Techniques d'abréviation dans les webchats francophones
1 Introduction
La présente étude[1]
vise à une exploration des ressources
linguistiques utilisées et inventées par les individus pratiquant
les conversations écrites en temps réel sur le web dans le but
de raccourcir leurs messages. Ce qui caractérise la plupart des chats,
c'est l'extrême rapidité de la communication. Dans un salon (en
anglais: chatroom) où le nombre des participants actifs va au-delà
de cinq, l'important est que les correspondants comprennent et réagissent
vite pour ne pas perdre le fil de la conversation: dans les secondes qui suivent,
ils n'auront plus le message sous les yeux. Etant donné cette brièveté
de vie des énoncés, la rapidité de rédaction et
la concision sont essentielles: "More important in this regard however is the
fact that in order to keep up with the flow of conversation it is often necessary
to respond quickly and this means that unless one can type very rapidly, messages
must be kept short." (Werry 1996: 53). Même dans un salon qui ne comporte
que deux ou trois participants, où les messages défilent
donc moins rapidement, les chateurs éprouvent le besoin d'être
brefs et précis: personne n'aime attendre deux minutes pour avoir une
réponse de la part de son interlocuteur. L'idée est, dans les
deux cas, de dire un maximum en un minimum de temps. C'est pourquoi les chateurs
ont recours, pour diminuer le temps de production et de réception, à
des stratégies de raccourcissement de nature très diverse. Mon
analyse se concentrera sur le niveau morphologique.[2]
2 Définitions
J'emploie le terme d'abréviation en son sens large en
me référant au Dictionnaire de linguistique et des sciences
du langage selon lequel une abréviation est "Toute représentation
d'une unité ou d'une suite d'unités par une partie de cette unité
ou de cette suite d'unités" (Dubois et al. 1994: 1). Ainsi, je distingue
les types suivants:
2.1.1 Abréviations proprement dites
Je comprends par "abréviation proprement dite" la réduction
d'un mot à quelques lettres seulement de ce mot. Il ne s'agit donc que
de créations écrites, la forme abrégée ne se prononce
pas. On différencie
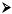 l'abréviation par
apocope
l'abréviation par
apocope
La réduction affecte la finale du mot, par exemple M. (Monsieur),
h (heure), chap. (chapitre), bull. (bulletin) etc. On met
un point abréviatif à l'exception des unités de mesure
(m, kWh) (Encyclopédie Hachette s.a., article abréviation).
l'abréviation par
syncope
L'abréviation s'effectue par la suppression de quelques
lettres à l'intérieur du mot, par exemple ds (dans), bd
(boulevard), grd (grand) etc. Dans ce cas-là, on ne met pas de
point abréviatif.
2.1.2 Mots tronqués
Le mot troncation est synonyme de réduction
et désigne le fait de créer un nouveau mot en supprimant un
ou plusieurs syllabes d'un mot existant (Encyclopédie Hachette s.a.,
article réduction).
À la différence des abréviations proprement
dites, les mots tronqués existent non seulement graphiquement, mais aussi
phonétiquement. On distingue
la troncation par apocope
Par analogie à l'abréviation par apocope, c'est
la partie finale du mot qui tombe: vélo (vélocipède),
ciné (cinéma)…
la troncation par aphérèse
Ce phénomène où l'on supprime la ou
les syllabe(s) initiale(s) d'un mot est beaucoup moins fréquent:
bus (autobus), stratif (administratif)…
2.1.3 Sigles
Un sigle est un mot qui se compose des lettres initiales d'un
groupe de mots. La prononciation est soit syllabique, soit alphabétique,
soit les deux. Si le sigle est prononcé comme un mot ordinaire (prononciation
syllabique), on l'appelle acronyme (Office de la langue française
2002, article acronyme). Ainsi, le terme CERN (Comité
Européen de la Recherche Nucléaire) est un
acronyme tandis que l'abréviation TGV (train à grande
vitesse) qui est prononcée lettre après lettre, est un
sigle au sens strict.
3 Présentation des corpus
Mon étude repose sur treize corpus enregistrés
dans trois webchats francophones. Le lecteur intéressé trouvera
en annexe une capture d'écran de ces chats. Au total, il s'agit de 3000
messages d'usagers. Afin de faciliter l'analyse, j'ai numéroté
les messages en commençant, dans chacun des treize corpus, par le numéro
1. J'attache une grande importance à l'illustration des caractéristiques
étudiées à l'aide d'exemples tirés de mes corpus.
Les chiffres arabes indiquent le numéro du message cité, les chiffres
romains celui du corpus dont il est tiré. L'énoncé suivant
par exemple fait partie du corpus III et il y correspond à la ligne
41:
| |
III |
41 |
Sims -> Salut à tous!! |
Par ailleurs, dans ce travail, les mots énoncé
et message seront employés comme synonymes. Il va sans dire que
les messages sont cités tels qu'ils étaient produits par leurs
émetteurs. Je n'ai changé ni le contenu, ni la mise en forme du
texte des messages, ce qui fait que certaines citations apparaissent en gras,
d'autres en italique etc. Parfois cependant, je me permets de mettre en relief
quelques éléments afin de mieux montrer les phénomènes
étudiés. Pour ce faire, je me sers du soulignement parce que ce
type de mise en texte n'est utilisé dans aucune des 3000 participations.
3.1 Choix des chats
Les conversations de mes corpus sont tirées des trois
chats suivants:
corpus I-III: Weborama (http://chat.weborama.fr)
corpus IV-X: Pause-Café (http://www.pause-cafe.net)
corpus XI-XIII: Multimania (http://chat.multimania.fr)
J'ai choisi ces chats parmi les milliers d'autres disponibles
sur le net
premièrement parce
qu'ils sont francophones. Malgré la croissance de pages web rédigées
dans une langue autre que l'anglais, toujours est-il que la majorité
des discussions en ligne se déroulent dans la langue de Shakespeare parce
qu'ils réunissent des chateurs des quatre bouts du monde. Mes trois chats
par contre qui sont hébergés sur un serveur français ou
canadien, ne sont pratiquement connus que dans le monde francophone. Il en résulte
que les conversations se déroulent quasi exclusivement en français
et que l'on a peu de risque que des non-francophones viennent s'y glisser. Ceci
représente un grand avantage pour tout linguiste visant à analyser
la langue française telle qu'elle est employée par les locuteurs
natifs.
deuxièmement parce
qu'ils sont gratuits et ouverts à tous les internautes
troisièmement parce
qu'il s'agit de chats généralistes et non-modérés.
Autrement dit, ils ne portent pas sur un sujet particulier et ils ne sont pas
caractérisés par la présence d'une personne qui dirige
la conversation et qui distribue les tours de parole (comme par exemple dans
un chat avec un homme politique ou dans un séminaire virtuel proposé
par une université).
et finalement parce que
les conversations sont faciles à enregistrer (ce qui n'est pas le cas
par exemple dans les chats basés sur le langage Java script).
3.2 Enregistrement des conversations
Au total, il s'agit de treize sessions dont les bornes sont
complètement arbitraires. Les conversations ont été coupées
dans le but d'obtenir 1000 messages d'usagers pour chacun des trois chats. En
ce qui concerne le corpus du chat de Weborama ainsi que de Multimania, il se
compose de trois sessions différentes. Etant donné le fait
que le chat de Pause-Café est beaucoup moins fréquenté,
j'ai augmenté le nombre de corpus à sept afin de recevoir
un maximum de chateurs différents.
Les conversations ont été enregistrées
dans des jours et des tranches horaires différents. Je suis toujours
entrée dans les chats sous le pseudonyme souris, à une
exception près (corpus II) où je me suis nommée jardin.
Je n'ai envoyé aucun message, ni au public ni en privé. Deux participants
m'ont adressé la parole. J'étais tentée de leur répondre,
mais j'ai décidé de rester silencieuse afin de ne pas trop influencer
la suite de la conversation.
Je n'étais pas connectée lors des conversations
des corpus IV-X parce que le chat de Pause-Café offre la possibilité
d'enregistrer tous les messages qui ont été affichés pendant
les 24 heures précédentes. L'aspect négatif en est que
cela concerne uniquement les participations des usagers, et non pas les messages
automatiques du système. On ne peut donc que supposer quand exactement
un utilisateur a rejoint ou quitté le salon. Les côtés positifs
sont l'absence d'un "voyeur" et la possibilité de recevoir ainsi des
corpus où deux personnes parlent à cœur ouvert sans être
"observées". La conversation entre Petit-Lion et Maryse (corpus IV) ainsi
que celle entre _Matrix_ et Lauriekkmin (corpus IX) en sont de bons exemples.
Je suis bien sûr consciente du côté moral de ce procédé,
mais je ne crois pas mépriser la vie privée d'autrui en enregistrant
et en analysant de tels échanges. D'une part parce que, de toute façon,
on a affaire à des anonymes dont on ne connaît que le pseudonyme.
D'autre part parce qu'il ne s'agit pas d'amoureux menant une conversation chaleureuse
en toute intimité mais tout simplement d'amis (virtuels) ou même
d'inconnus ne parlant que de choses anodines.
3.3 Weborama
Weborama est un annuaire de sites web qui offre des services pour webmestres
(un webmestre est une personne responsable d'un site web). Un de ces services
est la mise à disposition d'un chat, appelé aussi le Webochat.
Celui-ci est gratuit et ouvert à tout internaute, non seulement aux webmestres
abonnés à Weborama, parce qu'à l'aide de ce service, Weborama
gagne doublement: premièrement en termes de notoriété,
et deuxièmement en termes de satisfaction des webmestres abonnés.
On peut joindre le chat à partir de la page http://chat.weborama.fr
où il faut entrer un pseudonyme quelconque. Au cas où le surnom
choisi serait déjà en cours d'utilisation, l'accès au chat
est refusé et on doit essayer un autre pseudonyme, par exemple souris2
au lieu de souris. Le système n'accepte donc pas des clones (deux
utilisateurs ayant le même surnom lors d'une session). C'est celui qui
choisit le premier un pseudonyme qui en devient le possesseur. Il le conserve
tant qu'il reste connecté et le perd dès qu'il quitte le chat.
Notons de plus que ce surnom n'est pas protégé par un mot de passe,
c'est-à-dire toute autre personne peut choisir le même pseudonyme
si l'on n'est pas connecté en ce moment-là. Autrement dit, la
Julie avec laquelle on vient d'avoir une longue conversation aujourd'hui n'est
peut-être pas la même demain, d'autant moins que ce prénom
est très répandu.
3.4 Pause-Café
Ce chat est hébergé sur un serveur canadien,
et il est fort probable que la plupart des utilisateurs viennent du Canada.
À part le chat, un forum de discussion est offert.
Notons quatre différences principales par rapport au
chat Weborama:
le pseudonyme est protégé par un mot de
passe. Quand on visite pour la première fois la page www.pause-cafe.net,
il faut s'inscrire pour devenir membre de la communauté de Pause-Café.
On doit fournir son pseudonyme, nom, prénom, sexe et adresse électronique.
Petit détail en passant: ces indications peuvent fort bien inventées
- l'adresse email mise à part. Là, on a intérêt à
se tenir à la vérité puisque le mot de passe sera envoyé
par courrier électronique. L'enregistrement est alors accompli et dès
lors, il suffit d'entrer dans le chat en tapant son pseudonyme et le mot de
passe attribué par le système. Grâce à cette inscription
obligatoire qui est gratuite d'ailleurs, c'est toujours le même individu
qui se cache derrière un surnom car celui-ci lui est réservé.
il est affiché
l'heure à laquelle les messages ont été postés ainsi
que l'heure locale du serveur dans la barre des tâches tout en bas de
l'écran. Il s'agit de l'heure canadienne bien entendu.
ce chat offre le luxe
d'insérer des émoticons iconiques. Ainsi, le texte c'est pas
rigolo:( , envoyé par l'utilisateur souris, sera affiché automatiquement
de façon suivante (les premiers 6 chiffres indiquent l'heure du postage):
22:22:34 [souris] c'est pas rigolo 
on peut en outre choisir
la couleur dans laquelle seront affichés les messages et faire apparaître
le texte en gras, en italique ou souligné.
3.5 Multimania
Multimania est un site de communauté très connu
en France. Il propose à ses membres un bon nombre de services gratuits
tels que le courrier électronique ou l'hébergement de pages personnelles.
Pour accéder au chat, il n'est pas forcément nécessaire
de s'enregistrer. Certes, on peut devenir membre gratuitement en remplissant
le formulaire d'adhésion. Ainsi, le pseudonyme sera protégé
par un mot de passe. Mais on peut également se connecter en tant que
simple visiteur. Dans ce cas-là, on n'a pas la possibilité de
choisir un surnom. Celui-ci est attribué par le système. Par exemple,
si l'on est la trentième personne à se connecter de cette manière,
on recevra automatiquement le pseudonyme visiteur_30. On observe que
certains internautes choisissent parfois cette façon d'entrer dans le
chat tout en étant membre de Multimania. Je suppose qu'ils sont trop
paresseux d'entrer leur pseudonyme et leur mot de passe ou qu'ils préfèrent
être complètement anonyme tout simplement. Tel le chateur visiteur_3301
(corpus XII) qui a normalement le surnom balouf (dans la ligne 118
ci-dessous, il met ce pseudonyme entre parenthèses et il est tout de
suite reconnu par pulmah) ou visiteur_632 (corpus XI) qui est connu parmi les
habitués sous le nom argoat ou argo:
| |
XII |
118 |
<visiteur_3301>
pulm condoléances (balouf) |
| |
|
120 |
<pulmah>
merci
balouf |
| |
XI |
292 |
<visiteur_632> bonané
valy |
| |
|
295 |
<__Miss_Valy__>
bnn année 32 |
| |
|
300 |
<visiteur_632>
valy> tu peux me tutoyer
aussi hein:o) |
| |
|
303 |
<visiteur_632>
mais surtout appelle moi
argo:o) |
| |
|
305 |
<__Miss_Valy__>
oki argo je t avai pas reconnue |
Une autre particularité de Multimania est la présence
d'un opérateur. Il s'agit d'un chateur qui participe, comme tous les
autres utilisateurs, à la conversation en cours, mais qui est doté
de certains privilèges: au cas où un participant ne respecterait
pas la chatiquette, l'opérateur peut le bannir du salon. Le participant
en question sera automatiquement éjecté du chat et n'aura plus
le droit d'y entrer.
Voilà une brève présentation des trois
chats dont sont tirés mes corpus. Désormais, ils seront appelés
Webo, Pause et Multi.
4 Analyse des corpus
Je commence par esquisser un inventaire des procédés
de raccourcissement traditionnels présentés plus haut, à
savoir les abréviations proprement dites, la troncation ainsi que la
siglaison.
4.1 Abréviations
4.1.1 Abréviations proprement dites
Quant aux abréviations par apocope, elles ne sont pas
très nombreuses. Au total, j'en recueille dix. À quelques exceptions
près, elles ne sont employées que par un seul chateur:
|
abréviation
|
mot plein
|
occurrences
|
nombre de participants
utilisant cette abréviation
|
| h |
heure |
3 |
3 |
| h |
homme |
2 |
1 |
| m |
masculin |
3 |
2 |
| m |
mètres |
2 |
2 |
| f |
féminin/femme |
8 |
7 |
| f |
francs |
1 |
1 |
| ff |
francs français |
2 |
1 |
| min |
minutes |
3 |
3 |
| k |
kilogrammes |
1 |
1 |
| etc |
et cætera |
1 |
1 |
| °C |
degrés Celsius |
1 |
1 |
| km/h |
kilomètres par heure |
2 |
1 |
| Min |
Minimum |
1 |
1 |
| Max |
Maximum |
1 |
1 |
Ce qui frappe est que trois lettres représentent une
abréviation pour deux mots différents: h (heure/homme),
m (masculin/mètres) et f (féminin/francs). Mais
il faut dire que le contexte aide toujours à reconstituer le mot plein.
Ainsi, h (homme), m (masculin) et f (féminin/ femme)
figurent exclusivement dans les messages qui répondent à une demande
d'asv (âge, sexe, ville), et il est clair que le but
est de désigner le sexe du participant:
| |
I |
302 |
jojo -> ton asv lulu |
| |
|
317 |
lulu -> age 17 ans sexe f ville dunkerque |
| |
III |
482 |
Sims -> ok Nathalie asv please? |
| |
|
485 |
nathalie -> 26 f suisse |
| |
I |
232 |
Coronado -> 36m belgique |
Je ne trouve ni la forme Hme (homme) ni l'abréviation
Fme (femme) courantes dans les petites annonces, sans doute parce que
les lettres initiales sont suffisantes. On peut même dire que les lettres
h (homme), f (femme) et m (masculin) constituent en quelque
sorte des abréviations conventionnelles dans le cadre du chat.
Il est intéressant de noter que les trois dernières
abréviations figurant dans le tableau ci-dessus, à savoir km/h,
Max et Min, relèvent de l'écrit. Il s'agit de prévisions
météorologiques copiées d'une page web:
| |
IV |
169 |
[Petit-Lion]
Ce soir et cette nuit..Ennuagement ce soir suivi d'un peu
de neige débutant cette nuit. Min près de moins 6. Vents devenant
du nord-est de 10 à 20 km/h augmentant à 15 à 30 cette
nuit. |
| |
IV |
171 |
[Petit-Lion] Dimanche..Un
peu de neige cessant le matin. Dégagement par la suite. Max près
de 1. Vents du nord-est de 15 à 30 km/h tournant à l'ouest
en mi-journée. |
Alors que les abréviations par apocope tiennent une
place marginale, les abréviations par syncope sont plus nombreuses dans
mes corpus. Près de deux tiers des utilisateurs (65 %) ont recours à
une ou plusieurs abréviations de ce type. Quant aux formes, on constate
une variété étonnante, mais il est à souligner que
dans l'écrasante majorité des cas, il s'agit d'emplois individuels.
Autrement dit, on a affaire à des abréviations où se manifeste
l'usage particulier que des individus font du code graphique. Ainsi, Doc_Mabuse
est le seul à supprimer la voyelle e dans les articles les
et des, l'abréviation dc (donc) n'est utilisé
que par _Beuzbeuz_, ajd (aujourd'hui) ne figure que dans un message de
La_Fee_HaPercing et pts (points) est un hapax utilisé par
daking:
| |
XIII |
184 |
<Doc_Mabuse>
Tu dragues ls filles et après nous on t'drague !! |
| |
|
83 |
<Doc_Mabuse>
On aurait QUAND MEME pu lui rapporter ds croissants à la
Sab hein ! |
| |
XI |
499 |
<_Beuzbeuz_>
dc
je finis par... PRIEZ POUR MOI CETTE SEMAINE ET CE WEEK END !! svp |
| |
XI |
2 |
<visiteur_632> bon
am mat |
| |
XI |
138 |
<La_Fee_HaPercing>
meth<va
bien maxou il a repris les cours ajd |
Voici les abréviations par syncope employées
par au moins deux participants différents:
|
abréviation
|
mot plein
|
occurrences
|
nombre de participants
utilisant cette abréviation
|
| slt |
salut |
21 |
9 |
| ds |
dans |
7 |
5 |
| qd |
quand |
8 |
5 |
| tt |
tout |
9 |
5 |
| tjrs |
toujours |
6 |
4 |
| qqn, qqun, qq |
quelqu'un |
7 |
4 |
| pb |
problème |
6 |
4 |
| tps |
temps |
5 |
3 |
| we, wk |
week-end |
3 |
3 |
| pv |
privé |
3 |
3 |
| ms |
mais |
10 |
2 |
| bcp |
beaucoup |
2 |
2 |
| mtl |
Montréal |
3 |
2 |
| tte |
toute |
3 |
2 |
| p-etre |
peut-être |
2 |
2 |
| vla |
voilà |
2 |
2 |
| ps |
pas |
2 |
2 |
Comme le montrent ces quelques exemples, il s'agit avant tout
de ramener les mots à leur "squelette consonantique" (terme emprunté
à Anis 1999: 88). Ce procédé s'applique de préférence
à des mots monosyllabiques, mais on trouve également un bon nombre
de mots plurisyllabiques abrégés dans mes corpus. Curieusement,
ces charpentes (consonantiques) ne posent pas de problèmes d'interprétation,
tout au contraire, on peut les déchiffrer facilement. Cela tient au fait
que les consonnes attribuent plus à l'identification d'un mot que les
voyelles (cf. Anis 2001: 37). Les "squelettes" ci-après sont en effet
largement suffisants pour l'œil (les mots pleins sont ajoutés
à gauche):
problème/
longtemps |
XI |
351 |
<visiteur_632> beuz>
le pb, d'attendre trop lgtps, c ke ça laisse le tps de cogiter...pas
bon ça:o) |
| désolé |
XI |
72 |
<Nono_ptit_robot> argo>
dsl:( |
| pendant |
VII |
28 |
[liline]
Criquet> et toi, que vas-tu faire pdt les vacs? |
| bonjour |
XIII |
160 |
<visiteur_841>:o)>bjr
tlm |
Cette facilité de reconstitution est d'autant plus étonnante
que certaines formes peuvent correspondre à plusieurs lexèmes,
par exemple ss (suis / sais / sans / seins
/ sous…) ou tt (tout / tant
/ teint…) ou encore vs (vais / vas
/ vous / vis / viens…). Mais
dans ces cas-là, c'est surtout le contexte qui évite des interprétations
erronées. Dans les extraits ci-dessous par exemple, seuls les mots vas
(ligne 48), vous (ligne 327), tout (lignes 283, 47) et suis
(ligne 306) sont des reconstitutions possibles:
| |
X |
48 |
[nerka]
pat761> allo pat tu vs bien l,ami? |
| |
XI |
327 |
<__Miss_Valy__> bon
je vs laisse...bonne fin d aprém bizooooooooo(k) ;) |
| |
XII |
283 |
<visiteur_3386>
en fait lamadonne c mon
pseudo habituel mais j'ai été banie de ce canal, voila tt |
| |
VII |
47 |
[liline]
merci tt le monde, bye |
| |
XII |
306 |
<visiteur_3386>
je ss algerienne |
Mes corpus ne font apparaître qu'un seul exemple où
un interlocuteur a des problèmes de déchiffrement:
| |
II |
34 |
Silver ->
BN OK |
| |
|
35 |
JAK ->
BN ... les biscuits????????? |
| |
|
37 |
Silver ->
BN = BON |
| |
|
39 |
JAK ->
haaa ok |
4.1.2 Mots tronqués
La troncation est une ressource largement utilisée dans
les chats. Premièrement, elle est appliquée aux pseudonymes des
participants. Comme les chateurs ont intérêt à préciser
la personne à laquelle ils s'adressent pour faciliter la conversation,
on trouve un grand nombre de surnoms dans les messages. Si la personne à
qui l'on parle a un pseudonyme très long ou compliqué à
taper, celui-ci est très fréquemment abrégé. L'échantillon
ci-après par exemple montre que le surnom Akwakwak est particulièrement
gênant à taper, ce qui est indiqué par les points de suspension
en 174. D'où le mot tronqué akw en 178:
| |
II |
174 |
JAK -> @ + akwawa.... |
| |
|
178 |
Silver -> bye akw |
À part l'aspect pratique du raccourcissement, une motivation
de la troncation est celle d'obtenir des termes d'adresse plus amicaux
et conviviaux: beuz ou beuzy par exemple sont certainement plus
affectueux que Beuzbeuz. Il en va de même pour sil (Silver),
greg (Gregory), red (redbull), scan (Scandisk), nat
(nathalie), argo (argoat), top (topstar), pul (pulmah),
sem ou sema (semaphore), bal (balouf), dak (daking)
etc. On pourrait en multiplier les exemples. Comme on peut le voir, dans la
plupart des cas seules les premières trois ou quatre lettres du pseudonyme
complet sont gardées, ce qui correspond le plus souvent à la première
syllabe. On a donc affaire à des troncations par apocope.
Dans les corpus de Multi figurent également des troncations
par aphérèse, étant donné le fait que ce chat offre
la possibilité de se connecter en tant que visiteur. Les visiteurs se
distinguent entre eux par le numéro que le système leur a attribué
automatiquement lors de la connexion au salon. C'est précisément
ce numéro auquel on a recours pour s'adresser à un visiteur. N'étant
pas nécessaire pour l'identification, le mot visiteur est,
lui, supprimé:
| |
XII |
56 |
visiteur_3338
a rejoint le canal |
| |
|
59 |
<clownette2001>
lut et bienvenu 338 |
| |
XI |
222 |
<visiteur_632> chennevières |
| |
|
226 |
<Fred_au_taf>
632
t'habites chennevières??? |
En revanche, si les nombres sont précédés
d'un "vrai" pseudonyme, ils ne sont jamais mis puisqu'ils sont ressentis comme
fort redondants: jop ou jo (joplaya2000), clow, clown
ou clownette (clownette2001), cot ou cotcot (cotcot21)
etc.
Les troncations par syncope représentent une nouveauté
dans les chats. On en trouve deux dans mes corpus:
| |
II |
82 |
o10c -> je mettrai le tiens sur mon
site |
| |
|
84 |
Silver -> CE QUOI TON SITE 10 |
| |
XI |
204 |
<La_Fee_HaPercing> a
tte |
| |
|
208 |
<Nono_ptit_robot> fee
bye |
Dans les deux cas, ce sont les éléments les plus
significatifs et les plus courts qui sont retenus: le chiffre 10 dans
o10c et le mot fee dans La_Fee_HaPercing.
Les mots tronqués sont loin de se limiter aux surnoms.
Comme je l'ai déjà observé plus haut, ils n'existent, à
la différence des abréviations proprement dites, pas seulement
graphiquement. La stratégie de troncation est en effet très à
la mode à l'heure actuelle, surtout parmi les jeunes. Les troncations
envahissent le vocabulaire français, généralement en passant
de l'argot à la langue familière pour figurer finalement dans
les dictionnaires généraux. La langue parlée fourmille
de troncats, et cette tendance se manifeste dans les chats. Ainsi, mes corpus
contiennent un nombre non négligeable de mots tronqués. J'en relève
41 types différents dont les apocopes l'emportent largement. Curieusement,
seulement six d'entre eux sont dignes n'un article dans le Dictionnaire universel
francophone (Guillou 1999), à savoir météo (météorologique),
bac (baccalauréat), métro (métropolitain), maths
(mathématiques) et télé (télévision).
Pourtant, à quelques exceptions près (notamment les troncats qui
sont en rapport avec le chat comme par exemple webo (Weborama), multi
(Multimania), op (opérateur) et la formule re (retour)),
ils sont bien en usage dans la langue parlée, c'est-à-dire dans
les échanges en face-à-face. Il en témoigne le fait qu'ils
figurent majoritairement dans l'excellent Dictionnaire français-anglais
des mots tronqués (2000) de Fabrice Antoine (voir la bibliographie
en fin d'article). Cela montre qu'il ne s'agit pour la plupart pas de créations
spontanées de certains internautes puisque les termes sont déjà
attestés auparavant. Parmi les nombreux exemples de mes corpus on peut
citer pseudo (pseudonyme), pro (professionnel), aprèm
(après-midi), asso (association), démo (démonstration),
pub (publicité), ado (adolescent), champ (champagne),
fac (faculté), prof (professeur), info (information),
sympa (sympathique) etc. Par contre, certaines des aphérèses de
mes corpus dont je relève six, semblent bien être inventés
par les chateurs. Tandis que les abréviations blème (problème),
jour (bonjour), phone (téléphone) et lut
(salut) se rencontrent assez souvent, les créations vec (avec)
et core (encore) n'existent, à ma connaissance, pas dans la langue
orale.
Il est intéressant de noter qu'un troncat peut avoir
des nuances spécifiques que le mot plein ne possède pas. Ainsi,
les termes ordi (ordinateur), visi (visiteur) et multi
(Multimania) représentent des mots ayant une connotation extrêmement
positive. En revanche, les mots pleins ordinateur, visiteur et
Multimania n'ont pas cet effet. La voyelle finale i qui se trouve
d'ailleurs dans de nombreux mots du langage des enfants, renforce le caractère
affectueux. Le même phénomène est à observer dans
les exemples ci-dessous. Le mot accro (ligne 40) est beaucoup moins négatif
et brutal que son mot d'origine accroché où l'idée
d'une vraie dépendance (de drogues), donc d'une maladie, est encore bien
présente. Dans le message 421, le terme pseudonyme perd de sa
nuance de mot savant suite à l'élimination de son suffixe:
| |
VI |
34 |
[sas]
mamy> il y a deux heures, ils y avait des autos de polices et des ambulances
partout , ils on même fermé le métro, et moi qui avait
besoin de cigarettes on plus |
| |
|
40 |
[sas]
mamy> le pire c'est que j'ai marché deux kilométres pour
en acheter, un vrais accro, ton chum virtuel |
| |
I |
418 |
julie -> tu est blonde morgane |
| |
|
421 |
Morgan -> sans e mon pseudo |
Un bon nombre des mots tronqués de mon corpus représentent
des formations en -o (pseudo, pro, asso, démo, ado, info…).
Kilani-Schoch/Dressler qualifient le suffixe -o de "marqueur interactionnel"
(Kilani-Schoch/Dressler 1999: 55). Ainsi, l'utilisation de mots tronqués
crée un effet de confidentialité, de familiarité: "La
suffixation en -o introduit un rapport de proximité interpersonnelle
avec le ou les interlocuteurs ; elle définit un espace discursif
commun et exclusif au locuteur et à l'interlocuteur" (Kilani-Schoch/Dressler 1999:
55).
4.1.3 Sigles et acronymes
Dans mes corpus, la siglaison et l'acronymie se limitent à
quelques expressions qui sont en revanche fréquemment utilisées.
Notons tout d'abord des sigles traditionnels comme svp (s'il vous plaît,
5 occurrences) et stp (s'il te plaît, 14 occurrences). Des abréviations
propres au chat sont mdr (mort de rire, 50 occurrences) et lol
(laughing out loud, 136 occurrences) pour manifester le rire (j'ai également
compté les variantes mdrrr, lollll etc. dans lesquelles
les lettres r et l sont multipliées pour exprimer
la force du rire). Ces deux sigles sont employés de façon très
inégale dans mes corpus. Sur Webo et Multi, ils jouissent d'une popularité
énorme, alors que sur Pause, leur nombre est extrêmement restreint
(3 occurrences de lol etc., 11 occurrences de mdr etc.). Cela
s'explique sans doute par le fait que ce dernier chat offre la possibilité
d'insérer des émoticons iconiques. Ce qui est transmis sur Pause
par le biais du smiley souriant ainsi que des interjections comme haha
et hihi (ligne 79), est exprimé sur Webo et Multi par les sigles
lol et mdr:
| |
VI |
79 |
[Matrix]
hahhah sas  |
| |
XIII |
197 |
<maya>
on peut draguer? aaahh mais fallait le dire! |
| |
|
203 |
<_pestouille_>
maya heu.... toi chais
pas si ça en vaut la peine mdr |
| |
|
210 |
<maya>
ben c gentil ca pestou...pppffff |
| |
|
215 |
<_pestouille_>
maya c'est ma gentillesse
naturel lol |
| |
III |
162 |
marco ->
bon si personne me parle je vais me metre a chanter et je chante faut |
| |
|
184 |
Sims ->
Marco le samedi pas de fausses notes merci |
| |
|
186 |
marco ->
lollllllll |
| |
|
191 |
Gwen ->
mdr sims |
En général, les sigles mdr et lol
ont donc les mêmes fonctions que l'émoticon:), et ils ne
sont pas intégrés à la syntaxe des messages. Cependant,
les corpus font apparaître deux emplois singuliers de mdr, une
fois en tant que verbe (ligne 134 ci-dessous), et une autre fois comme adjectif,
synonyme de drôle, rigolo:
| |
VI |
134 |
[mamy]
sas> Matrix arreter de mdr tous les deux vais avoir mauvaise
conscience moi apres |
| |
II |
146 |
Akwakwak -> pas mdr du tout
..... |
J'étais curieuse de savoir si les chateurs francophones
préfèrent le sigle français mdr ou s'ils ont plutôt
recours à lol, son équivalent anglais, et si l'emploi de
l'un ou de l'autre est conditionné par la conversation en cours. Voici
les résultats de mes analyses:[3]
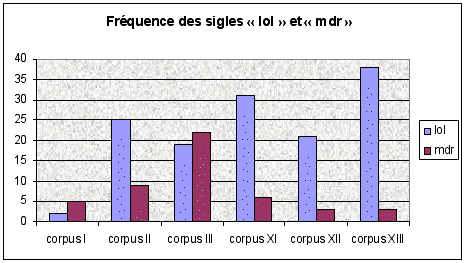 Figure 1
Figure 1
Le graphique (Figure 1) montre qu'à l'exception des
corpus I et III, l'acronyme lol batte tous les records. Cela tient
probablement au fait qu'il est beaucoup plus facile à taper: les lettres
o et l se trouvent tout près sur le clavier (voir
annexe 4) et on peut les frapper, si l'on maîtrise le système à
dix doigts, avec le même doigt, à savoir l'annulaire de la main
droite. Je ne crois pas que l'on ait affaire à une préférence
pour l'anglais. Dans la littérature on lit souvent que les chats non-anglophones
contiennent des sigles anglais tels que IMHO (In My Humble Opinion),
BTW (By The Way), ROTFL (Rolling On The Floor Laughing), BRB
(Be Right Back), THX (thanks) etc. (p.ex. Haase et al. 1997: 71, Wilde
2002: 15s., Bader 2002: 83, Anis 2001: 33-35). Mes corpus ne contiennent
aucun de ces exemples, le sigle lol étant la seule abréviation
de la langue de Shakespeare.
Un autre sigle propre aux chats et fréquemment utilisé
est asv (âge, sexe, ville), une expression qui est, certes, un
peu brute et laconique, mais qui permet aux chateurs de trouver le bon interlocuteur.
Comme les participants ne se voient pas et ne se connaissent en général
pas, on peut bien comprendre qu'ils aimeraient savoir à qui ils ont affaire.
Dans l'extrait suivant par exemple, la prise de contact entre Labelle et Coronado
échoue. À partir de la ligne 232, les deux Belges ne se parlent
plus, sans doute faute d'affinités (enfin, Coronado a plus du double
de l'âge de la fille). Sims par contre semble être bien contente
de son interlocuteur JULIEN. Elle fait avancer la conversation:
| |
I |
228 |
Coronado -> asv, labelle ? |
| |
|
230 |
Labelle -> 15 f belgique et toi |
| |
|
232 |
Coronado -> 36m belgique |
| |
III |
100 |
Sims -> ASV Julien please |
| |
|
103 |
JULIEN -> 27 M PARIS |
| |
|
114 |
Sims -> Ok merci ,que fais tu dans
la capitale? |
Le dernier sigle qui sera mentionné ici est tlm
(tout le monde, 27 occurrences) qui est employé presque exclusivement
dans les salutations d'ouverture ou de clôture pour s'adresser à
l'ensemble des participants:
| |
XIII |
7 |
<maya>
bonjour tlm!!! |
| |
I |
349 |
rox_rox -> Coucou tlm! |
| |
II |
172 |
Akwakwak -> bye tlm ! |
4.2 Logogrammes
Un tout autre procédé pour rendre plus court
un énoncé consiste à utiliser des logogrammes, c'est-à-dire
des "graphèmes qui correspondent directement à des morphèmes"
(Anis 1999: 77). Il s'agit donc de remplacer des unités lexicales par
des symboles. Ainsi, je trouve dans mes corpus les trois logogrammes +
(plus), - (moins) et 1 (un). Quant au premier, il est inséré
dans 24 messages envoyés par 20 utilisateurs différents. Il apparaît
le plus souvent dans la formule familière à plus (plus
court pour à plus tard) qui accompagne en général
une salutation de clôture:
| |
IV |
257 |
[chrisfo]
je vais me coucher je te dis bye et a+ |
| |
I |
377 |
Labelle -> bon ben @+ |
| |
XI |
148 |
<visiteur_649> bye
mac @++++ |
| |
VII |
44 |
[Criquet]
liline> @ ++++++++++ |
Par ailleurs, les trois derniers exemples font apparaître
un usage particulier du signe arobas qui sert normalement de séparateur
dans une adresse électronique. Il est utilisé dans les chats comme
variante des graphèmes à et a, sans doute pour obtenir
des effets stylistiques.
Mais retournons au signe + dont je relève d'autres
emplois. Dans la ligne 502 ci-après, il fonctionne comme comparatif et
dans 241 comme adverbe de négation. En 243, il fait partie de la locution
en plus et en 359 finalement il transcrit le nom propre Canal Plus,
une chaîne de télévision française:
| |
III |
502 |
virus -> BON MOI JE SUIS + JEUNE QUE
TOI |
| |
XII |
241 |
<semaphore>
bal moi non + c'est rare que je viens encore |
| |
XI |
243 |
<Mossieur_Yo> en
+ j'ai pas mon bon compte |
| |
III |
359 |
Scandisk -> UN CELIBATAIRE APARIS
LE SAMEDI IL MATE CANAL+ |
Voici un joli exemple qui me rappelle mes prises de notes dans
les cours mathématiques:
| |
VII |
7 |
[liline]
windex> ben tiens, je suis hypèr-fatiguée moi, l'alcohol+fatigue=
dodo  ou
alors complètement saoule (moi c'est plutôt dodo pour le
moment) ou
alors complètement saoule (moi c'est plutôt dodo pour le
moment) |
Ce message qui est particulièrement intéressant
a retiré toute mon attention. Le signe d'égalité ne correspondant
plus à une unité lexicale précise, on a affaire ici à
une écriture entièrement dissociée de toute parole, à
savoir l'écriture mathématique. L'activité de compréhension
se fonde sur la seule lecture des signes. Autrement dit, l'énoncé
ne sera pas oralisé par alcool plus fatigue font dodo
ou quelque chose de ce genre. C'est par simple interprétation du signe
plus et du signe d'égalité (et en s'appuyant sur le contexte bien
entendu) que l'on peut donner un sens à l'équitation l'alcohol+fatigue=
dodo. On reconstituera par exemple Si l'on boit de l'alcool et que l'on
devient fatigué, on a envie de retrouver son lit.
Le deuxième logogramme utilisé dans mes corpus
est le signe - (moins), employé dans l'exemple suivant pour
indiquer que les nombres ont une valeur négative. Notons qu'il s'agit
d'un hapax:
| |
VI |
18 |
[mamy]
Matrix> chez nous il y a eu -7 et dans l est de france -13 |
Le chiffre 1 pour transcrire le mot un peut également
être considéré comme logogramme. Dans mes corpus, la chateuse
Sims semble en être une adepte, d'autres participants ne l'utilisent qu'une
seule fois:
| |
III |
280 |
Sims -> Pour 1 gde journee c est une
gde journee car pour reunir 60000 enfts c'est du boulot!!! |
| |
III |
329 |
Sims -> Tu as 1 copine? |
| |
III |
347 |
Sims -> Q fais un celibataire à
Paris 1 samedi soir |
| |
III |
393 |
A -> qq1 a vu aurel |
| |
XI |
532 |
<austinne> salut
qq1 du 89 ? |
| |
I |
284 |
fifi -> t'as 1 copine jojo |
4.3 Variantes graphiques innovatrices
J'appelle ainsi les écarts de la norme orthographique.
Le phénomène le plus évident est sans doute la réduction
de qu à la lettre k. Il s'agit d'une stratégie très
répandue dans mes corpus, elle est employée par 23 participants
différents.
Mes statistiques confirment la tendance observée par
Anis (2001: 31) selon laquelle le procédé s'applique avant tout
aux mots relatifs et interrogatifs (Figure 2). À noter que la forme
kan (quand) fait en outre apparaître un autre procédé
de simplification, à savoir la disparition de lettres muettes dont j'aurai
l'occasion de parler plus loin.
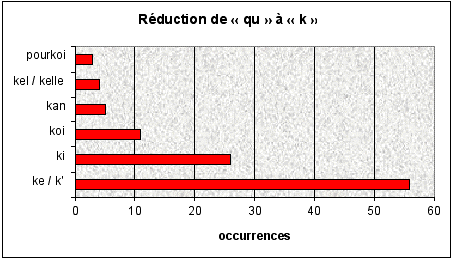 Figure 2
Figure 2
Rares sont les cas où la réduction touche des
mots non-grammaticaux. Je n'en trouve que quatre:
| |
XIII |
198 |
<Doc_Mabuse>
J't'esplikerai ! |
| |
XI |
126 |
<visiteur_624>
Nhappie>scuses
appel telephonik en mm tps |
| |
XI |
279 |
<visiteur_632> beuz>
ben justement, en parlant de ça...j'en manke cruellement
là:o)) |
| |
XI |
345 |
<visiteur_632> tourtou>
ça y est ? t stabilisé ? gaffe, tu riskes de ne pas
le rester lgtps si tu t'égosilles de la sorte |
Deux utilisateurs seulement remplacent le mot que par q,
et un participant tape k au lieu de c (ce qui ne présente
rien d'abréviatif bien entendu, mais ce qui crée un effet stylistique):
| |
III |
175 |
Sims -> Il parrait q le match n'a
duré q 12 mns vrai? |
| |
XIII |
70 |
<teenybee>
bon allez faut q je trouve
un POT de NUTELLA !!! |
| |
III |
304 |
Sims -> Ici le tps est bizarre il
fait lourd et je crois q ca va craquer |
| |
XI |
486 |
<visiteur_632> ah
oui kom moi beuzz:o) |
Ce dernier exemple témoigne, lui aussi, de l'omission
de lettres muettes mentionnée plus haut.
Ce procédé a ses origines dans la forte redondance
du code graphique. Pourquoi taper des lettres, si l'on ne les prononce pas ?
- C'est sans doute ce que se demande un bon nombre de chateurs. Il n'est pas
facile de savoir si les graphies suivantes sont dues à une dysorthographie
de la part des émetteurs ou si elles constituent plutôt des écarts
de la norme voulus. Soyons optimistes et supposons qu'elles ont été
produites bien consciemment pour des raisons économiques ou ludiques (la
forme "correcte" est ajoutée à gauche):
| pas |
XI |
108 |
<La_Fee_HaPercing>
et
je regrette pa |
| avais |
XI |
305 |
<__Miss_Valy__> oki
argo je t avai pas reconnue |
| trop |
XI |
431 |
<La_Fee_HaPercing> je
suis tro forte |
| as / nouvelles |
XI |
74 |
<Nono_ptit_robot> argo>
mais t'a po de nouvelle toa?? |
| as |
XII |
276 |
<visiteur_3386>
oui tu l'a trouvé
sema!!lol |
On appelle digramme un groupe de deux lettres correspondant
à un phonème unique (Dubois et al. 1994: 148). Nous avons déjà
vu que les chateurs mettent fin à cette faiblesse du code graphique (l'idéal
graphique est qu'un phonème est représenté par un seul
graphème) en remplaçant le groupe qu par la lettre k.
Le même procédé est appliqué au digramme au
qui représente le phonème [o]:
| |
XI |
421 |
<visiteur_632> beuz>
on la connait l'otre ? |
| |
III |
38 |
Gwen -> mais fo ke t'enchaines |
| |
XIII |
80 |
<maya>
ben non, j'ai un peu disparu là c'est vrai, fo s'y remettre! |
Parfois il s'agit aussi de l'o ouvert:
| |
XIII |
108 |
<ninjah_rastafari>
cot>é bien ça ma mis de movéze humeur |
Cet exemple me conduit à mentionner une autre stratégie
simplifiante qui consiste à utiliser le graphème é
pour les groupes de lettres correspondant au e ouvert ou au e
fermé. Dans les messages suivants, é remplace les graphies
ait (lignes 95, 157, 466), ais (90), ez (203), et
(60), ainsi que le mot es (246):
| fait |
XI |
95 |
<daking>
fé
pas mal? |
| fait |
XI |
157 |
<La_Fee_HaPercing>
meth<c
fé mal ms je m'en souviens deja plus |
| faudrait |
XI |
466 |
<visiteur_632> fodré
ke je bossasse un poil.... |
| t'avais |
XIII |
90 |
<ninjah_rastafari>
cot>c paske t ici ke
tavé pa le temp de me dire juste bonjour blabla? |
| allez |
XI |
203 |
<La_Fee_HaPercing>
bon
allé |
| et |
XIII |
60 |
<ninjah_rastafari>
ootie>oui bien bien
é toi |
| t'es |
VII |
246 |
[NevaRa]
j en sais rien..........té
qui |
Celui qui participe pour la première fois à une
discussion virtuelle est peut-être surpris voire choqué de voir
s'afficher sur son écran des énoncés tels que les suivants:
| |
XI |
136 |
<daking> c
cool |
| |
XIII |
88 |
<maya>
croissants? g bien entendu? |
| |
XIII |
252 |
<Maskou>
merlin t pas sérieux
..;-) |
Les citations montrent que l'on profite de l'homophonie avec
le nom des trois lettres c, g et t pour créer une
graphie beaucoup plus courte de c'est, j'ai et t'es. Il
s'agit de syllabogrammes (Anis 1999: 88), chaque lettre représentant
une syllabe homophone. Les chateurs adorent parsemer leurs messages de telles
créations remplaçant plusieurs lettres voire un ou plusieurs mots
ayant la même sonorité. Elles réduisent considérablement
la frappe au clavier et permettent accessoirement de passer pour un véritable
initié. À souligner que le phénomène concerne
surtout les mots courts et fréquents, plus précisément
les verbes. En effet, mes corpus ne contiennent qu'un message dans lequel le
procédé ne touche pas un verbe:
| bébé |
XII |
196 |
<may__>
moi je dors comme un bb |
Les trois syllabogrammes mentionnés plus haut sont les
plus fréquents. Celui qui figure en tête de mes statistiques est
c (c'est) qui est employé à bout de souffle (140
occurrences, utilisé par 37 participants). La lettre g (j'ai)
arrive en deuxième position (15 occurrences, 7 participants) et t
(t'es) se hisse au troisième rang (9 occurrences, 7 participants).
On trouve parfois, mais pas très souvent, des combinaisons
entre ces trois graphèmes pour mettre les verbes à l'imparfait.
Tels ct (c'était), gt (j'étais) et tt (t'étais):
| |
XIII |
224 |
<pulmah> pestouille la dernière
fois que je l'ai vue ct le jour de l'enterrement de papa |
| |
XI |
330 |
<visiteur_632> beuz>
huuuuu ??? je croyais ke c t fait ça !!!:o) |
| |
XIII |
250 |
<merlinlesupermag>
g fait un reve...gt
capricorne,toi, tt une biche et on faisait l amour ds la foret... |
| |
III |
27 |
Kurt -> t t
ou? |
Un autre syllabogramme représente v (vais). Notons
que la prononciation de celui-ci, qui exige un e ouvert, ne correspond
plus exactement au nom de la lettre v qui est [ve]. Ce syllabogramme
est marginal, il ne figure que dans trois messages (dans la ligne 253,
le mot à reconstituer est avait):
| |
XI |
189 |
<La_Fee_HaPercing>
bon v preparer a manger pour ce soir |
| |
XI |
229 |
<visiteur_632>
fred>
non j'v à la fac la bas |
| |
XI |
253 |
<visiteur_632> moi
non plus suis pas du coin...pensais pas k'il y av des fac aussi
pourries à paris... |
Les exemples suivants sont également très rares:
| était |
III |
17 |
nani ->
il ét |
| elle est |
XI |
374 |
<visiteur_632>
ah
non, c vrai lé pas breizhoo...elle voyage bcp |
| elle est |
XII |
106 |
<_helmer_>
lépartie |
Reste la question de savoir à quel point une graphie
contenant de tels éléments reste transparente. Un grand inconvénient
en est en effet que la simple lecture des lettres n'est pas suffisante. On doit
toujours passer par l'oralisation pour pouvoir comprendre les syllabogrammes.
La chose se complique quand un seul graphème est utilisé pour
plusieurs phonèmes. Dans les deux messages suivants (par exemple lignes
510 et 73), c ne correspond pas à c'est (voyelle fermée),
mais à sais (voyelle ouverte):
| |
XI |
510 |
<La_Fee_HaPercing> argo<bah
vi ki c ton année cT peut etre 2001? nan?:op |
| |
II |
71 |
Silver -> TA PAGE EST TROP LONGUE |
| |
|
73 |
JAK -> je c silver je suis
obliger |
Il est important de noter que l'usage des syllabogrammes est
très différent dans les trois chats. Sur Pause par exemple, seuls
deux participants actifs pratiquent ce procédé alors que sur Multi,
le nombre s'élève à 72 %:
| |
Webo |
Pause |
Multi |
| nombre des participants actifs utilisant des syllabogrammes
(en %) |
12 (48 %) |
2 (12,5 %) |
18 (72 %) |
Le graphique suivant (Figure 3) qui compare la fréquence
du syllabogramme c et celle du mot c'est dans sa graphie traditionnelle,
illustre de façon encore plus prononcée les grands écarts
dans les trois chats:
 Figure 3
Figure 3
On voit bien que le chat de Pause-Café est celui avec
le moins de syllabogrammes. Notons au passage que l'on remarque le même
phénomène au niveau d'autres graphies innovatrices que je viens
de présenter. Des créations telles que fot (faut)
ou ki (qui) etc., tellement fréquentes sur Multi, sont largement
sous-représentées sur Pause. Une explication possible s'inscrit
dans la dynamique de groupe qui est certainement moins forte sur Pause où
l'on a souvent affaire à des conversations entre deux ou trois personnes
seulement. Les utilisateurs n'ont pas besoin de frapper, d'être original
pour se distinguer des autres et pour pouvoir faire partie du groupe. Les chateurs
sur Webo et particulièrement sur Multi par contre ont continûment
intérêt à se faire remarquer. On a affaire à un langage
de connivence, les utilisateurs cherchent à créer des effets,
à coder au maximum pour être membre du groupe, pour faire partie
de l'élite. De ce point de vue, la motivation des graphies innovatrices
n'est donc pas l'économie, mais une certaine recherche d'originalité.
En effet, mes corpus comportent un grand nombre de graphies qui ne présentent
rien d'abréviatif:
| soir |
III |
370 |
Scandisk -> A CE SOAR PEUT
ETRE |
| poil |
XII |
231 |
<visiteur_3301>
vi je me sens mieux à
pwal |
| |
XII |
228 |
<semaphore>
ah lut bal comment vas tu ? |
| toi |
|
229 |
<visiteur_3301>
sem bien bien et touaaaaaaaaa? |
| moi |
XI |
432 |
<La_Fee_HaPercing> je
suis une fée MOAAAAAAAAAAAAAAAA |
Dans ces exemples qui constituent en gros des variantes graphiques
du digramme oi, c'est donc la fonction émotive qui prime, ce qui
est renforcé en 229 et en 432 par l'itération de lettres.
5 Conclusion
Les conditions d'énonciation spécifiques de la
conversation en temps réel sur l'internet ont une influence énorme
sur les pratiques linguistiques et communicationnelles. Le temps presse dans
les chats. Plus le nombre de participants actifs est élevé, plus
le défilement des messages est vite. Ainsi, les chateurs se voient confrontés
au souci suivant: comment produire un message le plus rapidement possible? Afin
de résoudre ce problème, ils ont multiplié les stratégies
de raccourcissement qui permettent de dire un maximum en un minimum de caractères
ASCII. L'emploi de mots tronqués, sigles, acronymes, logogrammes et graphies
innovatrices de toute sorte (fo, c, ki …) réduit
considérablement la frappe au clavier. La plupart de ces procédés
demandent en outre moins d'effort au lecteur, les nouvelles formes étant
plus concises et facilitant énormément la réception. Mais
cette recherche d'économie est loin de tout expliquer. On trouve aussi
des graphies qui ne représentent rien d'abréviatif du tout. Si
les chateurs s'écartent volontiers de la norme, c'est aussi pour impressionner,
pour se faire remarquer. Plus on fait preuve d'inventivité, plus on est
considéré comme "maître" de bavardage. Il s'agit d'élaborer
des codes spécifiques pour initiés, et l'utilisation de ces codes
contribue à l'établissement d'une sorte de familiarité
et de confidentialité. Le chat créé ainsi un sentiment
d'appartenance communautaire parmi ses utilisateurs, en particulier parmi ses
habitués. Pour faire partie du groupe, pour pouvoir participer de façon
compétente à la conversation, il faut utiliser ces codes. À
ne pas oublier la dimension ludique bien entendu. "@ + tt le monde !" -
Malherbe se retournerait dans sa tombe. Il est difficile de dire à quel
point les nouvelles technologies et, avec elles, les nouveaux modes de communication
sont susceptibles de provoquer des phénomènes d'évolution
linguistique - nous verrons ce que l'avenir nous apportera.
Notes
1 Mes remerciements les plus chaleureux vont à Madame Marianne Kilani-Schoch
ainsi qu'à Monsieur Jean-Michel Adam, professeurs à l'Université
de Lausanne grâce auxquels j'ai pu passer une année d'études
fructueuse et riche en expériences en Suisse romande. J'inclus dans ma
gratitude les responsables de la Commission fédérale des bourses
pour étudiants étrangers pour m'avoir accordée une bourse
de la Confédération. [back]
2 Pour ce qui est de l'allemand, ma langue maternelle, il existe un bon nombre
d'études à ce sujet, p.ex. Haase et al. 1997, Naumann 1997 (une
étude sur l'IRC), Runkehl/Schlobinski/Siever 1998, Storrer 2001, Wilde
2002, Bader 2002 pour ne pas oublier Schlobinski et al. 2001 (ce
dernier représente une analyse détaillée des messages écrits
envoyés par téléphone portable). Comme les publications
concernant les webchats francophones sont beaucoup moins nombreuses (un des
rares linguistes à avoir étudié en détail le phénomène
est Jacques Anis, professeur à Nanterre et spécialiste du langage
sur l'internet, voir bibliographie), j'ai décidé de me limiter
à la langue de Molière. [back]
3 J'ai uniquement pris en compte les conversations de Webo (I-III) et Multi
(XI-XIII), vu la basse fréquence des sigles mdr et lol
sur Pause. [back]
Références
Anis, Jacques (1998): Texte et ordinateur. L'écriture
réinventée? Bruxelles.
Anis, Jacques (sous la direction de) (1999): Internet, communication
et langue française. Paris.
Anis, Jacques (2001): Parlez-vous texto? Guide des nouveaux
langages du réseau. Paris.
Antoine, Fabrice (2000): Dictionnaire français-anglais
des mots tronqués. Louvain-la-Neuve.
Bader, Jennifer (2002): Schriftlichkeit und Mündlichkeit in der Chat-Kommunikation.
[En ligne]. Page consultée le 15 avril 2003. Accès: http://www.mediensprache.net/networx/networx-29.pdf
Dubois, Jean et al. (1994): Dictionnaire de linguistique
et des sciences du langage. Paris.
Encyclopédie Hachette (s.a.): Encyclopédie. [En ligne].
Page consultée le 30 août 2002. Accès: http://www.encyclopedie-hachette.com/W3E
Guillou, Michel (sous la direction de) (1999): Dictionnaire
universel francophone. 2e éd. Paris.
Haase, Martin et al. (1997): "Internetkommunikation und Sprachwandel". In:
Weingarten, Rüdiger (éd.) (1997): Sprachwandel durch Computer.
Opladen: 51-85.
Kilani-Schoch, Marianne/Dressler, Wolfgang U. (1999): "Perspective
morphopragmatique sur les formations en -o du français branché".
In: Mel'cuk, Igor et al. (1999): DEC. Dictionnaire explicatif et combinatoire
du français contemporain. Recherches lexico-sémantiques IV.
Montréal: 55-66.
Naumann, Bernd (1997): "IRCs - schriftliche Sonderformen von
Mehrpersonengesprächen". In: Weigand, Edda (éd.) (1997): Dialogue
Analysis: Units, relations, and strategies beyond the sentence. Contributions
in honour of Sorin Stati's 65th birthday. Tübingen: 161-178.
Office de la langue française (2002): Le grand dictionnaire terminologique.
Version 1.2.2. [En ligne]. Juin 2002 (date de révision). Page consultée
le 3 juin 2002. Accès:
http://www.granddictionnaire.com/_fs_global_01.htm
Runkehl, Jens/Schlobinski, Peter/Siever, Torsten (1998): Sprache
und Kommunikation im Internet: Überblick und Analysen. Opladen/Wiesbaden.
Schlobinski, Peter et al. (2001): Simsen. Eine Pilotstudie zu sprachlichen
und kommunikativen Aspekten in der SMS-Kommunikation. [En ligne]. Page consultée
le 2 janvier 2003. Accès: http://www.websprache.net/networx/docs/networx-22.pdf
Storrer, Angelika (2001): "Getippte Gespräche oder dialogische
Texte? Zur kommunikations-theoretischen Einordnung der Chat-Kommunikation".
In: Lehr, Andrea et al. (éds.) (2001): Sprache im Alltag. Beiträge
zu neuen Perspektiven in der Linguistik. Herbert Ernst Wiegand zum 65. Geburtstag
gewidmet. Berlin: 439-465.
Werry, Christopher C. (1996): "Linguistic and Interactional Features of Internet
Relay Chat". In: Herring, Susan C. (éd.) (1996): Computer-Mediated
Communication. Linguistic, Social and Cross-Cultural Perspectives. Amsterdam:
47-63.
Wilde, Eva (2002): Zwischen Mündlichkeit und Schriftlichkeit: Die
Chat-Kommunikation aus linguistischer Sicht. Seminararbeit. Universität
Bern, Institut für Germanistik. [En ligne]. Page consultée le
15 avril 2003. Accès:
http://www.hrz.uni-dortmund.de/~hytex/chatbib/papers/wilde.pdf