities:
that the voice quality of the occlusive, as contained in its representation,
is of greater importance than that of //,
or that // is lacking explicit representation
- and, as such, positive psychological control of gestural coordination - with
regard to the abduction or adduction of the vocal folds.
Taken to its most extreme, if effort reduction were not limited, spoken language would simply cease to exist, as complete elision would always obtain the ultimate in effort avoidance. Human language mitigates the natural processes of effort reduction in many ways and for reasons beyond the scope of the present work. Both Kirchner and Westbury and Keating describe a state of affairs where no positive control is exerted over the glottis and where passive voicing and voicelessness are unconstrained. Such neutrality of the input, where no independently controlled, non-productive variables are assumed, does not take into account mechanisms that can promote voicing in environments where passive devoicing might otherwise be operative or those that can promote voiceless segments in passive voicing environments. In addition to the passive mechanisms discussed above, voicelessness or glottal abduction can be accomplished by activation of the posterior cricoarytenoid, whereas voicing or adduction are obtained by activation of the interarytenoid, the lateral cricoarytenoid and the thyroarytenoid (Hirose 1997: 125). Examples from languages having intervocalic voiceless obstruents and/or word-final voiced obstruents (including the language in which this article is written) demonstrate that these gestures are possible and not at all uncommon, even at the cost of greater articulatory effort.
Clearly considerations of passive voicing mechanisms cannot fully account for patterns observed in French or any other language. Phonology must contain not only constraints reflecting these mechanisms, but constraints allowing for active voicing (e.g., voiced obstruents in word-final positions) and active voicelessness (e.g., voiceless intervocalic obstruents) when these qualities constitute part of a segment's input representation, i.e., its psychological reality. I assume that phonology must therefore recognize three representational types with regard to voice: those comprising the notion of voicing, those comprising the notion of voicelessness, and those comprising no notion with regard to the state of the glottis and the resulting voice quality. This approach stands in opposition to both the privative LAR of Lombardi and the binary [voice] of Wetzel and Mascaró.
In languages such as French, where voiced and voiceless obstruents
(both occlusives and continuants) are permitted in all positions, active adduction
and abduction of the glottis is clearly part of the psychological reality of
certain segments. Even in instances that would otherwise promote the passive
voicing or devoicing of phonemes such as /s/ or /z/, respectively, this process
is blocked and the input glottal gesture is maintained. The need for input-output
faithfulness and the perceptual need for ease-of-recognition (i.e., for the
avoidance of confusion) must therefore outweigh both passive voicing and devoicing
in these cases, where passive lenition is rendered inoperative. The same lack
of variation is not observed in the case of //;
the data shows no instance where passive voicing is overridden by activation
of glottal muscles. In essence, the natural tendencies of the glottis are unconstrained
during the production of // in all environments.
This provides convincing evidence for //
lacking any voice specification in its representation, either as active glottal
abduction or adduction. Given this assumption, //
is the only French consonant whose representation contains no explicit representation
of a glottal configuration.[6] This theoretical assumption - that the representation
of // is void of all laryngeal or voice
specification - renders the distinction between privative and binary specification
moot, at least in this instance. In effect, the correct output is predicted
without any specific reference to input specification; in the case of all other
continuants, such as /s/ and /z/, it is not necessary to posit a specific laryngeal
or voice structure, as output is obtained by the mechanism for input-output
faithfulness correspondence. This reflects Kirchner's position that the enrichment
of phonological representations, incorporating greater phonetic detail, and
the incorporation of these in a phonological grammar consisting of motivated
markedness and faithfulness constraints eliminate much of the need for a restricted
set of contrastive features (cf. Kirchner forthcoming).
Rather than refer to a fixed lenition paradigm, this phenomenon
is construed as a flexible mechanism promoting effort reduction, implying context-dependent
voicing or voicelessness. This approach, which recognizes both passive and active
glottal mechanisms as potential sources of voice quality, allows for the distinction
between lenition by design (active) and lenition by default (passive). In the
case of //, it seems most plausible to
refer to passive lenition, unconstrained by any gestural representation in the
input that might work against default effort reduction in specified gestural
sequences. Such a conception of lenition also highlights the competing forces
operating on // in two environments where
free variation is attested - in word-final and extra-syllabic positions (following
a voiced stop) - where conditions are favorable for both passive voicing and
voicelessness. The ensemble of lenition processes are exemplified in (16), accounting
for both obligatory and facultative voice alternations.
| |
|
|
| C[+v] R V (broue) | ] |
|
| V R C[+v] (barbe) | ] |
|
| V R V (ira) | ] |
|
| C[-v] R V (prie) | |
] |
| V R C[-v] (harpe) | |
] |
| V C[-v] R (capre) | |
] |
| V C[+v] R (vibre) | ] |
] |
| V R (par) | ] |
] |
The competing needs for precision, such as the correspondence between input representation and output form, and ease of production, exemplified by effort reduction as passive voicing and devoicing, underscore the tug-of-war at play in speech production. Rather than merely describe the output of these contrasting forces, I assert that phonology should explain the interaction of these variables and do so in a manner that reflects the interaction of mechanisms involved in the evaluation of candidates, rather than merely the generation of output. This assertion refers directly to the heuristic potential of phonological analyses and takes advantage of the theoretical and methodological tenets of OT, namely that a grammar is the product of constraint interaction, rather than constraint ranking alone. In opposition to previous phonological theories where rules were applied sequentially, OT allows for the concurrent application of constraints promoting both precision and effort reduction.
Kirchner's examination of lenition provides for the application of effort avoidance and effort reduction with the LAZY family of markedness constraints (1998, forthcoming). Effort reduction may be expressed locally - i.e., in reference to specific gestures and/or gestural configuration - or absolutely; this may also be accomplished gradiently, where effort is not absolute but incremental. LAZY refers directly to the phonetic correlations of speech production, rather than to an assumed structural reality, and provides for the inclusion of specific biomechanical principles. In opposition to absolute structurally-driven constraints (such as *LAR, which prohibits all laryngeal features, i.e., voicing), LAZY refers directly to the act of speech production and states that, ceteris paribus, effort is avoided. This may imply the loss of features, but it might well also imply the introduction of features. In essence, LAZY recognizes the multiplicity of potential effort reduction and avoidance mechanisms.
Concern in the present work is with the expression effort avoidance and reduction as it applies to the state of the glottis. A markedness constraint working against active control of glottal gestures promotes context-dependent passive voicing and/or voicelessness. Faithfulness constraints must also be specified in order to preserve voicing in those environments where effort expenditure is preferred over effort reduction as a means of preserving input glottal representation. Effort-based markedness and faithfulness constraints are given in (17) and (18), respectively.
Given the assumption that //
is lacking in glottal representation, but that all other consonants, including
continuants, contain a glottal gesture in their representation, the ranking
PRES(glot) >> LAZY(glot) predicts the correct output in all instances
where // is either voiced or voiceless,
as shown in (19). This ranking also avoids problems encountered with the feature-based
account of devoicing explored in § 3, as glottal gestural specification
is assumed to be present in the input of other consonants, whether considered
voiced or voiceless under the aforementioned approach. Note that this analysis
assumes a higher-ranking preservation constraint penalizing elision (refer to
Russell Webb, MS, for discussion of effort reduction expressed through elision).
| ia |
|
|
| a |
||
| ia |
|
|
| bij |
||
| ij |
||
| bij |
|
|
| pij |
|
|
| ki |
||
| ki |
|
|
| i |
||
| gi |
|
LAZY(glot) captures the principle of effort reduction (as either passive voicing or voicelessness) within a singular constraint and does so with reference to the biomechanics of speech production, rather than to abstract feature specificity.
As stated in both § 3 and 4, any theory whose goal it is to describe and explain variation should also be able to account for instances of co-variation, in this instance in absolute and post-voiced-occlusive, word-final environments. In each of these, passive lenition implies dual, contradictory forces operating on the glottis. On the one hand, transition from an adducted (of either the preceding vowel, e.g., par, or consonant, e.g., cadre) to an abducted glottis would imply active control of glottal muscles in order to achieve voicelessness; maintenance the adducted glottal configuration would seem therefore to be an instance of passive lenition. However, constriction in the buccal cavity results in a difference in sub- and supra-glottal pressure, initiating the passive abduction of the glottis and resulting in voicelessness; from this viewpoint, gestural transition from adducted to abducted glottis is also a case of passive lenition.[7]
As presented above, distinction must be made between active control of the glottis and the two passive glottal mechanisms, abduction (promoting voicelessness in specific situations) and adduction (promoting voicing in specific situations). The previous unary LAZY constraint of (17) may be reformulated to capture the complementary - and sometimes competing - mechanisms of passive effort reduction, as in (17').
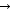 passive
voicing)
passive voicelessness)
passive
voicing)
passive voicelessness)Assuming no intervening variables, such as length of occlusion,
prosody or utterance-level transitions (i.e., those between the final //
and a following glottal configuration or, in the case of utterance-final instantiations,
the lack thereof), the interaction of these constraints captures the duality
of passive lenition mechanisms at play with regard to French //.
The tableau in (20) provides two examples of free variation and overcomes the
problems encountered by the autosegmental approach, as seen in (13), (13') and
(14).
| pa |
|
|
|
| |
|||
| |
|||
| kad |
|||
| |
|
||
| |
|
||
| kat |
|
|
|
| kat |
|
|
Note that violations of LAZY(glot-adduct) and LAZY(glot-abduct)
in the case of cadre /kad/ stem
from active control for glottal adduction of [d] or [t] (as well as for the
transitional effort in the sub-optimal and unattested [kat]).
Because the LAZY constraints of (18') are stated negatively, as an expression
of passive effort avoidance, rather than as an explicit promotion of passive
lenition, the co-optimal candidates of (19) are co-optimal with regard to effort
reduction, i.e., they are not equally bad, but equally good. This is a crucial
theoretical point to be made: for OT to effectively deal with instances of co-optimality,
optimality should be achieved not through violation but through satisfaction
of constraints. That is, if two products of GEN are co-optimal, they should
be so with regard to their respect, rather than violation of the relevant constraints.
The description and explanation presented here promotes a view
of // voicing as one instance of passive
lenition. This approach accounts for voice variation as the outcome of effort
reduction where no input, representational variables are present to counter
active voicing or voicelessness. Biomechanical principles are captured in the
grammar as markedness constraints - LAZY(glot) - crucially dominated by the
faithfulness constraint PRES(glot). Given //
representation assumptions, LAZY and PRES predict the correct output in instances
of voicing and voicelessness and positively express the contrastive forces at
play in co-optimality. The gestural approach also presents the distinct advantage
of being grounded in phonetic evidence and in notions of transitional and positional
effort reduction with regard to glottal gestures.
The analyses of this work challenge structural accounts of similar language data, where voice is conceived of as a universally marked feature. Rather than simply assert that voicing should, ceteris paribus, be avoided, as in the autosegmental analysis seen in § 3, the lenition approach asserts that both voicing and voicelessness may obtain from effort reduction. An additional theoretical diversion from autosegmental accounts is noted in the conception of segments and their representations. These approaches construe voicing as either a binary or privative feature, expressed within a structural geometry of distinctive features; in the approach advocated herein, voicing is conceived of in a manner more closely resembling the phonetic properties of this phenomenon, i.e., as a state of the glottis. This glottal state may be an intrinsic component of representations - e.g. /z/ and /s/ in French - or may be absent therefrom. As such, voice quality emerges from the interaction of dual linguistic mechanisms, the first mechanical (active and passive activation or non-activation of the glottis) and the second psychological (lexical representation promoting activation or allowing non-activation of the glottis).
Other instances of voicing alternation in French highlight
the advantages of this approach. One of these, optional sibilant devoicing,
is mentioned briefly in § 5; others examples include historical lenition
and examples of word-final elision, this being the unconstrained product of
effort reduction. The explanation of //
voicing promoted here underscores the need for more investigation of these and
other phenomena in French and other languages, as well as the enlargement of
the proposed constraints to include other manifestations of principled effort
reduction in phonological grammars.
1 The IPA symbol , officially
designated as a voiced uvular fricative, is here used in reference to a uvular
or uvulo-velar fricative or approximant of indeterminate voice quality (specification
for voiced and voiceless segments is provided with subscripts, as []
and [], respectively). [back]
2 Dell 1995 treats instances described here as extra-syllabic as being the onset to a deficient syllable. The reader is referred to this work for full discussion of the issues of word-final extra-syllabicity and syllable deficiency. [back]
3 The reader is reminded that gemination is prohibited in
Modern French (with the questionable exception of //
in bi-morphemic environments, e.g., mourra [mu:a]),
as are clusters of non-continuant obstruents. [back]
4 Word-final voiced consonant-/l/ clusters are often articulated
with an epenthetic schwa, e.g. table [tabl ].
Dell (1995) presumes this to be evidence for the multi-syllabicity of such words,
which are to be analyzed as [ta.bl] at the
input or underlying level (18-24). Likewise, the extra-syllabic segment may
be elided in fast or informal speech, as in [tab]. [back]
].
Dell (1995) presumes this to be evidence for the multi-syllabicity of such words,
which are to be analyzed as [ta.bl] at the
input or underlying level (18-24). Likewise, the extra-syllabic segment may
be elided in fast or informal speech, as in [tab]. [back]
5 Dell (1995) does not specifically address the issue of
clustering due to affixation, but states that no clustering of the type *[sv]
is allowed. An alternative analysis accounting for attested instances of [s]
maintenance in this example assumes distinct phonological words, as in [(ts)PW
(vaze)PW], the boundaries of which block assimilation. [back]
6 Instances of passive devoicing, especially in word-final position, are not uncommon among French speakers, especially in the case of sibilants (cf. Russell Webb 2002). [back]
7 While other factors, including the distinction between word- and utterance-final position and the control of airflow in these instances should be taken into account, a paucity of relevant data would render a conclusion in this regard tenuous, at best. For the moment, it is sufficient to demonstrate grammatical accommodation of co-variance; it is hoped that future work will contribute to this discussion. [back]
Bauer, Laurie (1988): "What is lenition?". Linguistics 24: 381-392.
Browman, Catherine/Goldstein, Louis (1989): "Articulatory Gestures and Phonological Units". Haskins Laboratories Status Report on Speech Research SR99/100: 69-101.
Browman, Catherine/Goldstein, Louis (1990): "Gestural specification using dynamically-defined articulatory structures". Journal of Phonetics 18: 299-320.
Browman, Catherine/Goldstein, Louis (1992): "Articulatory Phonology: An Overview". Phonetica 49: 155-180.
Casagrande, Jean (1984): The Sound System of French. Washington, DC.
Chomsky, Noam/Halle, Morris (1968): The Sound Pattern of English. New York.
Clements, George N. (1985): "The geometry of phonological features". In: Ewen, C./Kaisse, E. (eds.): Phonological Yearbook. Cambridge (UK).
Dell, François (1995): "Consonant clusters and phonological syllables in French". Lingua 95: 5-26.
Dunn, M. (1993): The phonetics and phonology of geminate consonants: a production study. Doctoral Dissertation, Yale University.
Hirose, Hajime (1997): "Investigating the Physiology of Laryngeal Structures". In: Hardcastle, William/Laver, John (eds.)The Handbook of Phonetic Sciences. London: 116-135.
Kirchner, Robert (1998): An Effort-Based Approach to Consonant Lenition. Doctoral Dissertation, UCLA.
Kirchner, Robert (Forthcoming): "Phonological contrast and articulatory effort".
Ladefoged, Peter/Maddieson, Ian (1996): The Sounds of the World's Languages. London.
Lombardi, Linda (1994): Laryngeal Features and Laryngeal Neutralization. New York.
Lombardi, Linda (1995a): "Laryngeal features and privativity". The Linguistic Review 12: 35-59.
Lombardi, Linda (1995b): "Laryngeal Neutralization and Syllable Wellformedness". Natural Language and Linguistic Theory 13,1: 39-74.
Lombardi, Linda (1998): "Constraints versus representation: some questions from laryngeal phonology". University of Maryland Working Papers in Linguistics 7: 20-40.
Lombardi, Linda (1999): "Positional Faithfulness and Voicing Assimilation in Optimality Theory". Natural Language and Linguistic Theory 17,2: 267-302.
Lombardi, Linda (2001): "Why Place and Voice are different: Constraint-specific alternations in Optimality Theory". In: Lombardi, Linda (ed.): Segmental phonology in Optimality Thoery: Constraints and Representations. Cambridge (UK).
Maddieson, Ian (1997): "Phonetic Universals". In: Hardcastle. William/Laver, John (eds.): The Handbook of Phonetic Sciences. London: 619-639.
Martinet, André (1955): Economie des changements phonétiques. Berne.
McCarthy, John/Prince, Alan (1995): "Faithfulness and reduplicative identity". In: Beckman, Jill/Walsh Dickey, Laura/Urbanczyk, Suzanne (eds.): Papers in Optimality Theory. Amherst.
Ohala, John J. (1983): "The origin of sound patterns in vocal tract constraints". In: MacNeilage, Peter (ed.): The production of speech. New York: 189-216.
Ohala, John J. (1997): "The Relation between Phonetics and Phonology". In: Hardcastle, William/Laver, John (eds.): The Handbook of Phonetic Sciences. London: 674-694.
Passy, Paul (1891): Etude sur les changements phonétiques et leurs caractères généraux. Paris.
Prince, Alan/Smolensky, Paul (1993): "Optimality Theory: constraint interaction in generative grammar". ROA 537-0802.
Russell Webb, Eric (2002): The Relational /r/: Three Case Studies in Rhotic Integrity and Variation. Doctoral Dissertation, University of Texas at Austin.
Russell Webb, Eric MS: Lenition, elision, epenthesis and
the variable nature of French [].
Tranel, Bernard (1987): The Sounds of French. Cambridge (UK).
Stevens, Kenneth (1998): Acoustic Phonetics. Cambridge (MA).
Valdman, Albert (1976): Introduction to French Phonology and Morphology. Rowley (MA).
Walker, Douglas C. (2001): French Sound Structure. Calgary.
Walter, Henriette (1977): La phonologie du français. Paris.
Westbury, John R./Keating, Patricia (1986): "On the naturalness of stop consonant voicing". Journal of Linguistics 22: 145-166.
Wetzels, W. Leo/Mascaró, Joan (2001): "The typology of voicing and devoicing". Language 77,2: 207-244.
Zipf, George (1949): Human Behavior and the Principle of Least Effort. Cambridge (MA).